相关历史及分成模型
历史介绍
- 1969年 美国担心敌人会摧毁自己的网络,所以国防部高级研究计划局(Advanced Research Projects Agency,ARPA)下决心要建立一个高可用的网络,即使部分线路或者交换机的故障不会导致整个网络的瘫痪,于是有了后来的ARPANET(Advanced Research Project Agency Network)—最早只是一个简单的分组交换网
- 经过不断发展,原始的ARPANET慢慢变成了多个网络互联,逐步促成了互联网的出现。
- 1983年TCP/IP 协议成为 ARPANET 上的标准协议,现在互联网世界这么繁荣都得意与TCP/IP协议,当然任何一个行业越是繁荣昌盛,就越是有良好的协议标准,接口标准,TCP/IP就是网际互联中最流行的协议标准,也正是因为其流行,互联网才能越发发达。
分层模型
- 一般都会提到7层 4层 或者 5层,下面给出一张图做个简单对比
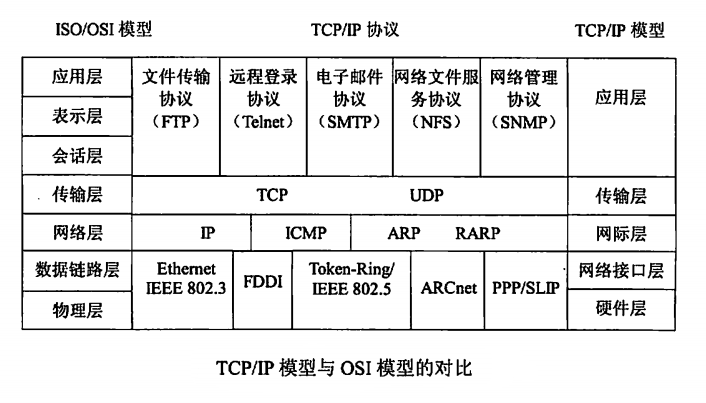
左边是ISO/OSI的7层模型,分的更细,一般我们常说的右边的4层,咱们从上到下分层说
应用层 Application Layer
应用层的本质是规定了应用程序之间如何相互传递报文,处理特定的应用程序细节
我们常说的FTP、HTTP、SMTP、NFS、SNMP、Telnet都是应用层的协议,就拿HTTP来说:
- 规定了报文的类型 是请求报文还是应答报文
- 每段报文具体什么语法 有多少段,怎么才算结束(\r\n)
- 进程应该以什么样的顺序发送或者接收报文
- ……….
大部分应用层协议都有RFC文档定义(Request for Comments,缩写:RFC,由互联网工程任务组(IETF)发布的一系列备忘录。文件收集了有关互联网相关信息,以及UNIX和互联网社群的软件文件,以编号排定。目前RFC文件是由互联网协会(ISOC)赞助发行)
传输层 Transport Layer
主要为两台主机上的应用程序提供端到端的通信。在TCP/IP协议族中,有两个互不相同的传输协议:TCP(传输控制协议)和UDP(用户数据报协议)。
TCP为两台主机提供高可靠性的数据通信。它所做的工作包括把应用程序交给它的数据分成合适的小块交给下面的网络层,确认接收到的分组,设置发送最后确认分组的超时时钟等。
由于传输层TCP提供了高可靠性的端到端的通信,因此应用层可以忽略所有这些细节。为了提供可靠的服务,TCP采用了超时重传、发送和接收端到端的确认分组等机制。
UDP则为应用层提供一种非常简单的服务。它只是把称作数据报的分组从一台主机发送到另一台主机,但并不保证该数据报能到达另一端。一个数据报是指从发送方传输到接收方的一个信息单元(例如,发送方指定的一定字节数的信息)。UDP协议任何必需的可靠性必须由应用层来提供。
- 端口
- 这里必须提下端口的概念,主要为了区分一台主机上不同的应用程序,比如80端口一般就是http应用的端口,21一般是ftp应用的端口,知道了端口就知道数据包到时候要送给哪个应用程序
网络层/网际层/网络互联层 Internet Layer
网络互连层提供了主机到主机的通信,将传输层产生的的数据包封装成分组数据包发送到目标主机,并提供路由选择的能力。
处理分组在网络中的活动,例如分组的选路。
在TCP/IP协议族中,网络层协议包括IP协议(网际协议),
ICMP协议(Internet互联网控制报文协议),
IGMP协议(Internet组管理协议)。
IP是一种网络层协议,提供的是一种不可靠的服务,它只是尽可能快地把分组从源结点送到目的结点,但是并不提供任何可靠性保证。同时被TCP和UDP使用。TCP和UDP的每组数据都通过端系统和每个中间路由器中的IP层在互联网中进行传输。
ICMP是IP协议的附属协议。IP层用它来与其他主机或路由器交换错误报文和其他重要信息。
IGMP是Internet组管理协议。它用来把一个UDP数据报多播到多个主机。
链路层/网络接口层/网络访问层 Network Access Layer
也就是上图右边的网络接口层和硬件层,通常包括操作系统中的设备驱动程序和计算机中对应的网络接口卡。它们一起处理与电缆(或其他任何传输媒介)的物理接口细节。ARP(地址解析协议)和RARP(逆地址解析协议)是某些网络接口(如以太网和令牌环网)使用的特殊协议,用来转换IP层和网络接口层使用的地址。
以太网、Wifi、蓝牙工作在这一层,网络访问层提供了主机连接到物理网络需要的硬件和相关的协议
为什么要分层
分层的本质是通过分离关注点而让复杂问题简单化,通过分层可以做到:
- 各层独立:限制了依赖关系的范围,各层之间使用标准化的接口,各层不需要知道上下层是如何工作的,增加或者修改一个应用层协议不会影响传输层协议
- 灵活性更好:比如路由器不需要应用层和传输层,分层以后路由器就可以只用加载更少的几个协议层
- 易于测试和维护:提高了可测试性,可以独立的测试特定层,某一层有了更好的实现可以整体替换掉
- 能促进标准化:每一层职责清楚,方便进行标准化
抓个包瞄一瞄
- 这里抓一个http报文看看 直接后台 curl http://www.baidu.com
- 用到工具 Wireshark
wireshark设置只抓百度服务器的报文
后台运行curl
$ curl http://www.baidu.com
<!DOCTYPE html>
<!--STATUS OK--><html> <head><meta http-equiv=content-type content=text/html;charset=utf-8><meta http-equiv=X-UA-Compatible content=IE=Edge><meta content=always name=referrer><link rel=stylesheet type=text/css href=http://s1.bdstatic.com/r/www/cache/bdorz/baidu.min.css><title>百度一下,你就知道</title></head> <body link=#0000cc> <div id=wrapper> <div id=head> <div class=head_wrapper> <div class=s_form> <div class=s_form_wrapper> <div id=lg> <img hidefocus=true src=//www.baidu.com/img/bd_logo1.png width=270 height=129> </div> <form id=form name=f action=//www.baidu.com/s class=fm> <input type=hidden name=bdorz_come value=1> <input type=hidden name=ie value=utf-8> <input type=hidden name=f value=8> <input type=hidden name=rsv_bp value=1> <input type=hidden name=rsv_idx value=1> <input type=hidden name=tn value=baidu><span class="bg s_ipt_wr"><input id=kw name=wd class=s_ipt value maxlength=255 autocomplete=off autofocus></span><span class="bg s_btn_wr"><input type=submit id=su value=百度一下 class="bg s_btn"></span> </form> </div> </div> <div id=u1> <a href=http://news.baidu.com name=tj_trnews class=mnav>新闻</a> <a href=http://www.hao123.com name=tj_trhao123 class=mnav>hao123</a> <a href=http://map.baidu.com name=tj_trmap class=mnav>地图</a> <a href=http://v.baidu.com name=tj_trvideo class=mnav>视频</a> <a href=http://tieba.baidu.com name=tj_trtieba class=mnav>贴吧</a> <noscript> <a href=http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u=http%3A%2F%2Fwww.baidu.com%2f%3fbdorz_come%3d1 name=tj_login class=lb>登录</a> </noscript> <script>document.write('<a href="http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u='+ encodeURIComponent(window.location.href+ (window.location.search === "" ? "?" : "&")+ "bdorz_come=1")+ '" name="tj_login" class="lb">登录</a>');</script> <a href=//www.baidu.com/more/ name=tj_briicon class=bri style="display: block;">更多产品</a> </div> </div> </div> <div id=ftCon> <div id=ftConw> <p id=lh> <a href=http://home.baidu.com>关于百度</a> <a href=http://ir.baidu.com>About Baidu</a> </p> <p id=cp>©2017 Baidu <a href=http://www.baidu.com/duty/>使用百度前必读</a> <a href=http://jianyi.baidu.com/ class=cp-feedback>意见反馈</a> 京ICP证030173号 <img src=//www.baidu.com/img/gs.gif> </p> </div> </div> </div> </body> </html>
观察Wireshark抓包情况
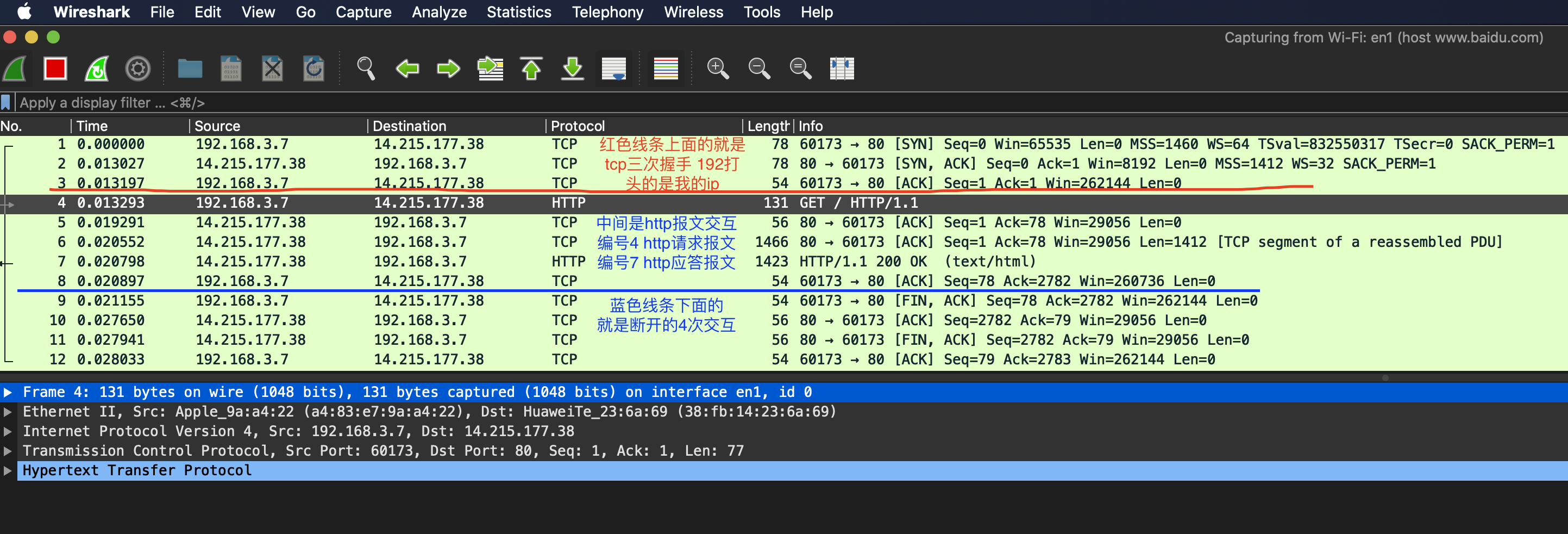
我们针对编号4的http请求报文 点击下面的详细简单看看
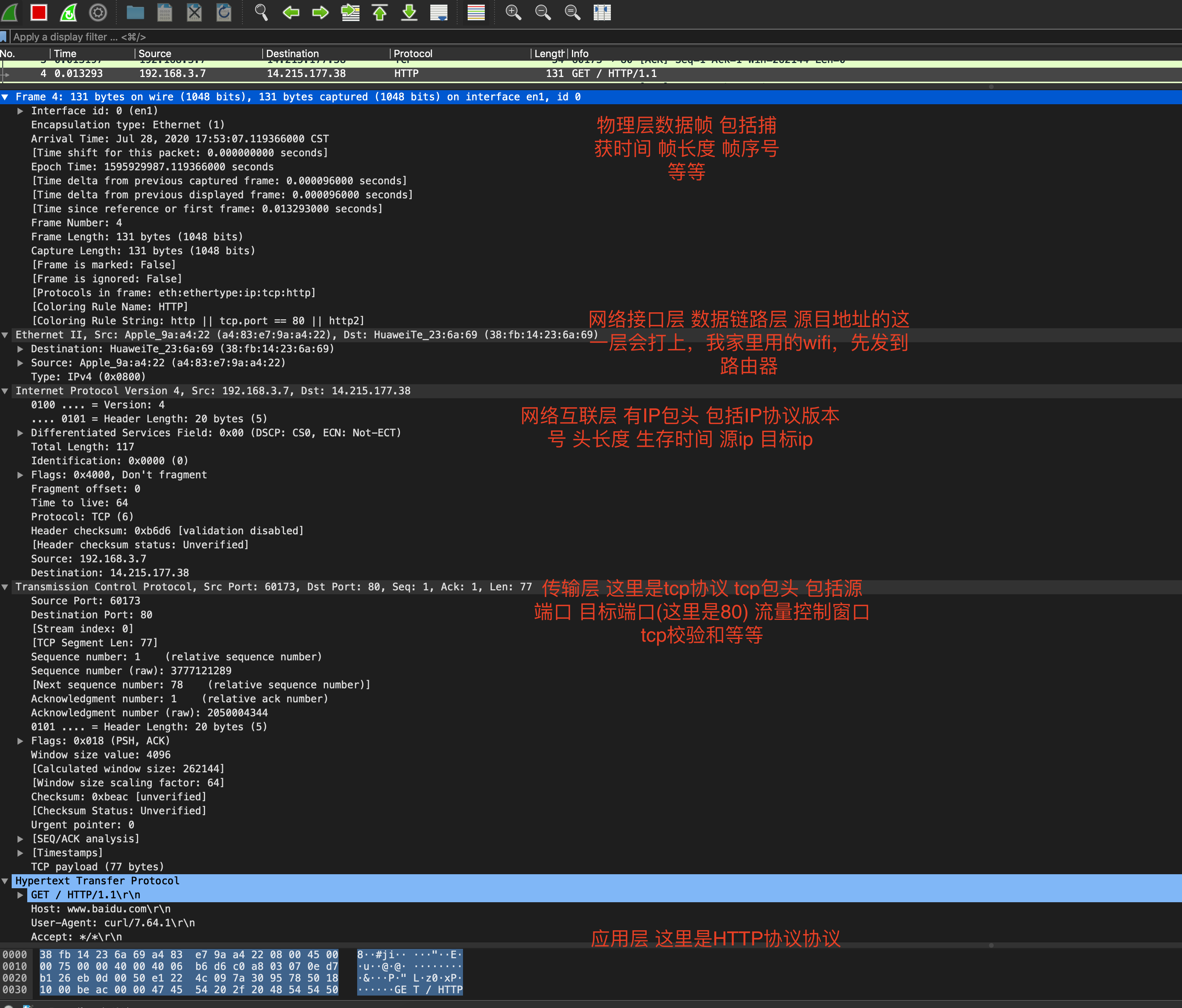
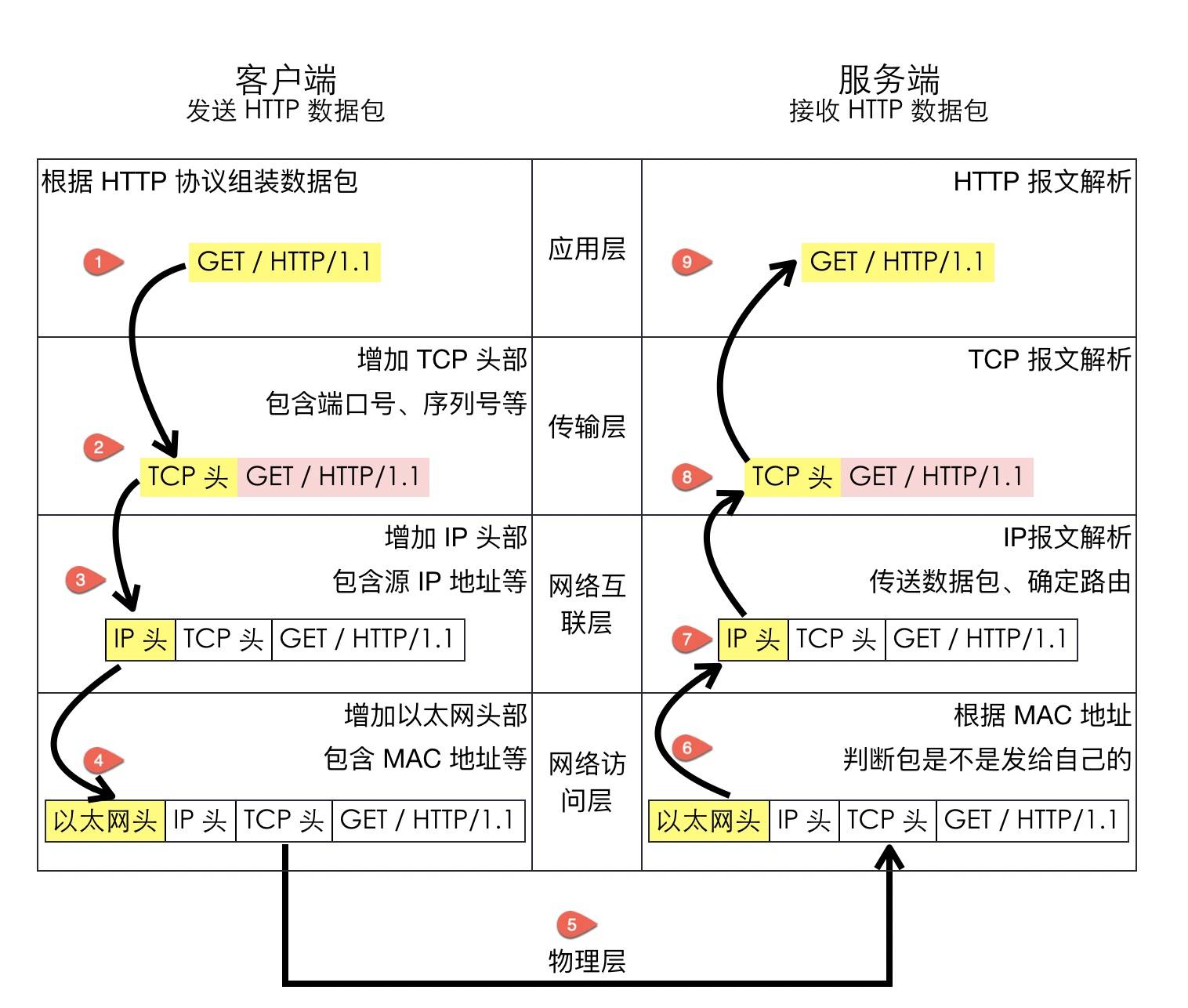
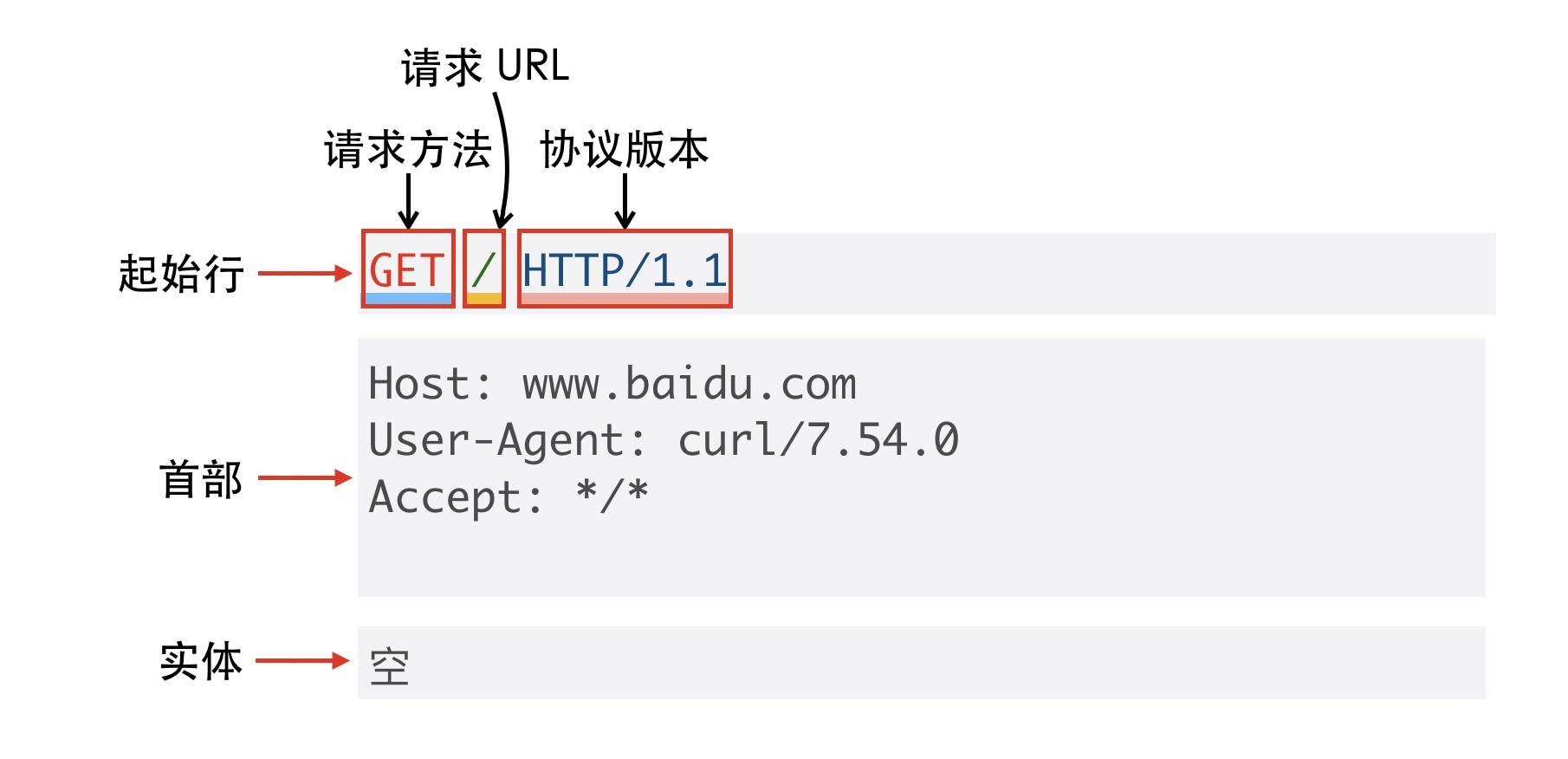
http应用层
- 起始行(start line),起始行根据是请求报文还是响应报文分为「请求行」和「响应行」。这个例子中起始行是
GET / HTTP/1.1,表示这是一个GET请求,请求的 URL 为/,协议版本为HTTP 1.1,起始行最后会有一个空行CRLF(\r\n)与下面的首部分隔开 - 首部(header),首部采用形如
key:value的方式,比如常见的User-Agent、ETag、Content-Length都属于 HTTP 首部,每个首部直接也是用空行分隔 - 可选的实体(entity),实体是 HTTP 真正要传输的内容,比如下载一个图片文件,传输的一段 HTML等
传输层
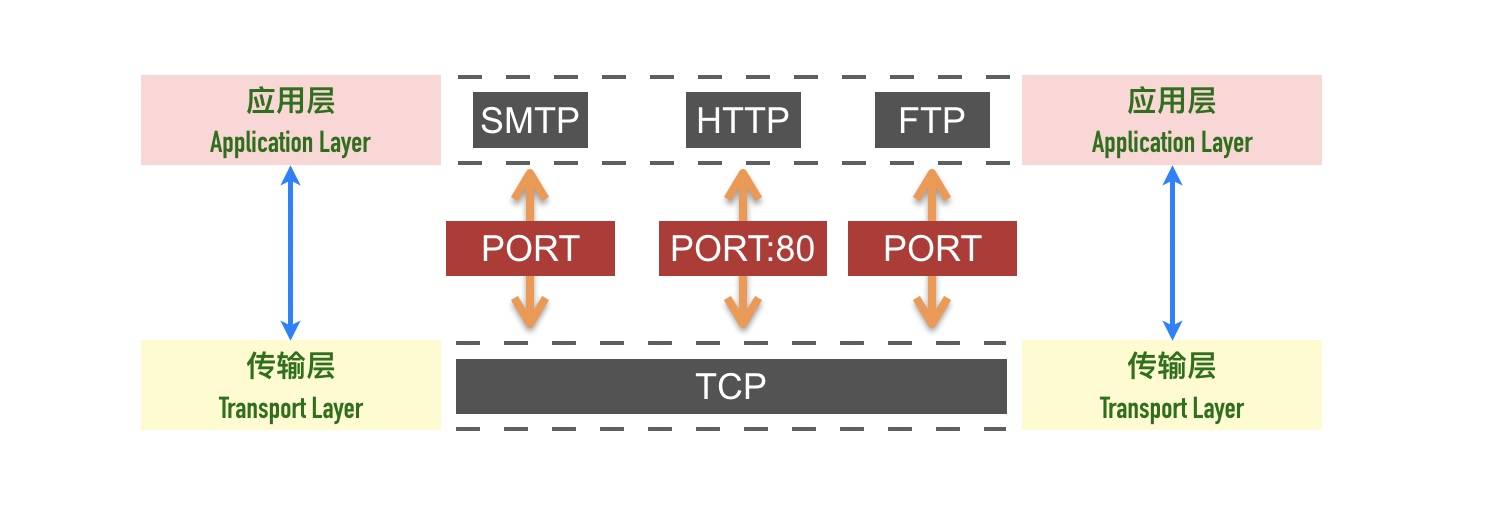
传输层两端的端口 代表两端的程序
网际互联
TCP概述
面向连接
- 面向连接的协议要求正式发送数据之前需要通过3次「握手」建立一个逻辑连接,结束通信时也是通过有序的四次挥手来断开连接
可靠的
IP 是一种无连接、不可靠的协议:它尽最大可能将数据报从发送者传输给接收者,但并不保证包到达的顺序会与它们被传输的顺序一致,也不保证包是否重复,甚至都不保证包是否会达到接收者。
TCP 要想在 IP 基础上构建可靠的传输层协议,必须有一个复杂的机制来保障可靠性。 主要有下面几个方面:
- 对每个包提供校验和
- 每个 TCP 包首部中都有两字节用来表示校验和,防止在传输过程中有损坏。如果收到一个校验和有差错的报文,TCP 不会发送任何确认直接丢弃它,等待发送端重传
- 包的序列号解决了接收数据的乱序、重复问题
- 接收端会根据序列号排序 去重
- 超时重传
- TCP 发送数据后会启动一个定时器,等待对端确认收到这个数据包。如果在指定的时间内没有收到 ACK 确认,就会重传数据包,然后等待更长时间,如果还没有收到就再重传,在多次重传仍然失败以后,TCP 会放弃这个包。
- 流量控制、拥塞控制
- 待补充
面向字节流的协议
-
流的含义就是没有边界,所以应用要自己界定边界
-
假设你调用 2 次 write 函数往 socket 里依次写 500 字节、800 字节。write 函数只是把字节拷贝到内核缓冲区,最终会以多少条报文发送出去是不确定的,如下图所示:
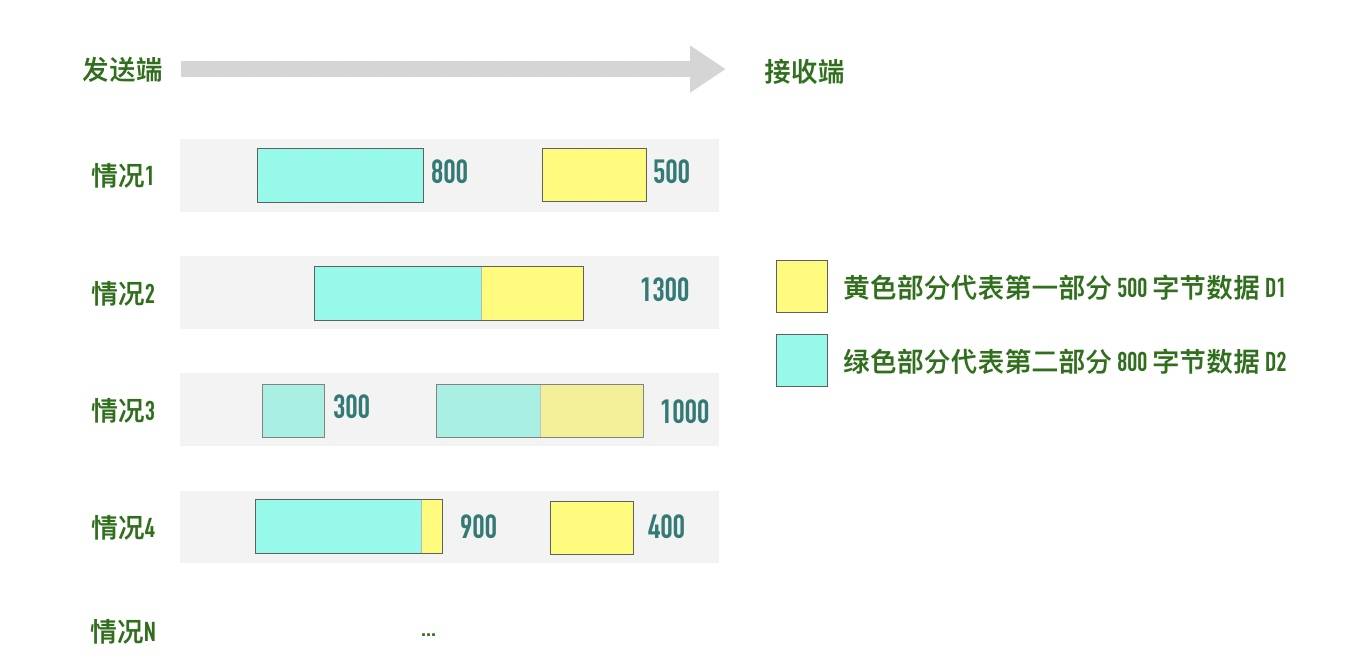
-
简单解释:
- 情况 1:分为两条报文依次发出去 500 字节 和 800 字节数据
- 情况 2:两部分数据合并为一个长度为 1300 字节的报文,一次发送
- 情况 3:第一部分的 500 字节与第二部分的 500 字节合并为一个长度为 1000 字节的报文,第二部分剩下的 300 字节单独作为一个报文发送
- 情况 4:第一部分的 400 字节单独发送,剩下100字节与第二部分的 800 字节合并为一个 900 字节的包一起发送。
- 情况 N:还有更多可能的拆分组合
上面出现的情况取决于诸多因素:路径最大传输单元 MTU、发送窗口大小、拥塞窗口大小等。
当接收方从 TCP 套接字读数据时,它是没法得知对方每次写入的字节是多少的。接收端可能分2 次每次 650 字节读取,也有可能先分三次,一次 100 字节,一次 200 字节,一次 1000 字节进行读取
全双工的协议
- 在 TCP 中发送端和接收端可以是客户端/服务端,也可以是服务器/客户端,通信的双方在任意时刻既可以是接收数据也可以是发送数据,每个方向的数据流都独立管理序列号、滑动窗口大小、MSS 等信息
概述总图:
Tcp头部
示意图
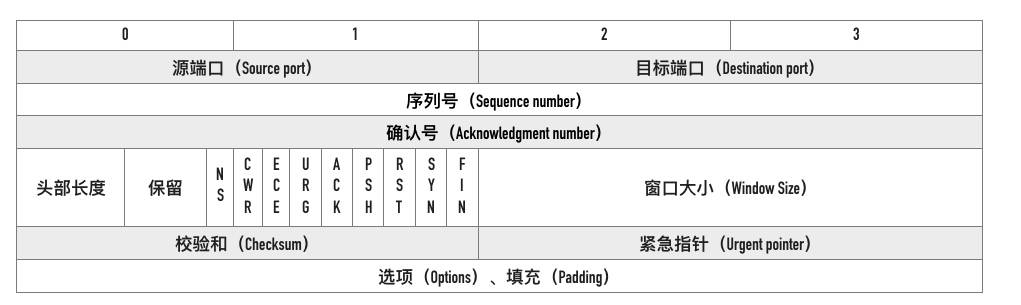
源端口号、目标端口号
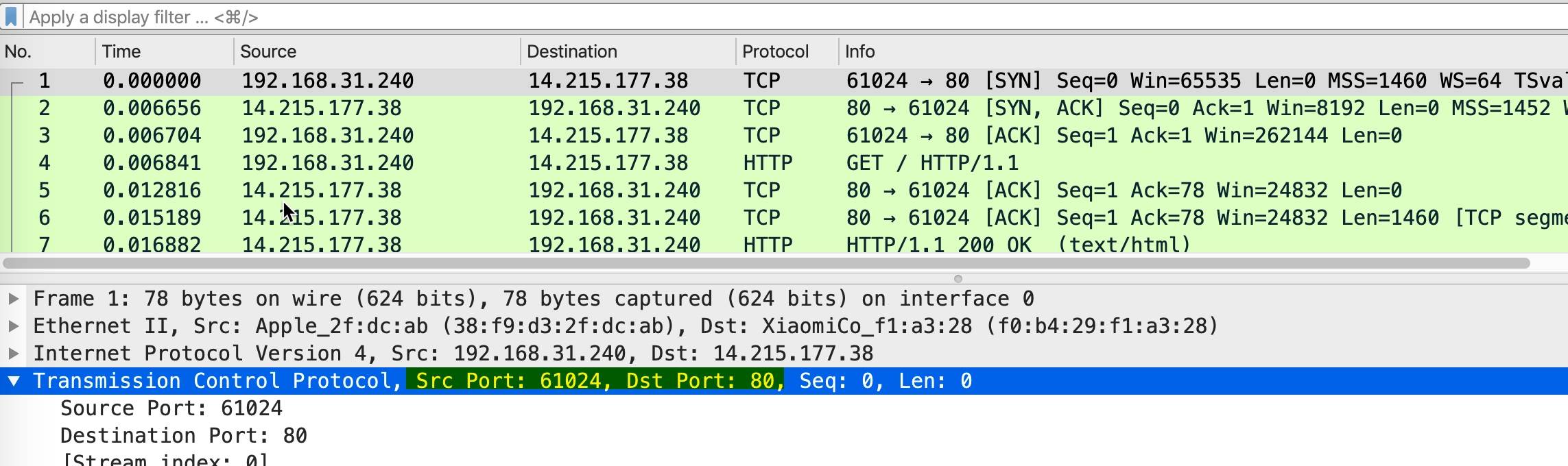
用wireshare抓包 点击tcp报文 就会出现源端口号( Src Port)和目标端口号(Dst Port), TCP报文是没有ip地址的,ip地址要去IP报文查看,示意图如下:
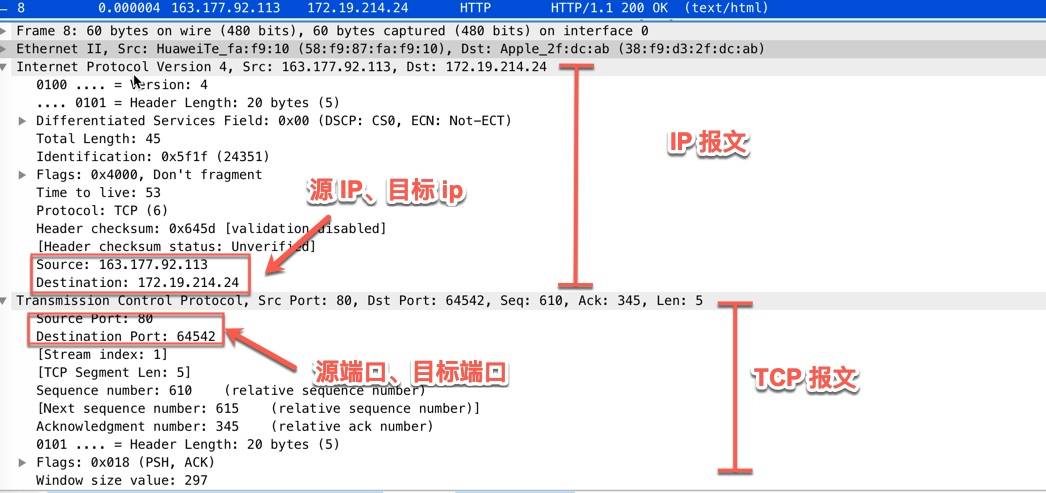
- TCP连接4元组 源IP、源端口、目标IP、目标端口。一个4元组可以唯一标示一个tcp连接
序列号 Seq
Tcp是面向字节流的协议,通过tcp协议传输的字节流都为其分配了序列号,序列号指的是本报文第一个字节的序列号
序列号+报文长度就可以确定传输的是哪一段数据
- 在SYN报文中 序列号用于交换彼此的初始序列号,在其它报文中,序列号用于保证包的顺序
- 因为IP层不保证包的顺序,所以这个保证主要是tcp层靠序列号保证的,如果发送方发送的是四个报文序列号分别是1、2、3、4,但到达接收方的顺序是 2、4、3、1,接收方就可以通过序列号的大小顺序组装出原始的数据
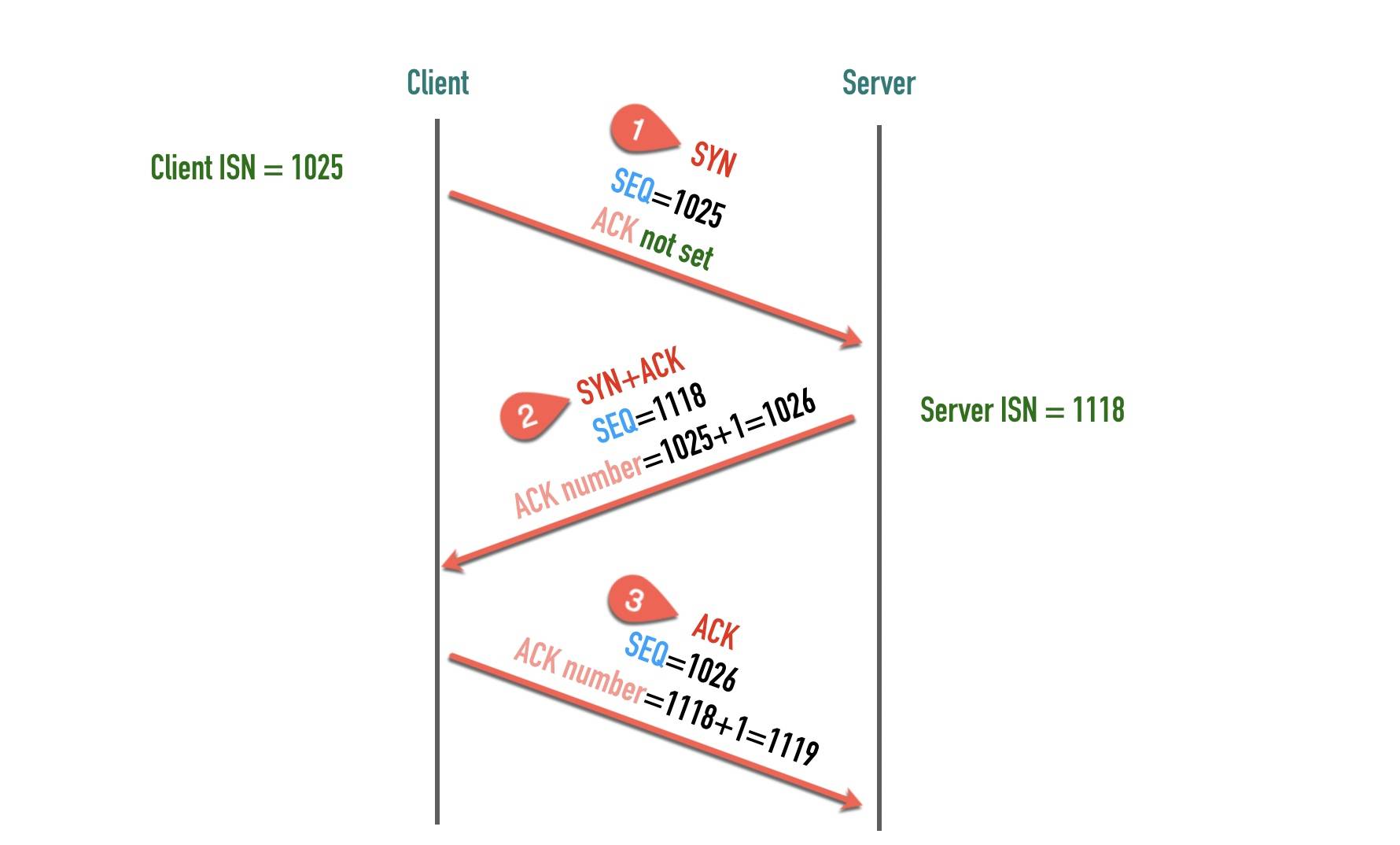
连接三次握手 初始化序列号(Initial Sequence Number)
在建立连接之初,通信双方都会各自选择一个序列号,称之为初始序列号。在建立连接时,通信双方通过 SYN 报文交换彼此的 ISN,如下图所示。
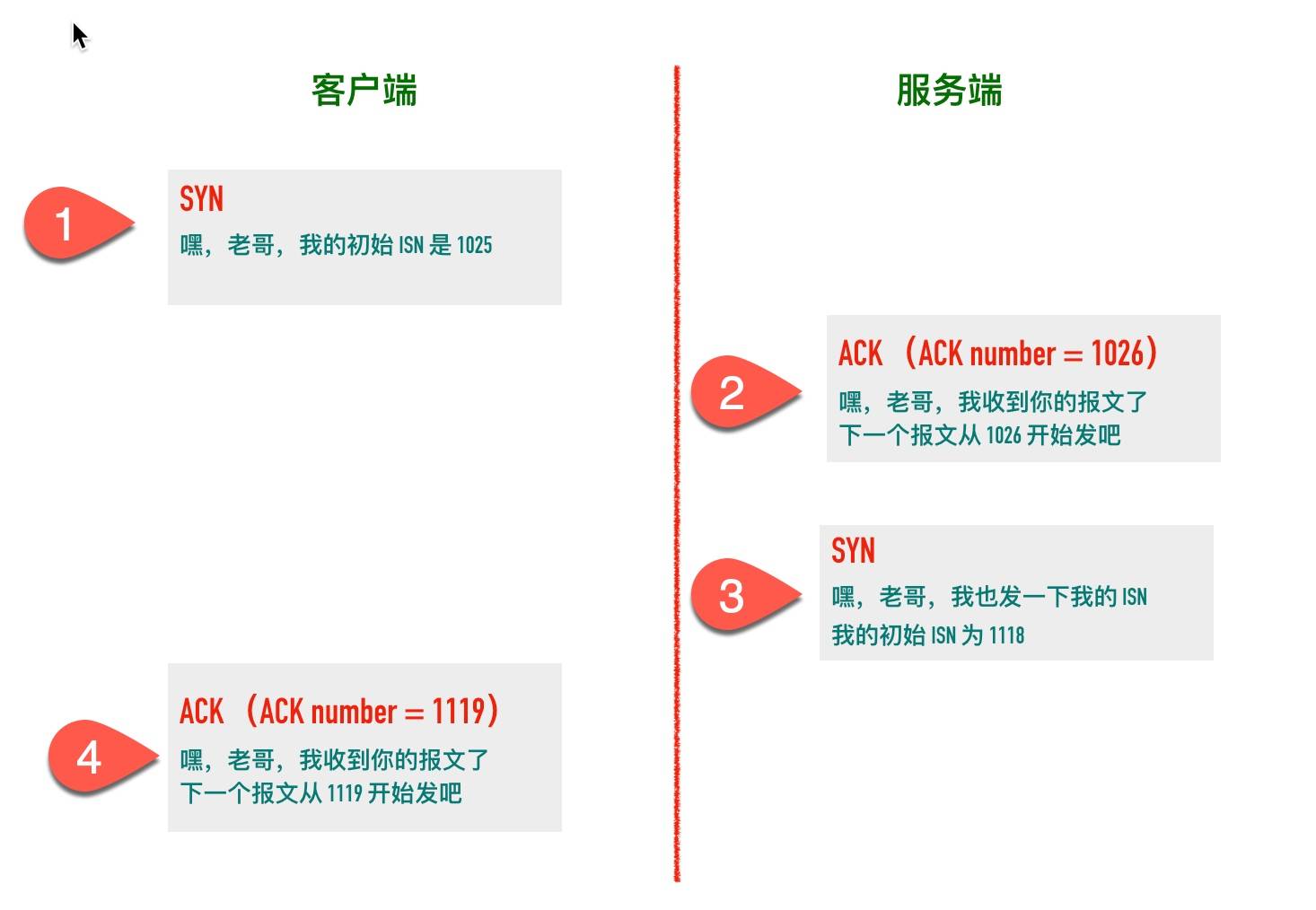
服务端的2、3两步一般合并发送,所以就变成了下面的三次握手过程
确认号 Ack
Ack的含义是告知对方 小于此Ack号的所有字节都已经收到,期望对方下次开始从Ack字节开始发送报文吧。

关于确认号有几个注意点:
- 不是所有的包都需要确认的
- 不是收到了数据包就立马需要确认的,可以延迟一会再确认
- ACK 包本身不需要被确认,否则就会无穷无尽死循环了
- 确认号永远是表示小于此确认号的字节都已经收到
校验和 checksum
每个 TCP 包首部中都有两字节用来表示校验和,防止在传输过程中有损坏。如果收到一个校验和有差错的报文,TCP 不会发送任何确认直接丢弃它,等待发送端重传。
TCP Flags
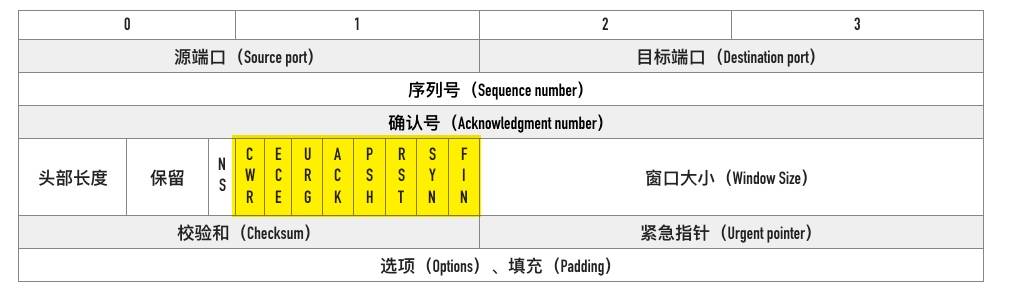
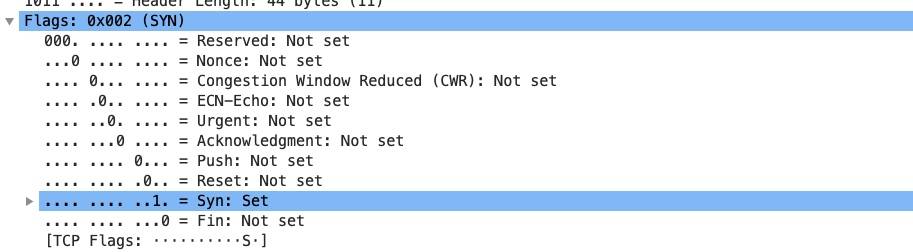
-
我们通常所说的 SYN、ACK、FIN、RST 其实只是把 flags 对应的 bit 位置为 1 而已,这些标记可以组合使用,比如 SYN+ACK,FIN+ACK 等
最常见的有下面这几个:
-
SYN(Synchronize):用于发起连接数据包同步双方的初始序列号
-
ACK(Acknowledge):确认数据包
-
RST(Reset):这个标记用来强制断开连接,通常是之前建立的连接已经不在了、包不合法、或者实在无能为力处理
-
FIN(Finish):通知对方我发完了所有数据,准备断开连接,后面我不会再发数据包给你了。
-
PSH(Push):告知对方这些数据包收到以后应该马上交给上层应用,不能缓存起来
窗口大小 windows size
可以看到用于表示窗口大小的"Window Size" 只有 16 位,可能 TCP 协议设计者们认为 16 位的窗口大小已经够用了,也就是最大窗口大小是 65535 字节(64KB)。就像网传盖茨曾经说过:“640K内存对于任何人来说都足够了”一样。
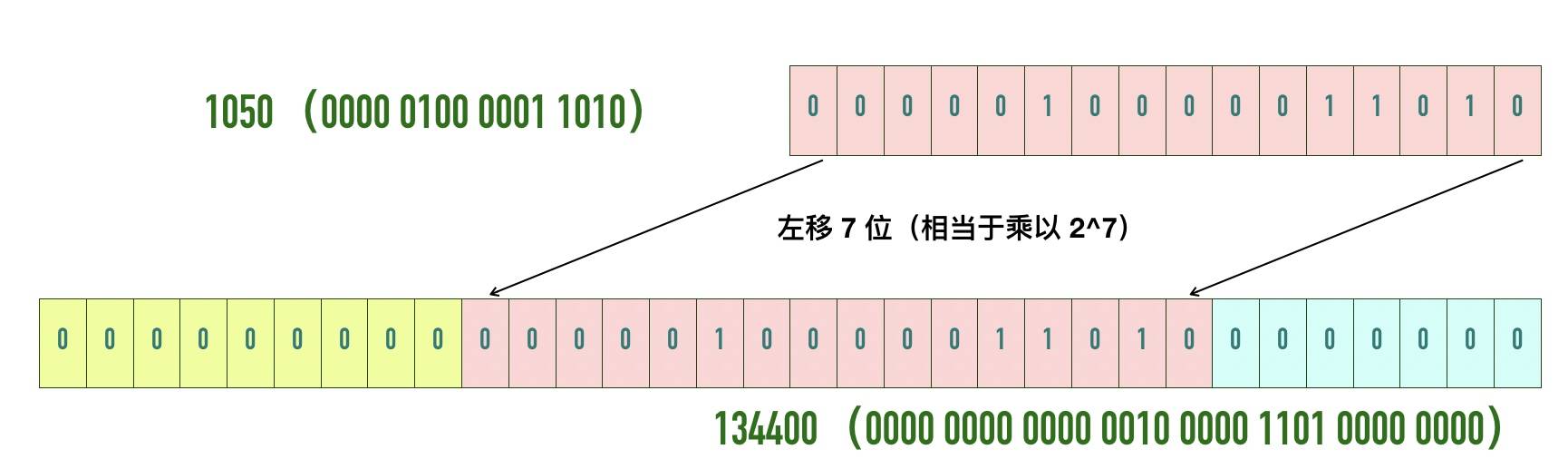
自己挖的坑当然要自己填,因此TCP 协议引入了「TCP 窗口缩放」选项 作为窗口缩放的比例因子,比例因子值的范围是 0 ~ 14,其中最小值 0 表示不缩放,最大值 14。比例因子可以将窗口扩大到原来的 2 的 n 次方,比如窗口大小缩放前为 1050,缩放因子为 7,则真正的窗口大小为 1050 * 128 = 134400,如下图所示
wireshark可以抓包看到窗口大小。
值得注意的是,窗口缩放值在三次握手的时候指定,如果抓包的时候没有抓到 SYN 包,wireshark 是不知道真正的窗口缩放值是多少的
可选项、填充
-
格式: 种类(Kind) 1byte,长度(Length)1 byte,值(value)
-
常用的可选项:
- MSS:最大段大小选项,是 TCP 允许的从对方接收的最大报文段
- SACK:选择确认选项
- Window Scale:窗口缩放选项
-
MSS抓包示意图
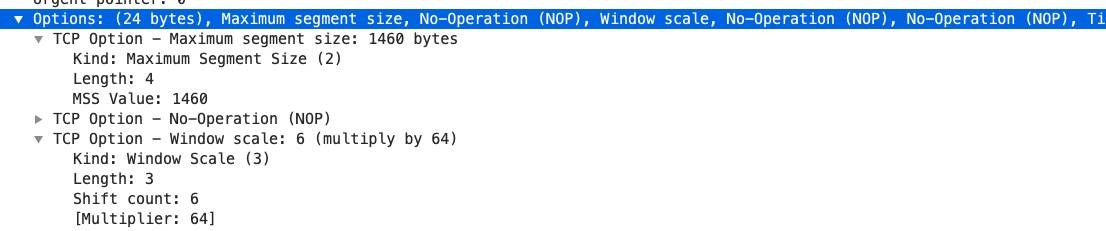
MTU、MSS
MTU(Maximum Transmission Unit) 最大传输单元
- MTU是在数据链路层限制的,数据链路层按照帧传输,每一帧因为协议限制也有大小限制,所以IP层不能把一个太大的包直接塞给链路层,这个限制叫做MTU。
以太网帧格式
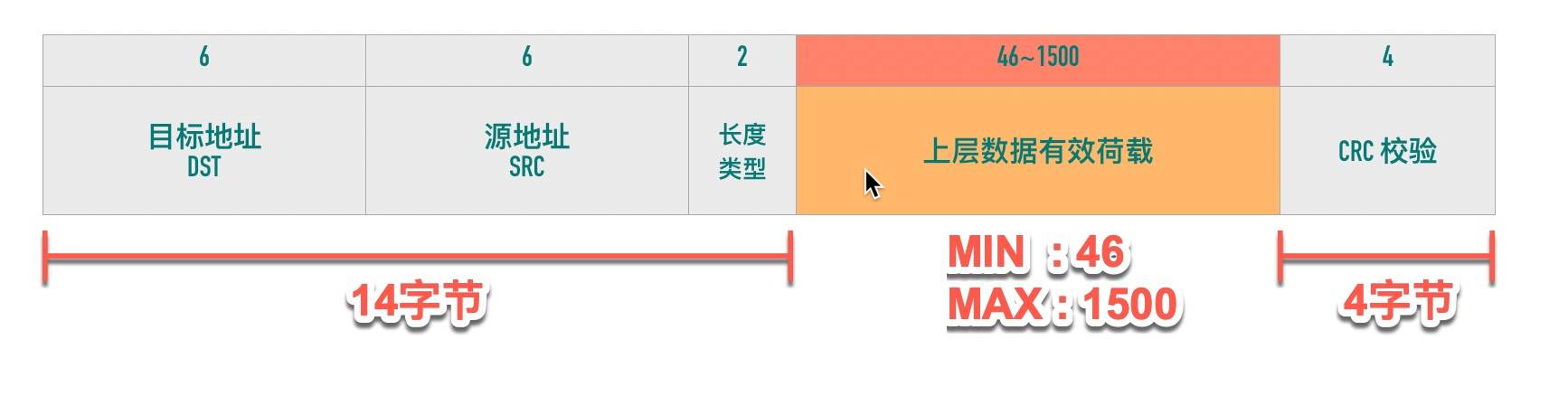
- 除去14字节头和4字节CRC校验 有效数据荷载范围为 46—>1500,这个就是以太网的MTU
- 假设以太网MTU为1500 传输100Kb数据,至少需要(100*1024/1500)=69帧
- 不同的数据链路层对应的MTU是不同的,可以通过netstat -i查看对应网卡的mtu,普通以太网一般是1500
IP分段
-
IP头格式

-
IPv4数据报最大大小为65535字节,远远大于以太网的MTU,有些网络还会开启巨帧模式(Jumbo Frame),可以得到9000字节。所以当一个IP数据报大于MTU时,IP层就会把报文切割为多个小的片段(小于MTU),从而使得这些报文能够在数据链路层传输。
一个大包—–>拆成多个小包 放入数据链路层
- 上面图片有个分片偏移量,就是用来表示该分段在原始数据报文中的位置,如果用wireshark抓报要乘以8.
抓包看下IP分段
-
ping -s 3000 www.baidu.com
man ping可以看到ping -s命令会增加8个字节的ICMP都,所以其实是发送3008字节
-
wireshark抓包截图

-
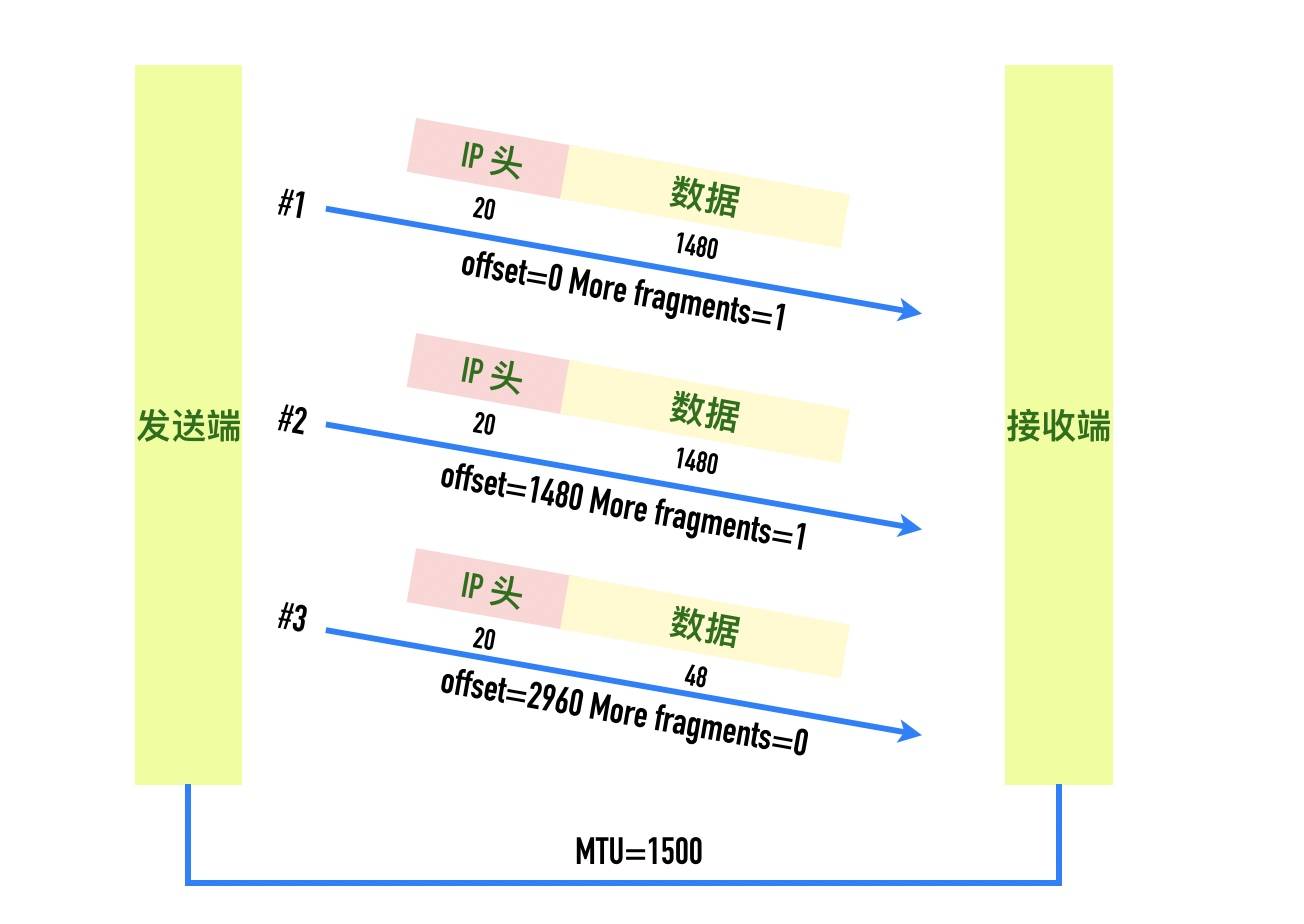
第一个包
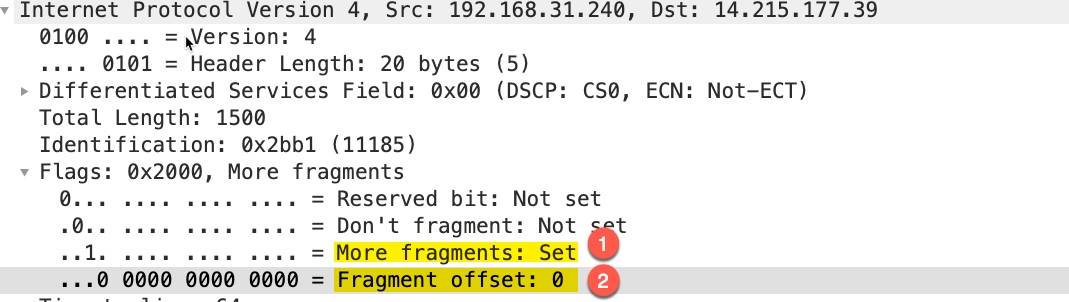
这个包是 IP 分段包的第一个分片,More fragments: Set表示这个包是 IP 分段包的一部分,还有其它的分片包,Fragment offset: 0表示分片偏移量为 0,IP 包的 payload 的大小为 1480,加上 20 字节的头部正好是 1500.
-
第2个包
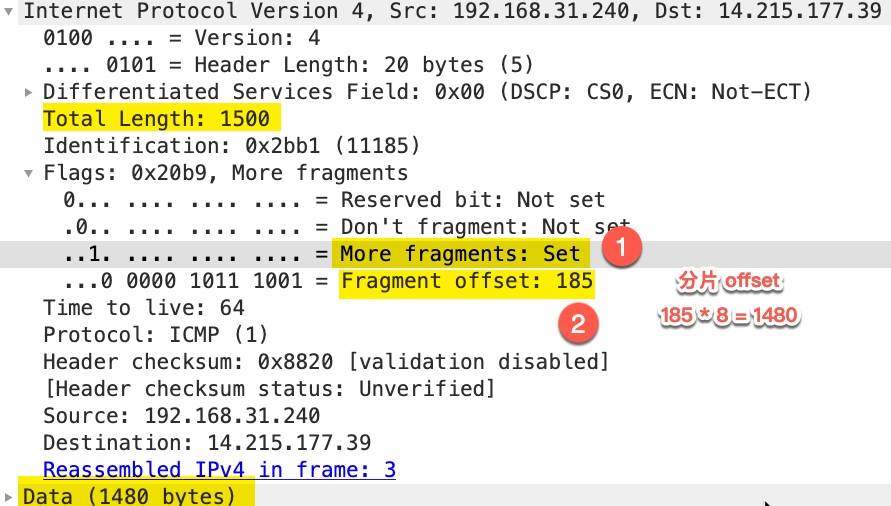
同样
More fragments处于 set 状态,表示后面还有其它分片,Fragment offset: 185这里并不是表示分片偏移量为 185,wireshark 这里显示的时候除以了 8,真实的分片偏移量为 185 * 8 = 1480 -
第3个包
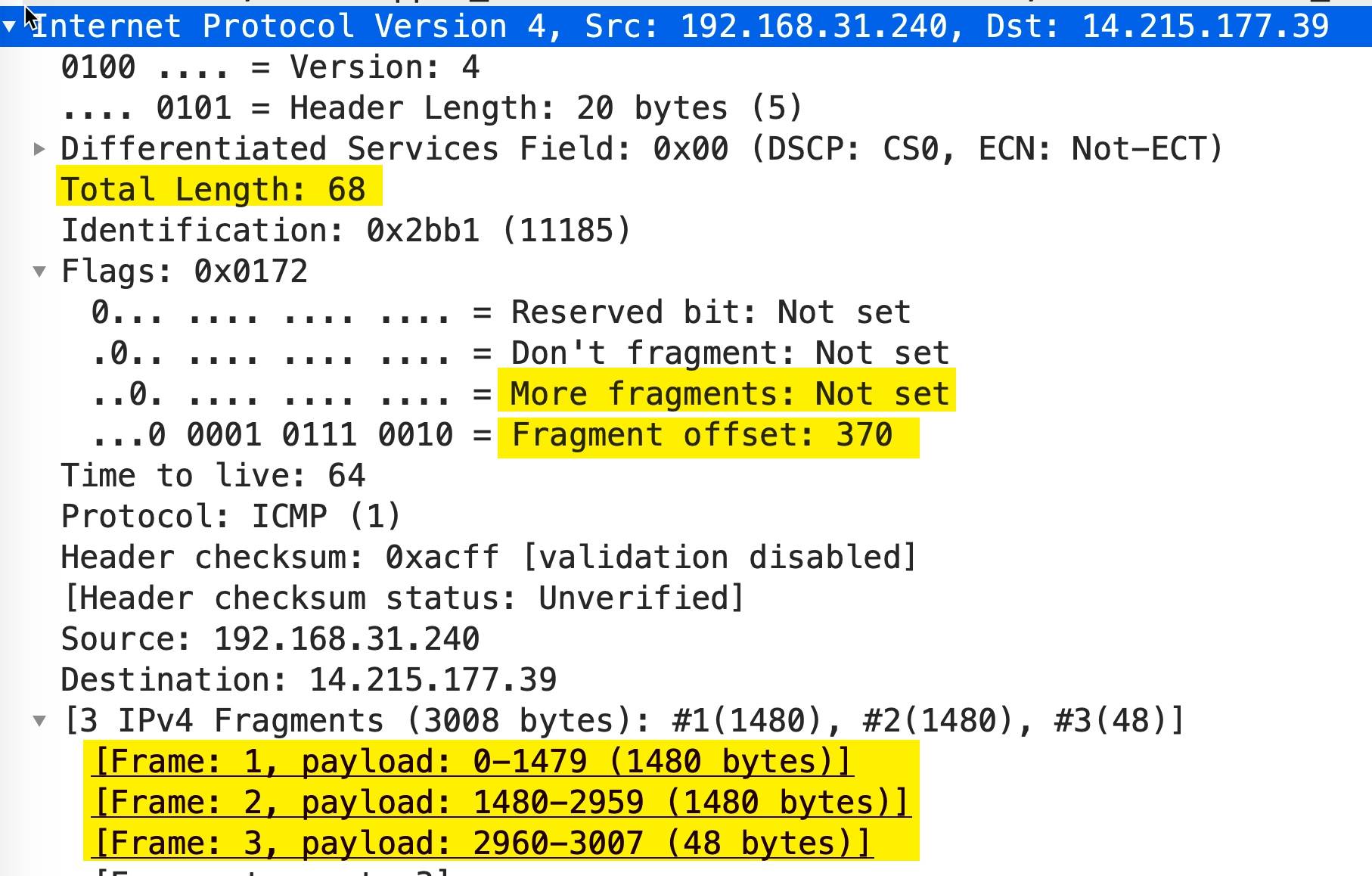
可以看到
More fragments处于 Not set 状态,表示这是最后一个分片了。Fragment offset: 370表示偏移量为 370 * 8 = 2960,包的大小为 68 - 20(IP 头部大小) = 48 -
3个包简单汇总示意
-
有一种攻击就是
IP fragment attack,一直传More fragments = 1的包,导致接收方一直缓存分片,从而可能导致接收方内存耗尽。
路径MTU
- 一个包从发送端到最后的接收端要经过各种各样的网络,每个网络的MTU都可能不一样,所以整个通道上最小的MTU就称为路径MTU(Path MTU)
Tcp最大段大小 MSS(Max Segment Size)
-
tcp为了避免被分片,会主动将数据分割成小段后,然后再交给网络层,最大的分段大小称为MSS。
-
MSS=MTU-sizeof(ip header)-sizeof(tcp header)
-
以太网中TCP的MSS=1500-20(ip header)-20(tcp header)=1460

socket选项 TCP_MAXSEG
TCP 有一个 socket 选项 TCP_MAXSEG,可以用来设置此次连接的 MSS,如果设置了这个选项,则 MSS 不能超过这个值
int tcp_maxseg = mss;
socklen_t tcp_maxseg_len = sizeof(tcp_maxseg);
// 设置 TCP_MAXSEG 选项
if ((err = setsockopt(server_fd, IPPROTO_TCP, TCP_MAXSEG, &tcp_maxseg, tcp_maxseg_len)) < 0) {
error_quit("set TCP_MAXSEG failed, code: %d\n", err);
}
端口Port
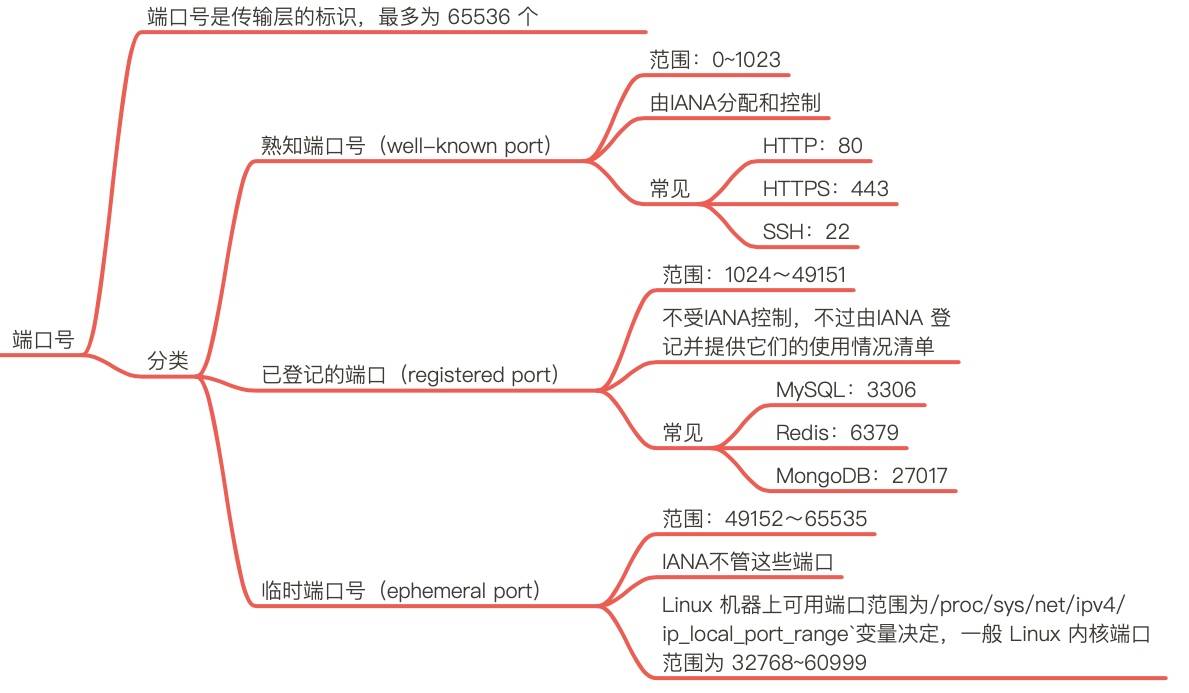
- 端口主要用来区别一个主机上的各个应用程序,一台主机最大允许65536个端口号
- 分层结构中 每一层都有一个唯一标示 tcp是端口,ip层是ip地址,链路层为mac地址
熟知端口号(well-known port)
知端口号由专门的机构由 IANA 分配和控制,范围为 0~1023。为了能让客户端能随时找到自己,服务端程序的端口必须要是固定的。很多熟知端口号已经被用就分配给了特定的应用,比如 HTTP 使用 80端口,HTTPS 使用 443 端口,ssh 使用 22 端口。 访问百度http://www.baidu.com/,其实就是向百度服务器之一(163.177.151.110)的 80 端口发起请求.
在linux上如果要监听这些端口 需要Root权限,熟知端口又是也被称为保留端口
已登机的端口(registered port)
已登记的端口不受 IANA 控制,不过由 IANA 登记并提供它们的使用情况清单。它的范围为 1024~49151。
为什么是 49151 这样一个魔数? 其实是取的端口号最大值 65536 的 3/4 减 1 (49151 = 65536 * 0.75 - 1)。可以看到已登记的端口占用了大约 75% 端口号的范围。
已登记的端口常见的端口号有:
- MySQL:3306
- Redis:6379
- MongoDB:27017
熟知和已登机端口可以在iana官网查到
临时端口(ephemeral port)
如果应用程序没有调用 bind() 函数将 socket 绑定到特定的端口上,那么 TCP 和 UDP 会为该 socket 分配一个唯一的临时端口。IANA 将 49152~65535 范围的端口称为临时端口(ephemeral port)或动态端口(dynamic port),也称为私有端口(private port),这些端口可供本地应用程序临时分配端口使用。
不同的操作系统实现会选择不同的范围分配临时端口,在 Linux 上能分配的端口范围由 /proc/sys/net/ipv4/ip_local_port_range 变量决定,一般 Linux 内核端口范围为 32768~60999
cat /proc/sys/net/ipv4/ip_local_port_range
32768 60999
在需要主动发起大量连接的服务器上(比如网络爬虫、正向代理)可以调整 ip_local_port_range 的值,允许更多的可用端口。
-
调用bind函数 但不指定端口 也会分配临时端口
-
调用connect函数也会分配临时端口
-
临时端口可能耗尽,届时会创建应用失败
- 修改临时端口范围
ketonghe@ubuntu:~$ sudo sysctl -w net.ipv4.ip_local_port_range="50001 50001" net.ipv4.ip_local_port_range = 50001 50001- 启动一个客户端连接
ketonghe@ubuntu:~$ netstat -anpl|grep 8787 (Not all processes could be identified, non-owned process info will not be shown, you would have to be root to see it all.) tcp 0 0 192.168.3.66:8787 0.0.0.0:* LISTEN 81014/./server tcp 0 0 192.168.3.66:8787 192.168.3.66:50001 ESTABLISHED 81014/./server tcp 0 0 192.168.3.66:50001 192.168.3.66:8787 ESTABLISHED 81016/./client-
再启动一个客户端连接
ketonghe@ubuntu:~/code$ ./client connect error,procedure will exit: Cannot assign requested address 没有临时端口 报错 ------调用系统命令 strace 查看程序执行的系统调用 就会发现connect报错 EADDRNOTAVAIL strace ./client|grep connect .... socket(AF_INET, SOCK_STREAM, IPPROTO_IP) = 3 connect(3, {sa_family=AF_INET, sin_port=htons(8787), sin_addr=inet_addr("192.168.3.66")}, 16) = -1 EADDRNOTAVAIL (Cannot assign requested address) dup(2) = 4 fcntl(4, F_GETFL) = 0x2 (flags O_RDWR) fstat(4, {st_mode=S_IFCHR|0620, st_rdev=makedev(136, 4), ...}) = 0 write(4, "connect error,procedure will exi"..., 67connect error,procedure will exit: Cannot assign requested address ) = 67 close(4) = 0 exit_group(0) = ? +++ exited with 0 +++
端口相关命令
-
nc telnet 可以查看对应端口是否打开(是否有对应应用已经启动并占用这个端口)
telnet 10.211.55.12 6379 Trying 10.211.55.12... Connected to 10.211.55.12. Escape character is '^]'. ------------------- nc -v 10.211.55.12 6379 Ncat: Connected to 10.211.55.12:6379 telnet 10.211.55.12 6380 Trying 10.211.55.12... telnet: connect to address 10.211.55.12: Connection refused nc -v 127.0.0.1 1234 nc: connectx to 127.0.0.1 port 1234 (tcp) failed: Connection refused -
netstat lsof 查看端口被什么进程占用
ketonghe@ubuntu:~$ netstat -ltpn | grep 8787 (Not all processes could be identified, non-owned process info will not be shown, you would have to be root to see it all.) tcp 0 0 192.168.3.66:8787 0.0.0.0:* LISTEN 80550/./server ketonghe@ubuntu:~$ sudo lsof -n -P -i:8787 [sudo] password for ketonghe: COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME server 80550 ketonghe 3u IPv4 1098588 0t0 TCP 192.168.3.66:8787 (LISTEN) ---- 其中 -n 表示不将 IP 转换为 hostname,-P 表示不将 port number 转换为 service name,-i:port 表示端口号为 22 的进程 -
找到进程监听的端口号
-
ps找到进程id
ketonghe@ubuntu:~$ sudo netstat -atpn | grep 80550 tcp 0 0 192.168.3.66:8787 0.0.0.0:* LISTEN 80550/./server ------------------------------------------------------------- sudo lsof -n -P -p 80550 不grep过滤 会显示占用的文件具柄 lsof: WARNING: can't stat() fuse.gvfsd-fuse file system /run/user/1000/gvfs Output information may be incomplete. COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME server 80550 ketonghe cwd DIR 8,1 4096 1184987 /home/ketonghe/code server 80550 ketonghe rtd DIR 8,1 4096 2 / server 80550 ketonghe txt REG 8,1 13792 1184981 /home/ketonghe/code/server server 80550 ketonghe mem REG 8,1 2030544 132349 /lib/x86_64-linux-gnu/libc-2.27.so server 80550 ketonghe mem REG 8,1 170960 132345 /lib/x86_64-linux-gnu/ld-2.27.so server 80550 ketonghe 0u CHR 136,0 0t0 3 /dev/pts/0 server 80550 ketonghe 1u CHR 136,0 0t0 3 /dev/pts/0 server 80550 ketonghe 2u CHR 136,0 0t0 3 /dev/pts/0 server 80550 ketonghe 3u IPv4 1098588 0t0 TCP 192.168.3.66:8787 (LISTEN) server 80550 ketonghe 4u a_inode 0,14 0 11406 [eventpoll] ketonghe@ubuntu:~$ sudo lsof -n -P -p 80550|grep TCP //只看TCP协议 lsof: WARNING: can't stat() fuse.gvfsd-fuse file system /run/user/1000/gvfs Output information may be incomplete. server 80550 ketonghe 3u IPv4 1098588 0t0 TCP 192.168.3.66:8787 (LISTEN) ------------------------------------------------------------- ketonghe@ubuntu:/proc/80550/fd$ l /proc/80550/fd total 0 lrwx------ 1 ketonghe ketonghe 64 Aug 3 21:54 4 -> 'anon_inode:[eventpoll]'//这个为epollfd lrwx------ 1 ketonghe ketonghe 64 Aug 3 21:54 3 -> 'socket:[1098588]'//监听fd 1098588为socket的inode lrwx------ 1 ketonghe ketonghe 64 Aug 3 21:54 2 -> /dev/pts/0 //stderr lrwx------ 1 ketonghe ketonghe 64 Aug 3 21:54 1 -> /dev/pts/0 //stdout lrwx------ 1 ketonghe ketonghe 64 Aug 3 21:54 0 -> /dev/pts/0 //stdin ketonghe@ubuntu:/proc/80550/fd$ cat /proc/net/tcp sl local_address rem_address st tx_queue rx_queue tr tm->when retrnsmt uid timeout inode 0: 0100007F:A281 00000000:0000 0A 00000000:00000000 00:00000000 00000000 0 0 46378 1 0000000000000000 100 0 0 10 0 1: 4203A8C0:2253 00000000:0000 0A 00000000:00000000 00:00000000 00000000 1000 0 1098588 1 0000000000000000 100 0 0 10 0 2: 3500007F:0035 00000000:0000 0A 00000000:00000000 00:00000000 00000000 101 0 36001 1 0000000000000000 100 0 0 10 0 3: 00000000:0016 00000000:0000 0A 00000000:00000000 00:00000000 00000000 0 0 1097236 1 0000000000000000 100 0 0 10 0 4: 0100007F:0277 00000000:0000 0A 00000000:00000000 00:00000000 00000000 0 0 980905 1 0000000000000000 100 0 0 10 0 5: 4203A8C0:0016 0703A8C0:E447 01 00000000:00000000 02:0009FF18 00000000 0 0 1100461 4 0000000000000000 20 4 31 10 -1 ------可以看到inode为1098588的套接字 也可以看到本地地址 远端地址 st为0A 表示正在监听 为TCP_LISTEN状态
-
端口安全
-
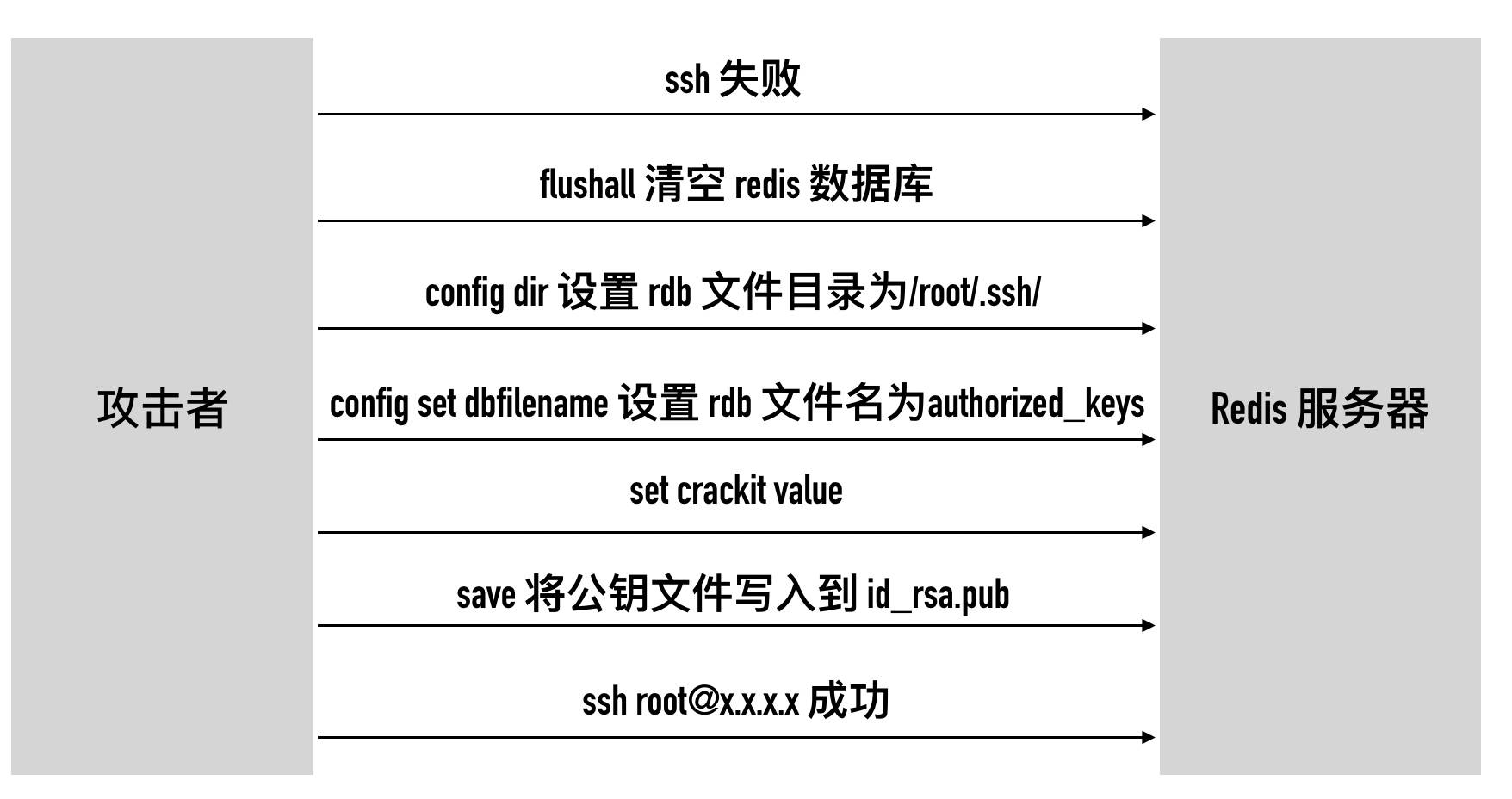
redis无密码登录被黑
端口小结
三次握手
经典3次握手示意图
-
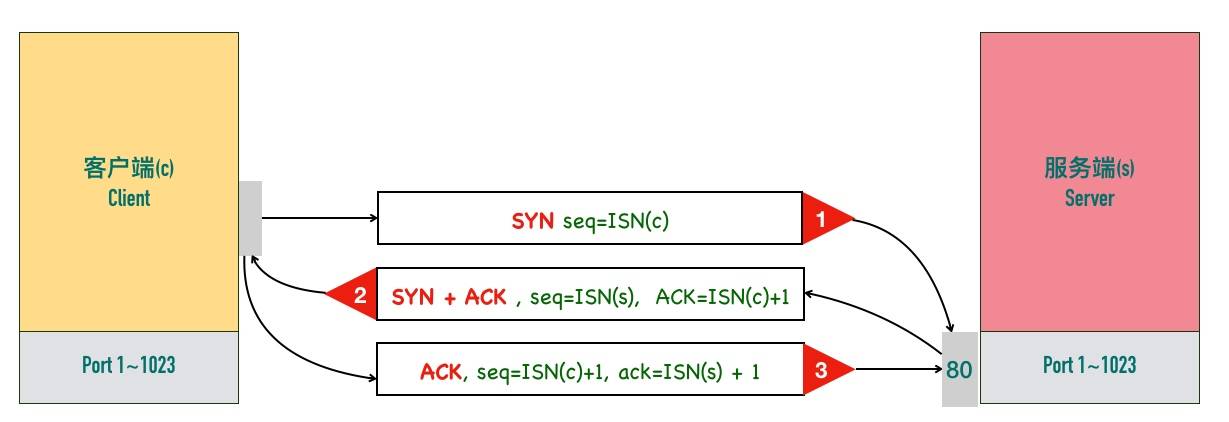
三次握手最重要的是交换彼此的ISN(初始化序列号),初始序列号的计算要查看内核,可以先掌握变化规律
-
客户端c先发送SYN报文 tcpflags只有SYN置位 报文不携带数据,但也占用一个序列号,因为需要服务端确认Ack
- 凡消耗序列号的tcp报文段,一定要对方确认,如果对方不Ack,发送端则会一直重传到指定次数为止
-
服务端s收到客户端c的SYN后,将SYN和ACK两个flag都置位,SYN是告诉客户端自己的初始化序列号是多少,Ack为ISN(c)+1是为了告诉<Ack的报文都已经收到,下次再发请从Ack编号开始,这里的SYN也需要对方(客户端)确认 所以这里也消耗一个序列号
-
客户端c发送最后一个ACK,因为不需要对方再次确认 所以就不消耗序列号
初始化序列号(Initial Sequence Number)
ISN并不是从0开始的,wireshark可能默认显示的相对序列号,这个linux是有固定的算法,总是是动态的,主要是安全考虑。
- 如果知道了连接的ISN,比较容易构造一个RST包,将连接直接关闭。如果是动态的,比较难构造RST
- socket也支持 SO_REUSEADDR端口重用,如果ISN固定 收到一个包就不知道是老包重传的还是新的连接包,保证2个连接的ISN不会串包
三次握手状态变化
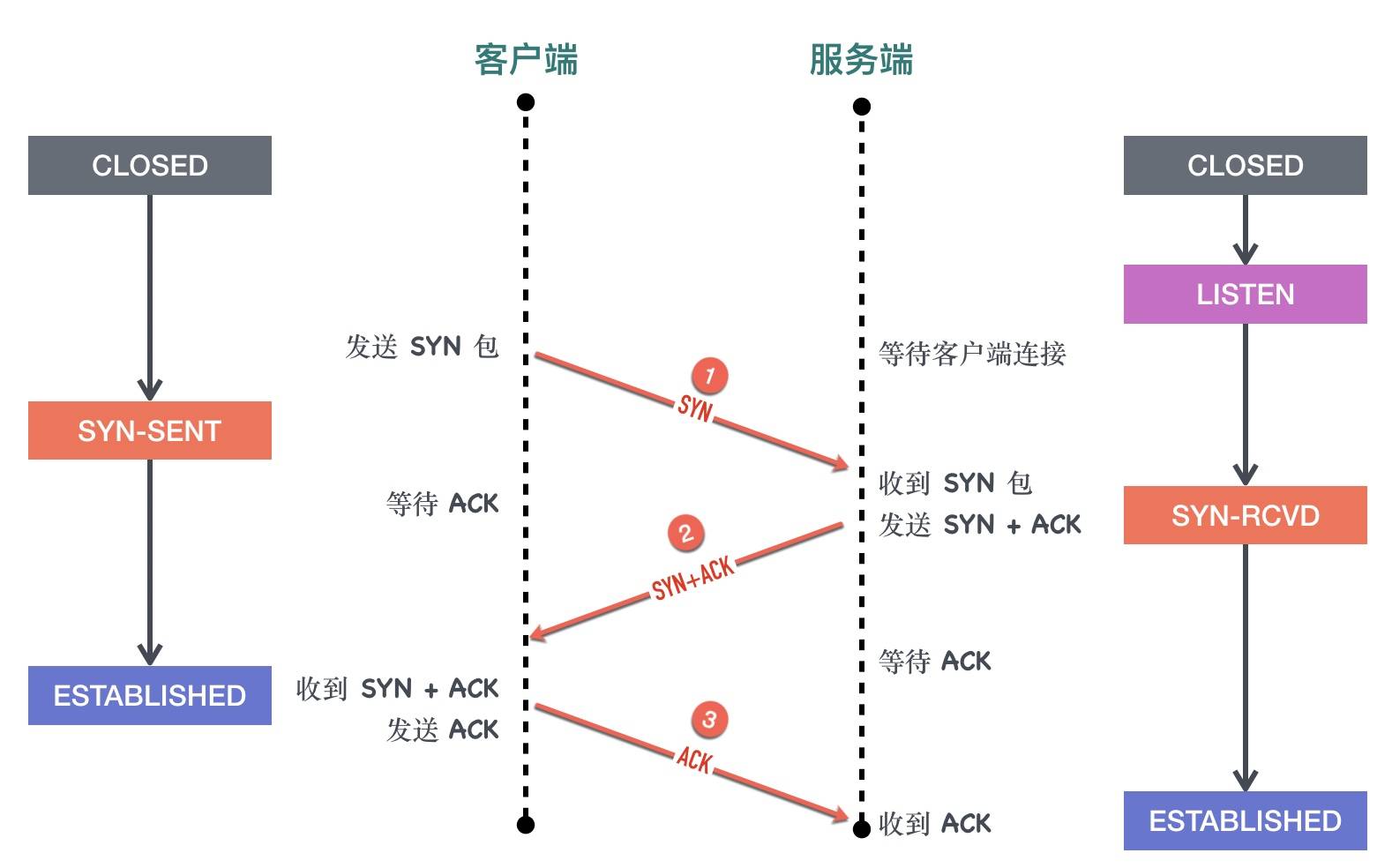
对于客户端而言:
- 初始的状态是处于
CLOSED状态。CLOSED 并不是一个真实的状态,而是一个假想的起点和终点。 - 客户端调用 connect 以后会发送 SYN 同步报文给服务端,然后进入
SYN-SENT阶段,客户端将保持这个阶段直到它收到了服务端的确认包。 - 如果在
SYN-SENT状态收到了服务端的确认包,它将发送确认服务端 SYN 报文的 ACK 包,同时进入 ESTABLISHED 状态,表明自己已经准备好发送数据。
对于服务端而言:
- 初始状态同样是
CLOSED状态 - 在执行 bind、listen 调用以后进入
LISTEN状态,等待客户端连接。 - 当收到客户端的 SYN 同步报文以后,会回复确认同时发送自己的 SYN 同步报文,这时服务端进入
SYN-RCVD阶段等待客户端的确认。 - 当收到客户端的确认报文以后,进入
ESTABLISHED状态。这时双方可以互相发数据了
发送syn包 对方没有回复会怎么样
-
客户端会处于SYN-SENT状态一段时间,会尝试重发SYN包 多少次有开关
-
ketonghe@ubuntu:~/code$ cat /proc/sys/net/ipv4/tcp_syn_retries 6 6次重试(65s = 1s+2s+4s+8s+16s+32s)以后放弃重试,connect 调用返回 -1,调用超时,如果是真实客户端
-
-
packetdrill 构造SYN_SENT 状态的连接
ketonghe@ubuntu:~/packetdrill/pkt$ cat a.pkt // 新建一个 server socket +0 socket(..., SOCK_STREAM, IPPROTO_TCP) = 3 // 客户端 connect +0 connect(3, ..., ...) = -1 --------执行发包 sudo /home/ketonghe/packetdrill/gtests/net/packetdrill/packetdrill a.pkt -----tcpdump抓包 ketonghe@ubuntu:~/code$ sudo tcpdump -i any port 8080 -nn -U -vvv -w test.pcap [sudo] password for ketonghe: tcpdump: listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes Got 7------重发6次 然后超时 6次重试(65s = 1s+2s+4s+8s+16s+32s)以后放弃重试,connect 调用返回 -1,调用超时
TCP同时打开
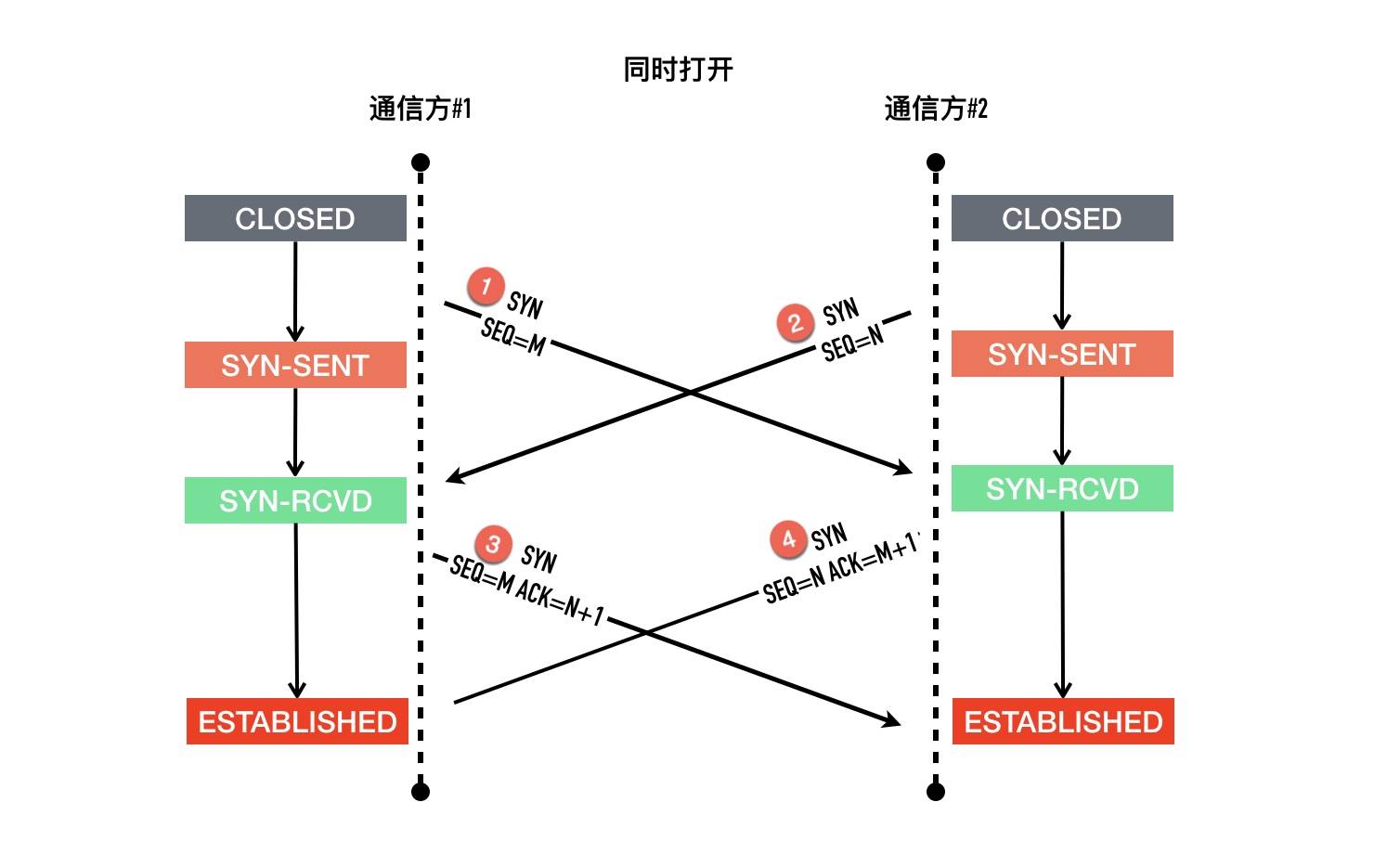
以其中一方为例,记为 A,另外一方记为 B
- 最初的状态是
CLOSED - A 发起主动打开,发送
SYN给 B,然后进入SYN-SENT状态 - A 还在等待 B 回复的
ACK的过程中,收到了 B 发过来的SYN,what are you 弄啥咧,A 没有办法,只能硬着头皮回复SYN+ACK,随后进入SYN-RCVD - A 依旧死等 B 的 ACK
- 好不容易等到了 B 的 ACK,对于 A 来说连接建立成功
TCP自连接
-
假设一个客户端想要连接的端口是50001
-
客户端启动的时候系统临时端口只有50001 也就是自己连接自己
-
这个时候就会出现自连接现象。
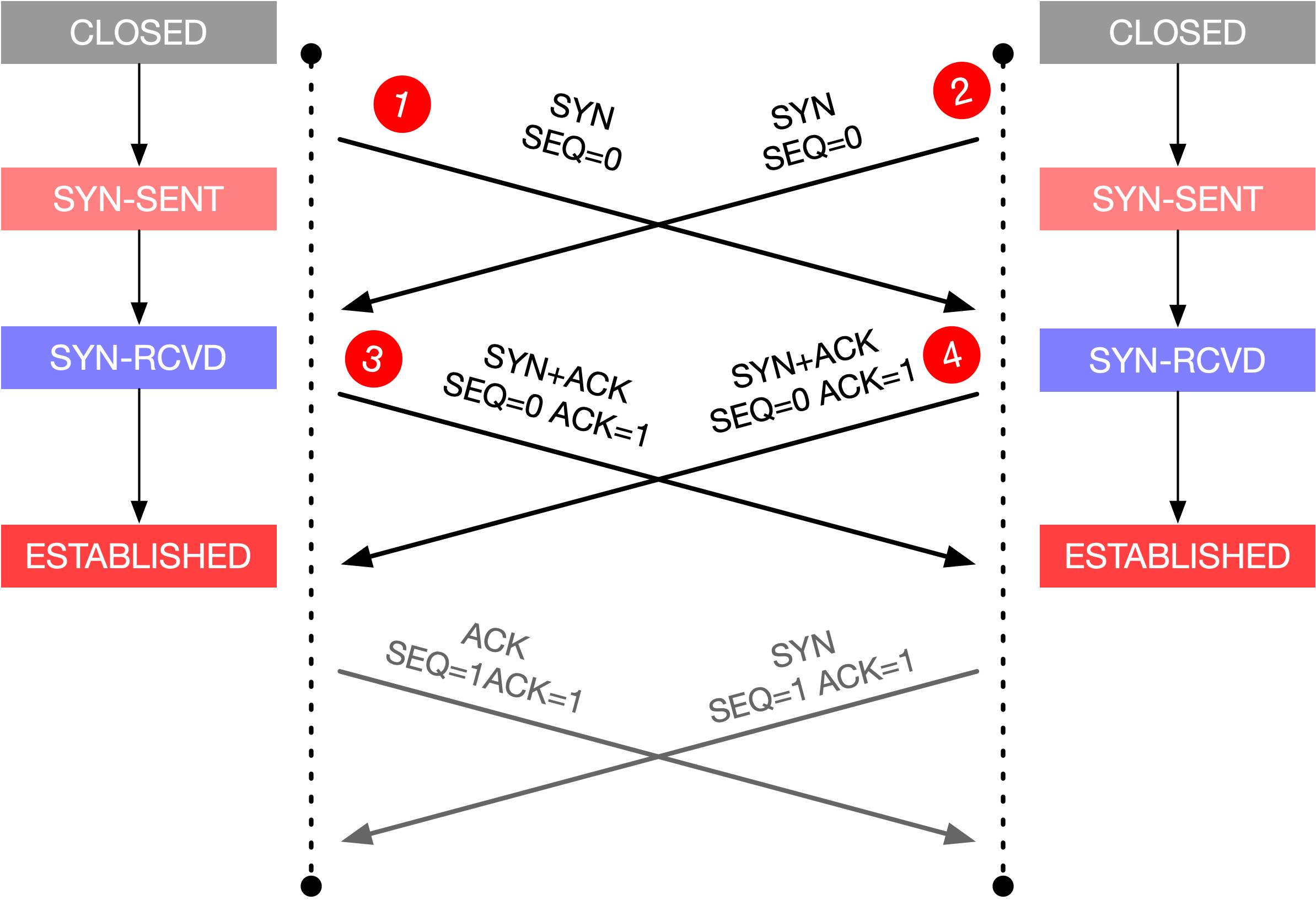
- 作为客户端发送SYN (最后发给了自己)
- 作为服务端收到自己发送的SYN包 以为对方想连接 所以回复SYN+ACK(回复给了自己)
- 自己收到自己发送的SYN和ACK 以为是对方回复的,认为握手成功,进入ESTABLISHED状态
模拟自连接
准备客户端程序
int cliSocket=socket(AF_INET,SOCK_STREAM,0);
servaddr.sin_addr.s_addr = inet_addr("192.168.3.66");
servaddr.sin_port = htons(50001);
//连接服务器
if( 0 != connect(cliSocket,(struct sockaddr *)&servaddr,sizeof(servaddr))){
perror("connect error,procedure will exit");
return 0;
}
char readBuffer[1024];
char writeBuffer[1024]="hello srv,i'm from client!";
if( write(cliSocket,writeBuffer,strlen(writeBuffer) ) <0){
perror("write error! procedure will exit!");
return 0;
}//连接上服务端之后 直接发送一条消息
memset(readBuffer,0,sizeof(readBuffer));
memset(writeBuffer,0,sizeof(writeBuffer));
//从connSocket中读取数据 直到读取不到未知
while( read(cliSocket,readBuffer,sizeof(readBuffer))>0){
cout<<"srv: "<<readBuffer<<endl;
cin>>writeBuffer;
if( write(cliSocket,writeBuffer,strlen(writeBuffer) ) <0){
perror("write error! procedure will exit!");
return 0;
}
memset(readBuffer,0,sizeof(readBuffer));
memset(writeBuffer,0,sizeof(writeBuffer));
}
cout<<"srv is close,chat will exit"<<endl;
close(cliSocket);
return 0;
修改系统临时端口 只剩下50001
ketonghe@ubuntu:~/code$ sudo sysctl -w net.ipv4.ip_local_port_range="50001 50001"
net.ipv4.ip_local_port_range = 50001 50001
ketonghe@ubuntu:~/code$ netstat -anpl|grep 50001 ---检查没人占用
(Not all processes could be identified, non-owned process info
will not be shown, you would have to be root to see it all.)
开启tcpdump抓包
sudo tcpdump -i any port 50001 -nn -U -vvv -w tcpSelfConn.pcap
查看netstat 发现自己连接上自己了
ketonghe@ubuntu:~/code$ netstat -anpl|grep 50001
(Not all processes could be identified, non-owned process info
will not be shown, you would have to be root to see it all.)
tcp 0 0 192.168.3.66:50001 192.168.3.66:50001 ESTABLISHED 86363/./client
client程序运行输出
ketonghe@ubuntu:~/code$ ./client
srv: hello srv,i'm from client!
aaaaaaa
srv: aaaaaaa
^C
wireshark查看抓包
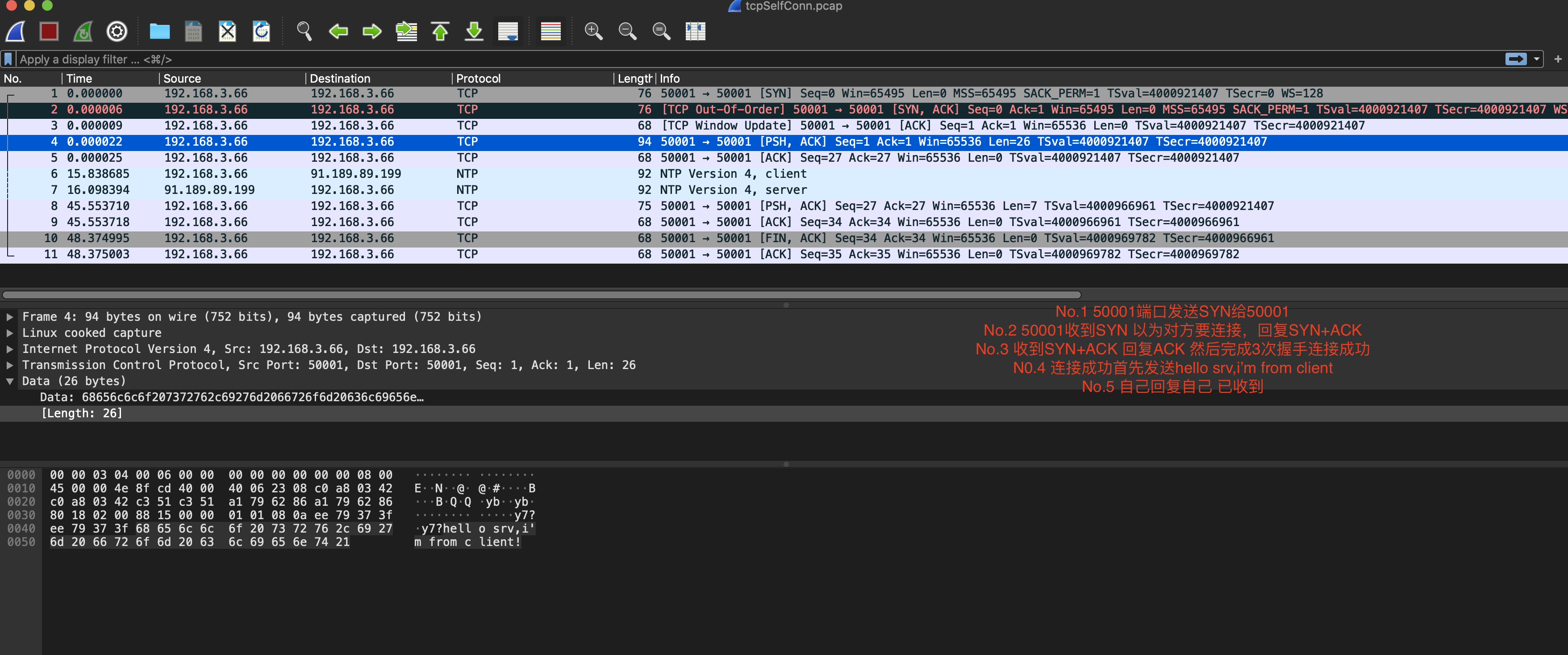
自连接可能发生的真实场景
- 你写的业务系统 B 会访问本机服务 A,服务 A 监听了 50001 端口
- 业务系统 B 的代码写的稍微比较健壮,增加了对服务 A 断开重连的逻辑
- 如果有一天服务 A 挂掉比较长时间没有启动,业务系统 B 开始不断 connect 重连
- 系统 B 经过一段时间的重试就会出现自连接的情况
- 这时服务 A 想启动监听 50001 端口就会出现地址被占用的异常,无法正常启动
自连接的危害
- 自连接的进程占用了端口,导致真正需要监听端口的服务进程无法监听成功
- 自连接的进程看起来 connect 成功,实际上服务是不正常的,无法正常进行业务数据通信(自己发给自己的)
如何避免自然连接
-
让服务监听的端口与客户端随机分配的端口不可能相同即可
-
出现自连接的时候,主动关掉连接
判断是否是自连接的逻辑是判断源 IP 和目标 IP 是否相等,源端口号和目标端口号是否相等 如果都相等 直接close掉
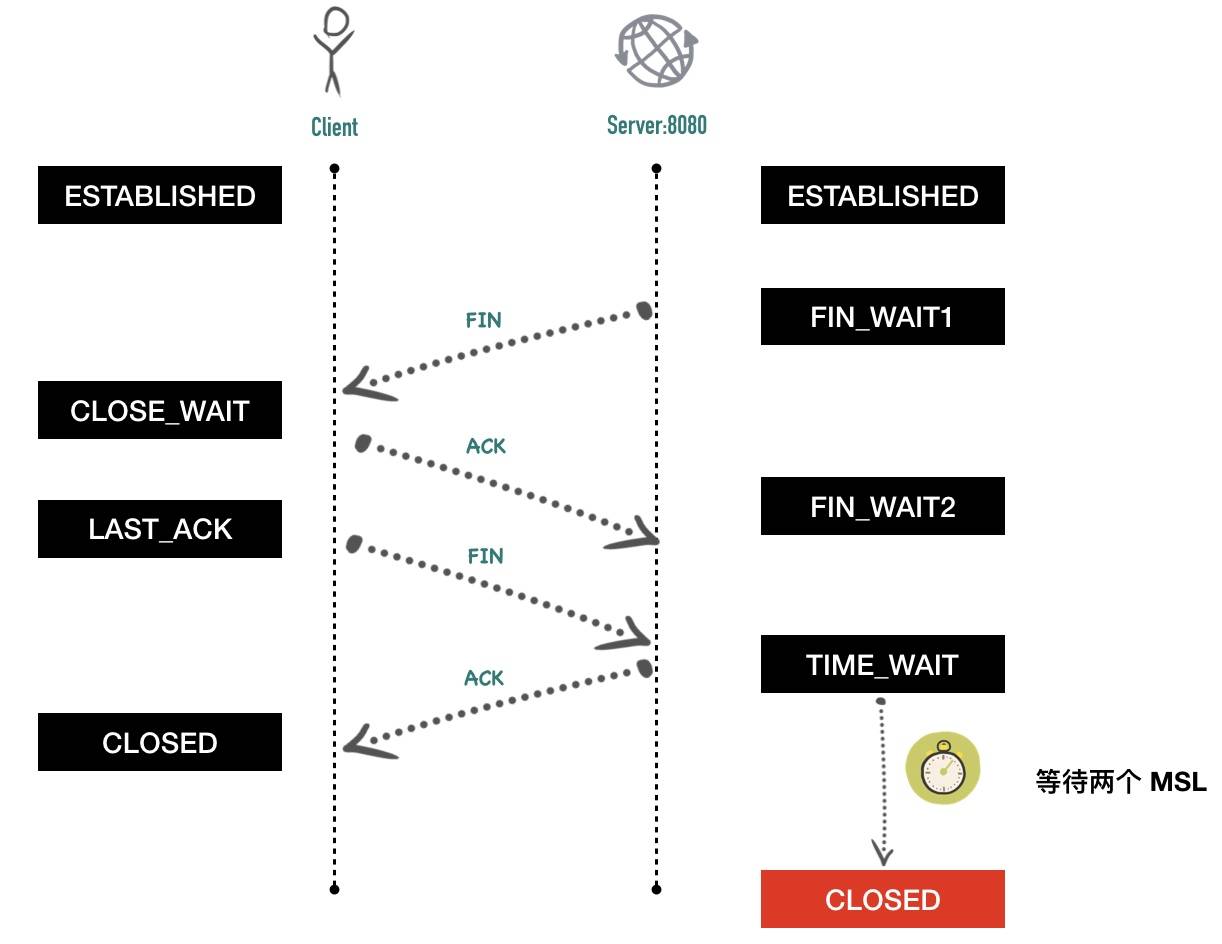
断开四次挥手
最常见的断开4次挥手
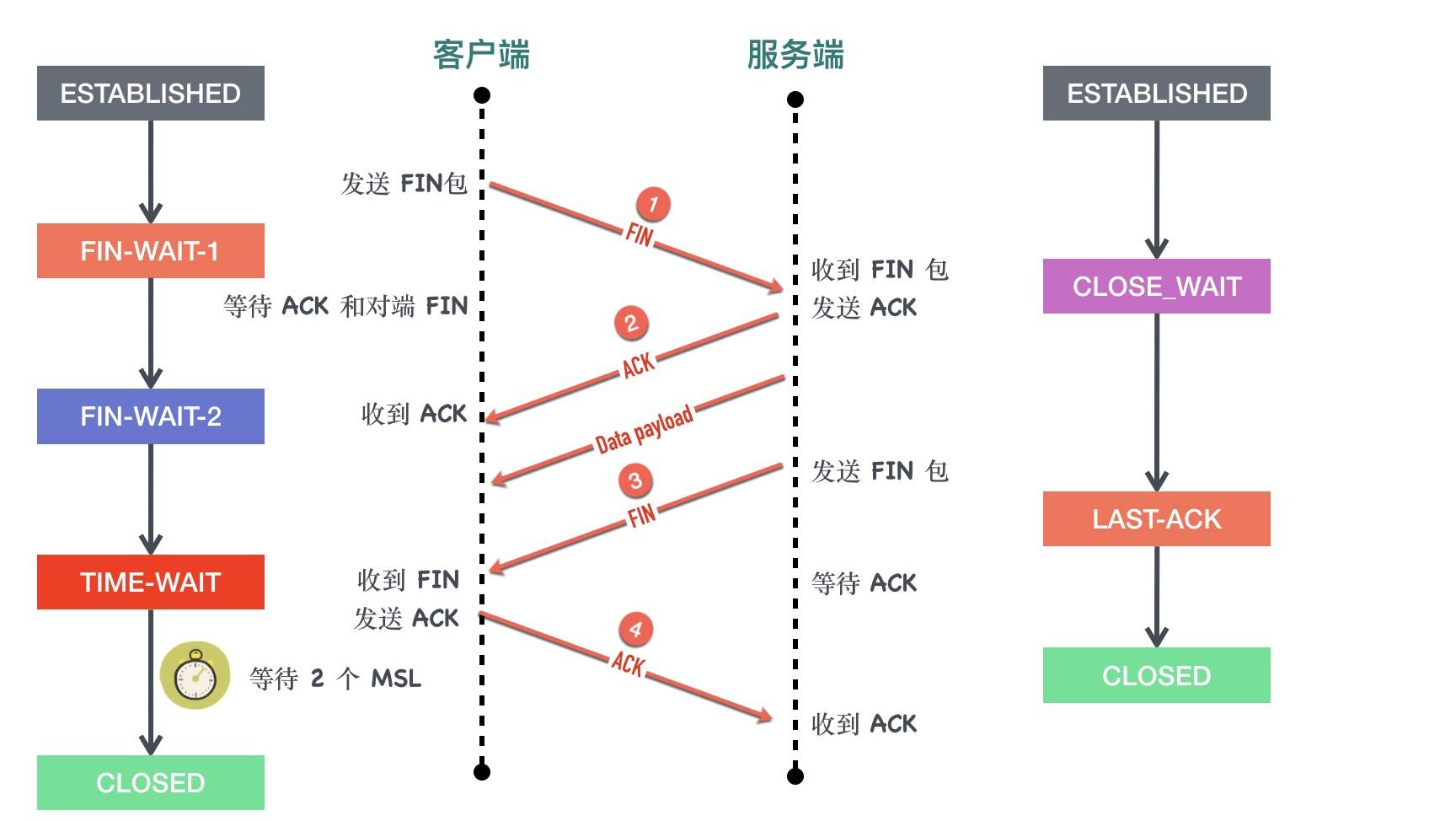
- 客户端调用
close方法,执行「主动关闭」,会发送一个 FIN 报文给服务端,从这以后客户端不能再发送数据给服务端了,客户端进入FIN-WAIT-1状态。FIN 报文其实就是将 FIN 标志位设置为 1,此时客户端需要等待服务端的ACK和FIN包,close发送的FIN包可以携带数据,也可以不携带,但都消耗序列号,因为需要对方确认。发送FIN后不能再发送数据,单可以接受服务端的数据。也就是半关闭状态(half–close) - 服务端收到客户端的FIN包,立马发送ACK给客户端,然后自己进入CLOSE_WAIT状态
- 客户端收到服务端的ACK后 客户端进入FIN_WAIT2状态(等待服务端发送FIN) 这个时候还可以收数据。
- 服务端确认没有数据发送了 就发送FIN包,然后进入LAST_ACK状态(最后等待客户端发送ACK),这个时候服务端也不能再发送数据了
- 客户端收到服务端的FIN,自己也发送ACK给服务端,然后客户端进入TIME_WAIT状态(等待2个MSL后进入CLOSED状态)
- 服务端收到客户端最后的ACK 进入CLOSED状态
4次挥手是否可以变成3次
- 如果服务端收到客户端的FIN包后 确认自己没有数据要发送 也是可以将服务端的ACK和FIN包一起发送的(延迟ACK的时候也可能出现这种情况)
客户端服务端同时关闭
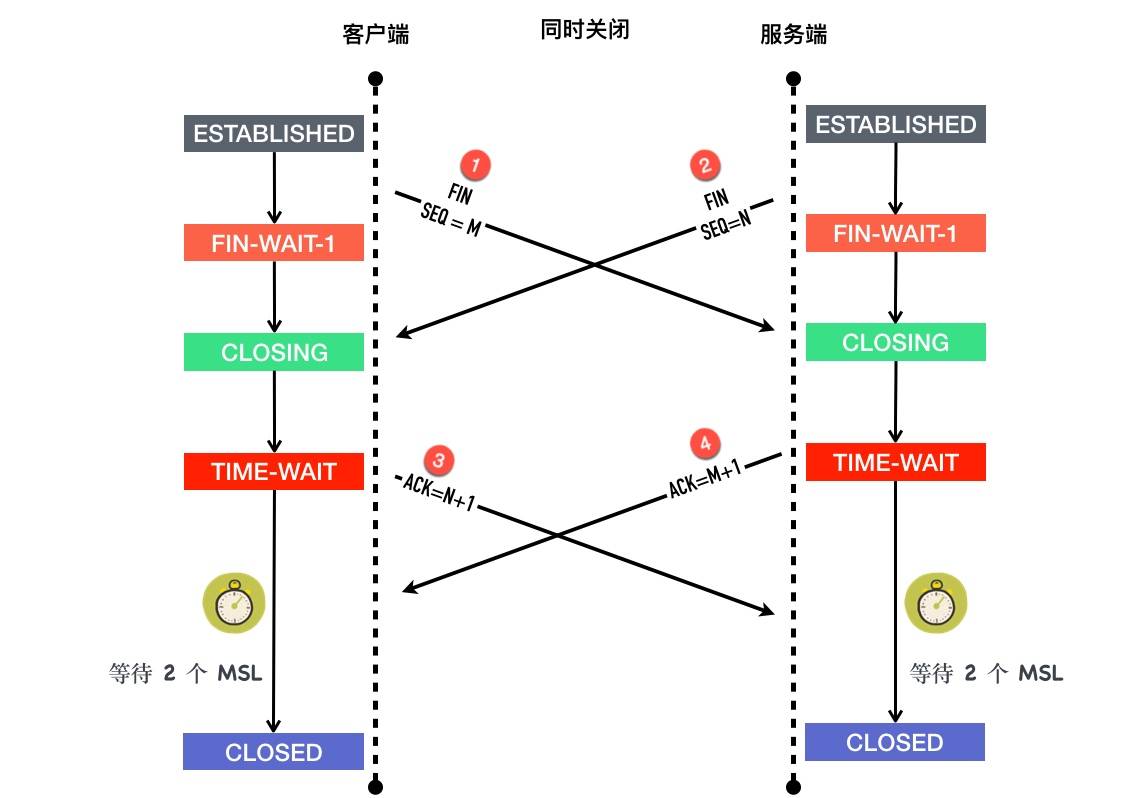
以客户端为例
- 最初客户端和服务端都处于 ESTABLISHED 状态
- 客户端发送
FIN包,等待对端对这个 FIN 包的 ACK,随后进入FIN-WAIT-1状态 - 处于
FIN-WAIT-1状态的客户端还没有等到 ACK,收到了服务端发过来的 FIN 包 - 收到 FIN 包以后客户端会发送对这个 FIN 包的的确认 ACK 包,同时自己进入
CLOSING状态 - 继续等自己 FIN 包的 ACK
- 处于
CLOSING状态的客户端终于等到了ACK,随后进入TIME-WAIT - 在
TIME-WAIT状态持续 2*MSL,进入CLOSED状态
发送FIN包后进入FIN_WAIT1状态(等待对方发送发送ACK和FIN),如果这个时候对方不发送ACK,先收到对方发送的FIN,就知道对方不会发送数据了 也就进入了CLOSING状态。
这个时候还要等待对方发送ACK,如果收到了ACK就进入TIME_WAIT状态(等待2个MSL进入CLSOSED状态)
服务端也是一样的。
A方发送FIN包之前,如果有收到对方B的FIN包则只有B会进入TIME_WAIT,否则会出现双方都TIME_WAIT状态
TCP头部时间戳选项(TCP Timestamps Option,TSopt)
TCP协议里面有选项(Options)、填充(Padding),其中TSopt也就是时间戳选项也是一个比较重要的选项
Timestamps 选项最初是在 RFC 1323 中引入的,这个 RFC 的标题是 “TCP Extensions for High Performance”,在这个 RFC 中同时提出的还有 Window Scale、PAWS 等机制
组成部分说明
在 Wireshark 抓包中,常常会看到 TSval 和 TSecr 两个选项,值得注意的是第二个选项 TSecr 不是 secrets 的意思,而是 “TS Echo Reply” 的缩写,TSval 和 TSecr 是 TCP 选项时间戳的一部分。
TCP Timestamps Option 由四部分构成:类别(kind)、长度(Length)、发送方时间戳(TS value)、回显时间戳(TS Echo Reply)。时间戳选项类别(kind)的值等于 8,用来与其它类型的选项区分。长度(length)等于 10。两个时间戳相关的选项都是 4 字节
-
是否使用时间戳选项实在连接的SYN包时候确定的,当然需要双方都支持才行,只要有一方没有回复就都不再发送时间戳选项
-
curl github.com抓包结果
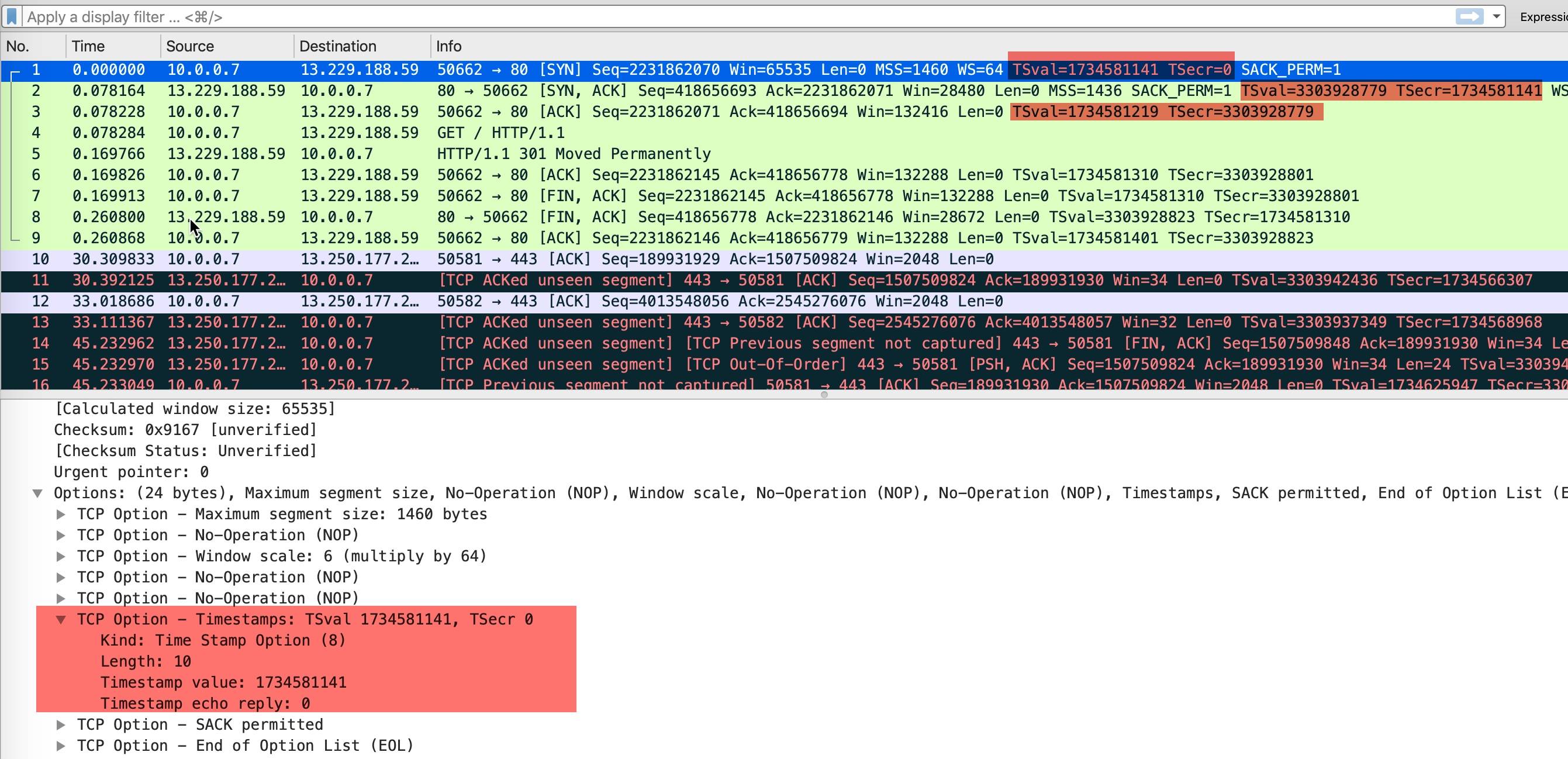
-
发送方发送数据时,将一个发送时间戳 1734581141 放在发送方时间戳
TSval中 -
接收方收到数据包以后,将收到的时间戳 1734581141 原封不动的返回给发送方,放在
TSecr字段中,同时把自己的时间戳 3303928779 放在TSval中 -
后面的包以此类推
-
TSVal就是发送的时间 TSecr是本次发送的包是回复的对方哪个时间点发送的报文
-
解决问题
Timestamps 选项的提出初衷是为了解决两个问题:
1、两端往返时延测量(RTTM)
因为知道了一个报文的发送时间和收到应答时间 就可以准确的确定中间经过的时间
2、序列号回绕(PAWS)
内核会为每个连接维护一个 ts_recent 值,记录最后一次通信的的 timestamps 值,如果收到的报文的时间戳小于ts_recent ,则会直接丢弃。
时间戳选项也可能造成RST
三次握手中的第二步,如果服务端回复 SYN+ACK 包中的 TSecr 不等于握手第一步客户端发送 SYN 包中的 TSval,客户端在对 SYN+ACK 回复 RST。示例包如下所示:

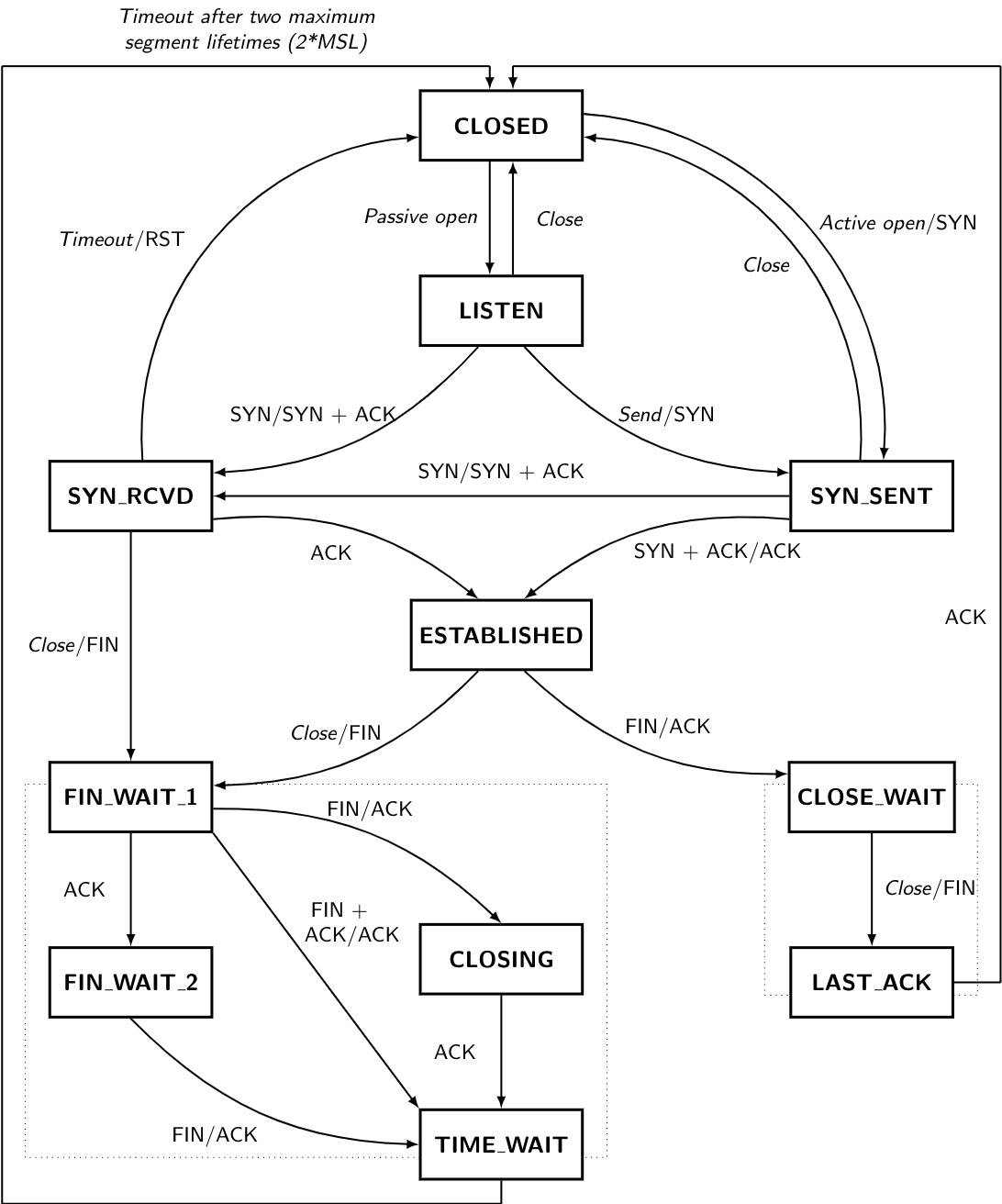
TCP11种状态变迁图
11状态变迁图
半连接队列、全连接队列、backlog
基本概念解读
-
当服务端调用listen函数之后,tcp状态有CLOSE变为LISTEN,同时内核创建了2个队列
- 半连接队列(Incomplete connection queue) 又称SYN队列
- 全连接队列(Incomplete connection queue) 又称Accept队列
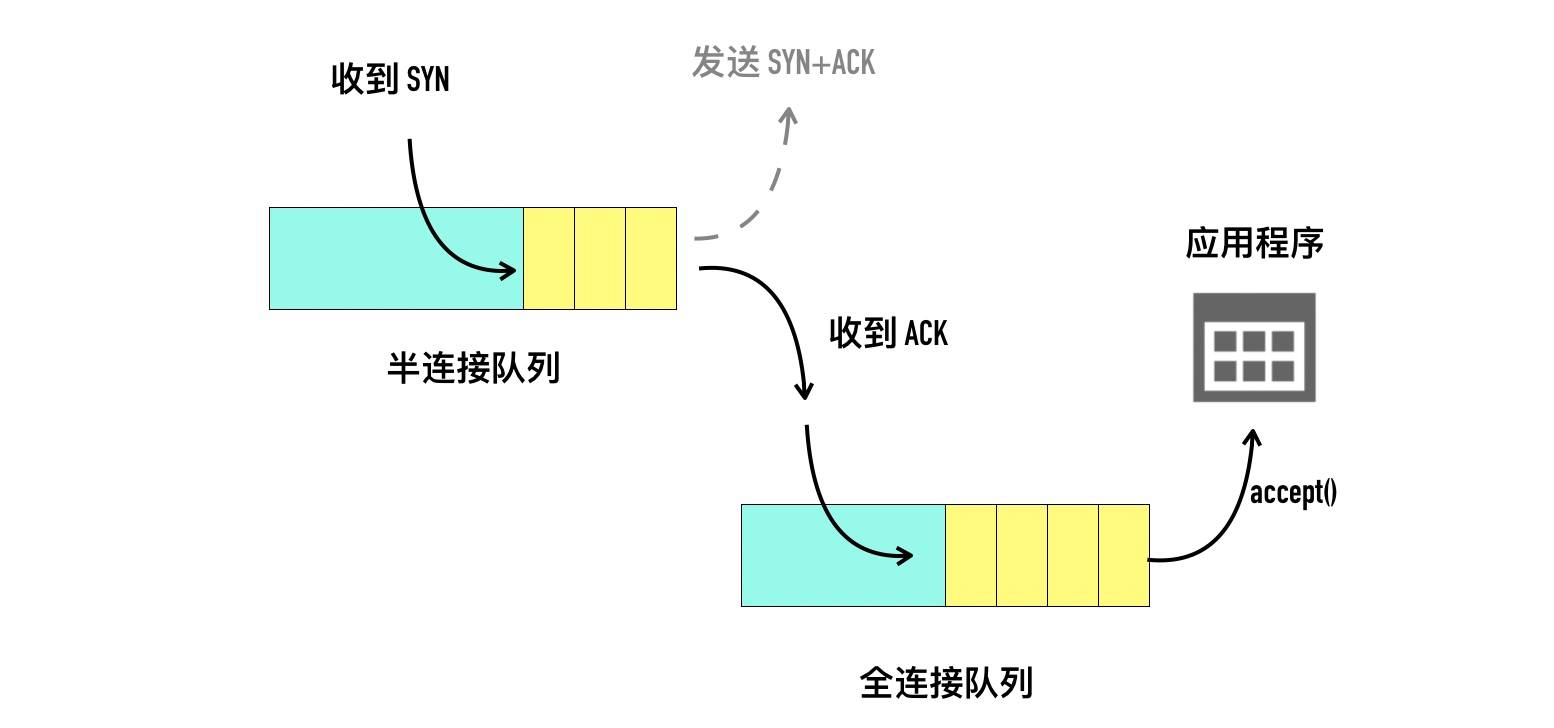
-
当客户端调用connect函数后 内核发送SYN包给服务端,服务端收到后会 回复ACK和自己的SYN,服务器的状态会由listen变为SYN_RCVD(SYN Received),此时会将这条连接信息放入 SYN半连接队列,存储的是“inbound SYN packets”,入境的SYN包
-
服务端回复SYN+ACK后等待客户端回复ACK,也会开启定时器,如果超时收不到客户端的ACK,就会重发SYN+ACK,重发次数为配置参数,tcp_synack_retries,一旦收到客户端的ACK,服务端就尝试将它加入全连接队列(Accept Queue)—除非队列满了
半连接队列大小计算
与三个内容有关系
- 服务端调用listen函数传入的backlog
- 系统变量net.ipv4.tcp_max_syn_backlog 默认128
- 系统变量 net.core.somaxconn
具体计算逻辑:
1. nr_table_entries= min(backlog、net.ipv4.tcp_max_syn_backlog、net.core.somaxconn)
取3者中最小值 赋值给nr_table_entries
2. nr_table_entries=max(nr_table_entries,8) //跟8比较取最大值
3. nr_table_entries + 1 向上取求最接近的最大 2 的指数次幂
nr_table_entries = roundup_pow_of_two(nr_table_entries + 1);
4. 通过 for 循环找不大于 nr_table_entries 最接近的 2 的对数值 结果为max_qlen_log
for (lopt->max_qlen_log = 3;
(1 << lopt->max_qlen_log) < nr_table_entries;
lopt->max_qlen_log++);
5. 半连接队列大小为 2^max_qlen_log
例子:
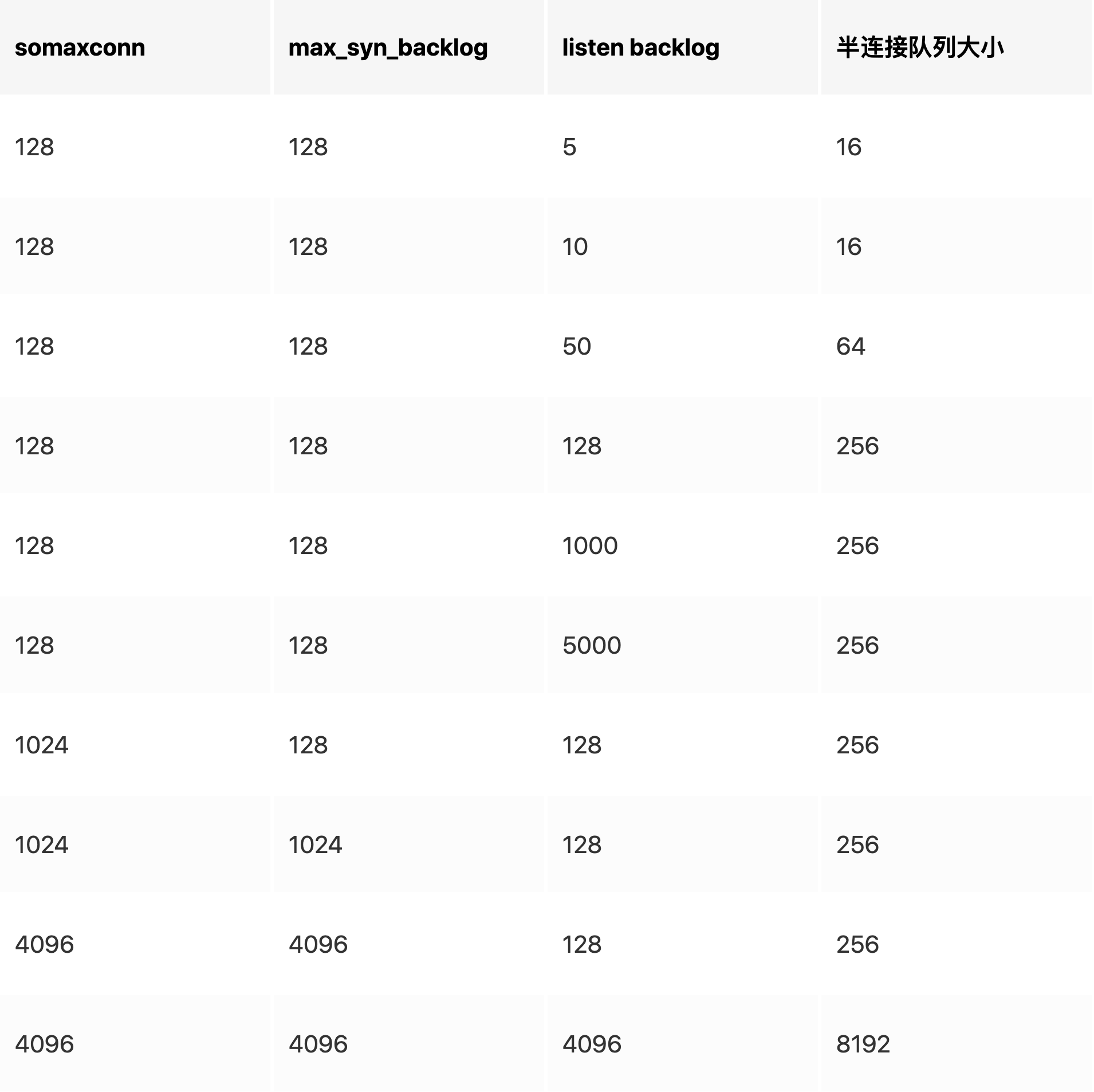
- 在系统参数不修改的情形,盲目调大 listen 的 backlog 对最终半连接队列的大小不会有影响。
- 在 listen 的 backlog 不变的情况下,盲目调大 somaxconn 和 max_syn_backlog 对最终半连接队列的大小不会有影响
如果半连接队列满了会怎么办
当半连接队列溢出时,Server 收到了新的发起连接的 SYN:
- 如果不开启
net.ipv4.tcp_syncookies:直接丢弃这个 SYN - 如果开启net.ipv4.tcp_syncookies
- 如果全连接队列满了,并且
qlen_young的值大于 1:丢弃这个 SYN - 否则,生成 syncookie 并返回 SYN/ACK 包
- 如果全连接队列满了,并且
全连接队列大小计算
- backlog 和 somaxconn 中的较小值
关于ss命令
ss -lnt | grep :9090
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 51 50 *:9090 *:*
- 处于 LISTEN 状态的 socket,Recv-Q 对应 sk_ack_backlog,表示当前 socket 的完成三次握手等待用户进程 accept 的连接个数,Send-Q 对应 sk_max_ack_backlog,表示当前 socket 全连接队列能最大容纳的连接数
- 对于非 LISTEN 状态的 socket,Recv-Q 表示 receive queue 的字节大小,Send-Q 表示 send queue 的字节大小
backlog多大才合适
- 你如果的接口处理连接的速度要求非常高,或者在做压力测试,很有必要调高这个值
- 如果业务接口本身性能不好,accept 取走已建连的速度较慢,那么把 backlog 调的再大也没有用,只会增加连接失败的可能性
Nginx 和 Redis 默认的 backlog 值等于 511,Linux 默认的 backlog 为 128。
全连接队列满了怎么办
默认情况下,全连接队列满以后,服务端会忽略客户端的 ACK,随后会重传SYN+ACK,也可以修改这种行为,这个值由/proc/sys/net/ipv4/tcp_abort_on_overflow决定。
- tcp_abort_on_overflow 为 0 表示三次握手最后一步全连接队列满以后 server 会丢掉 client 发过来的 ACK,服务端随后会进行重传 SYN+ACK。
- tcp_abort_on_overflow 为 1 表示全连接队列满以后服务端直接发送 RST 给客户端。
但是回给客户端 RST 包会带来另外一个问题,客户端不知道服务端响应的 RST 包到底是因为「该端口没有进程监听」,还是「该端口有进程监听,只是它的队列满了」
SYN flood攻击
客户端大量伪造 IP 发送 SYN 包,服务端回复的 ACK+SYN 去到了一个「未知」的 IP 地址,势必会造成服务端大量的连接处于 SYN_RCVD 状态,而服务器的半连接队列大小也是有限的,如果半连接队列满,也会出现无法处理正常请求的情况。
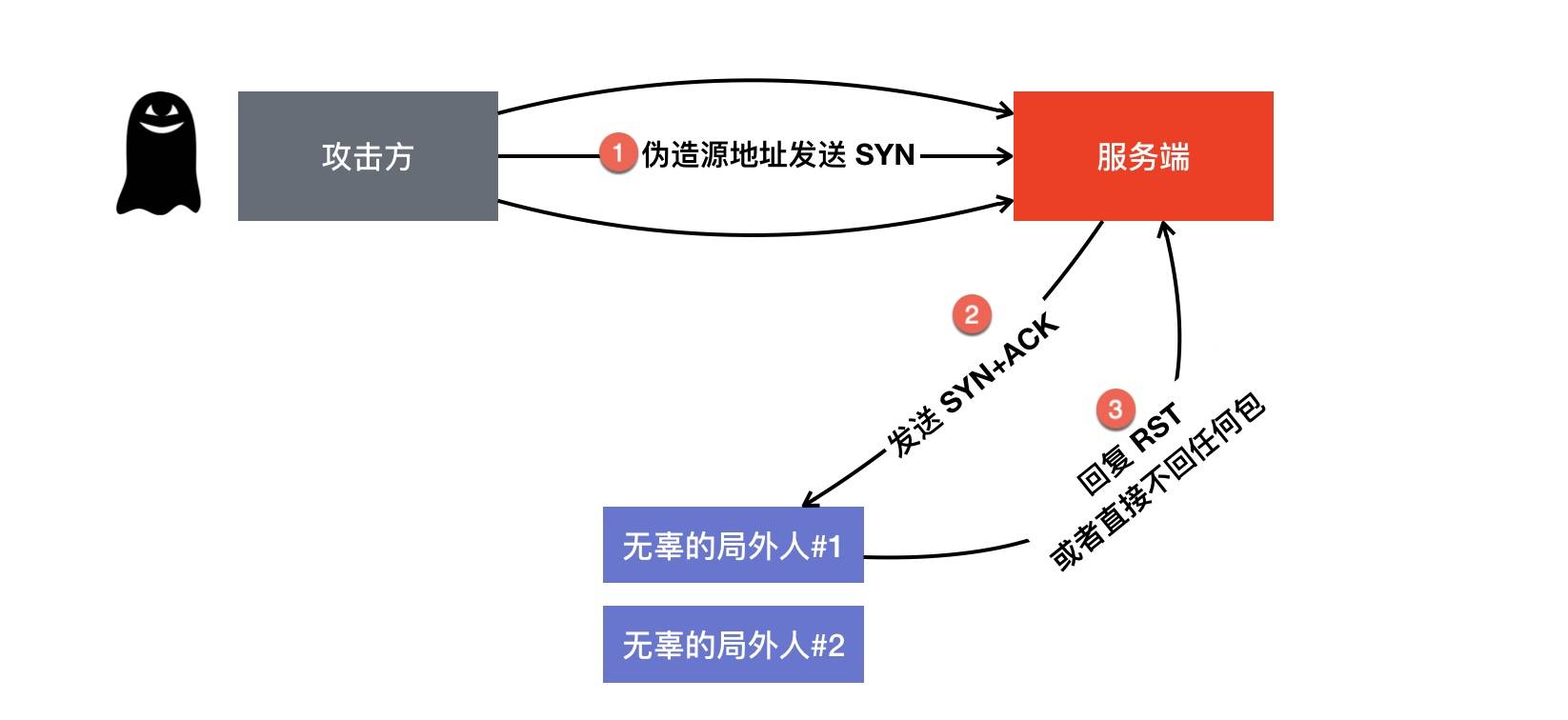
如何发现或者监控SYN Flood
- 监控日常活跃连接数 如果大幅增加而且大量SYN_RECV状态的连接 可能就是有问题
如何防范及应急
-
net.ipv4.tcp_max_syn_backlog调大 同时listen时候的backlog也调大,目的是增大SYN半连接队列内存
-
减少服务端SYN+ACK重试次数 应急时候可以将/proc/sys/net/ipv4/tcp_synack_retries改为0 因为真正的客户端必经还以重发SYN。
-
开启tcp_syncookies
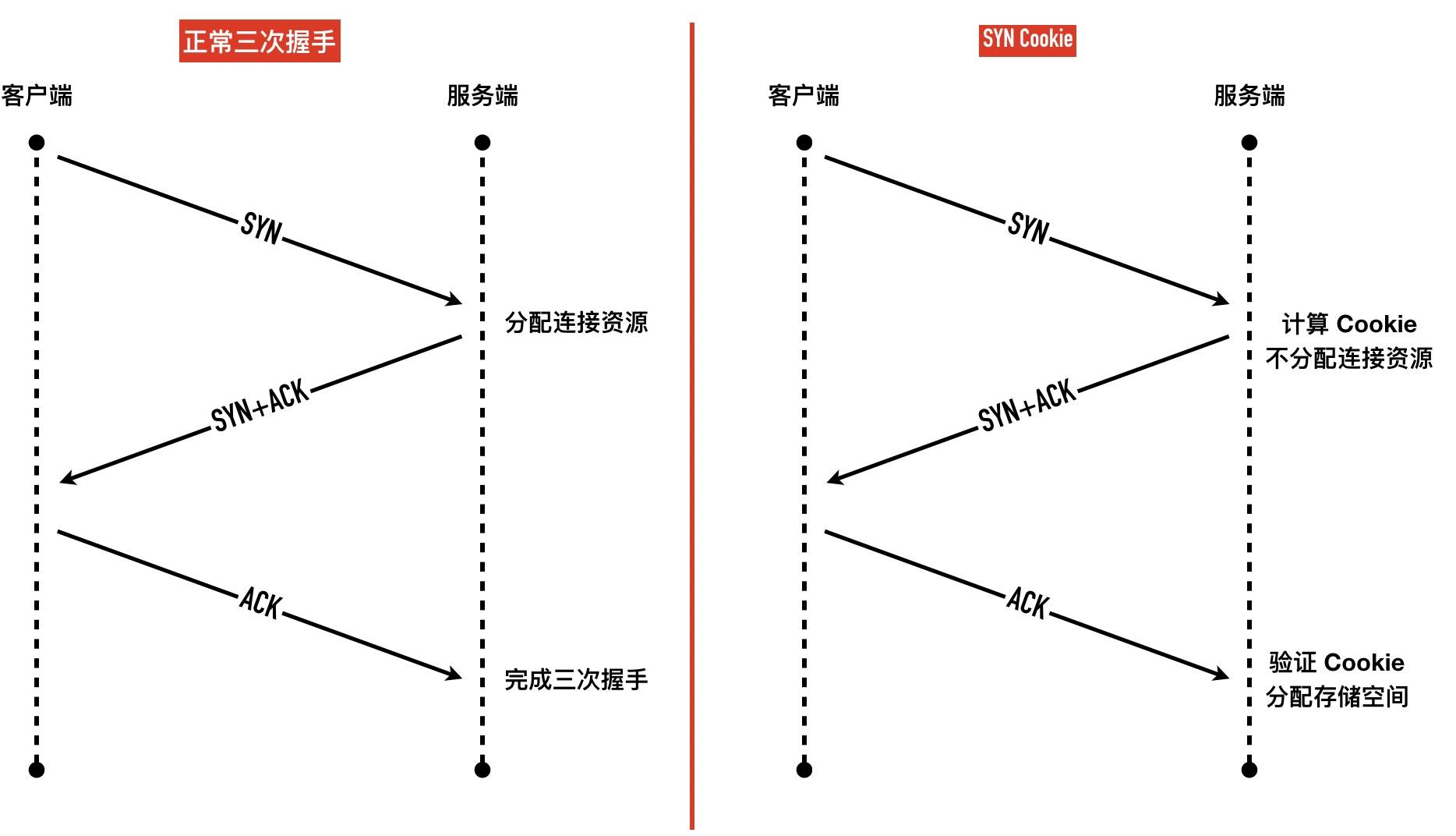
SYN Cookie 的原理是基于「无状态」的机制,服务端收到 SYN 包以后不马上分配为
Inbound SYN分配内存资源,而是根据这个 SYN 包计算出一个 Cookie 值,作为握手第二步的序列号回复 SYN+ACK,等对方回应 ACK 包时校验回复的 ACK 值是否合法,如果合法才三次握手成功,分配连接资源 -
如果发现攻击后能给确定非法ip 也可以直接iptable限制这些ip 效果非常明显
-
外围增加F5等负载均衡利器,只有真正连接上的请求才转发给服务器
TCP Fast Open TFO TCP快速打开
TFO 是在原来 TCP 协议上的扩展协议,它的主要原理就在发送第一个 SYN 包的时候就开始传数据了,
不过它要求当前客户端之前已经完成过「正常」的三次握手。快速打开分两个阶段:请求 Fast Open Cookie 和 真正开始 TCP Fast Open
- TFO与非TFO的对比
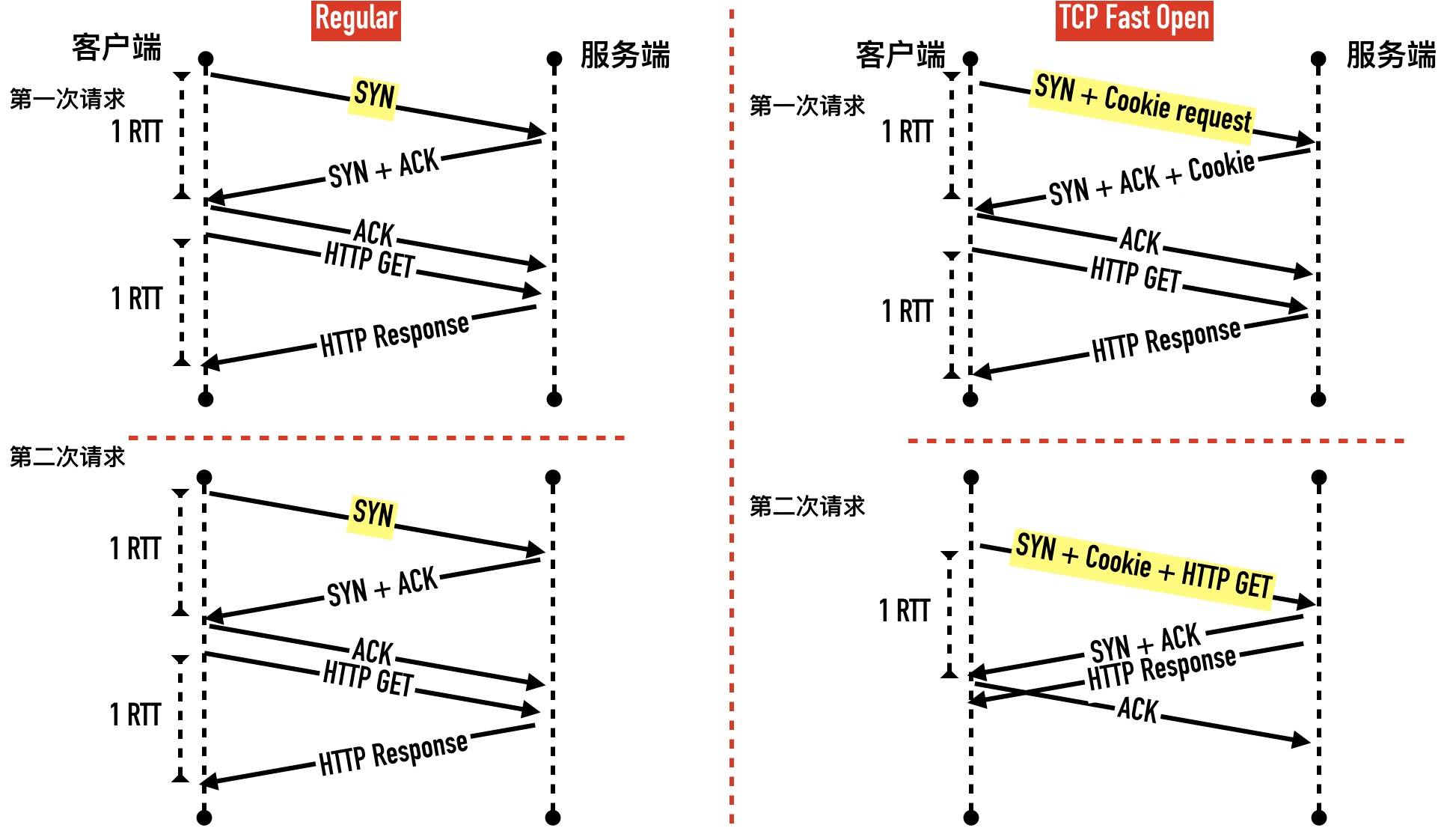
- 优势就是后续的连接 tcp交互次数更少 效率更快 也可以有一定预防SYN Flood
- 代码如果要使用 要调用sendto函数 同时设置MSG_FASTOPEN flag
小结
- 客户端发送一个 SYN 包,头部包含 Fast Open 选项,且该选项的 Cookie 长度为 0
- 服务端根据客户端 IP 生成 cookie,放在 SYN+ACK 包中一同发回客户端
- 客户端收到 Cookie 以后缓存在自己的本地内存
- 客户端再次访问服务端时,在 SYN 包携带数据,并在头部包含 上次缓存在本地的 TCP cookie
- 如果服务端校验 Cookie 合法,则在客户端回复 ACK 前就可以直接发送数据。如果 Cookie 不合法则按照正常三次握手进行。
Address already in use SO_REUSEADDR
背景
-
如果服务器退出或者崩溃导致服务器先close,那么服务端就会出现TIME_WAIT状态,需要等待2个MSL才能最终释放连接
如果这个时候立马启动服务器程序,就会出现address already in use的错误。
-
并不是服务端只有处于TimeWait才有用 处于Fin_WAIT2也是可以的
为什么通常不会在客户端出现
因为客户端每次都是随机的临时端口,所以一般不会出现
SO_REUSEPORT 多个进程监听同一个端口
默认情况下,一个 IP、端口组合只能被一个套接字绑定,Linux 内核从 3.9 版本开始引入一个新的 socket 选项 SO_REUSEPORT,又称为 port sharding,允许多个套接字监听同一个IP 和端口组合
充分发挥多核CPU的性能,多进程处理网络请求的方式可以有下面2个方式
-
主进程 + 多个 worker 子进程监听相同的端口
-
多进程 + REUSEPORT
第一种方最常用的一种模式,Nginx 默认就采用这种方式。主进程执行 bind()、listen() 初始化套接字,然后 fork 新的子进程。在这些子进程中,通过 accept/epoll_wait 同一个套接字来进行请求处理,但会带来惊群问题(thundering herd)
惊群问题 thundering herd
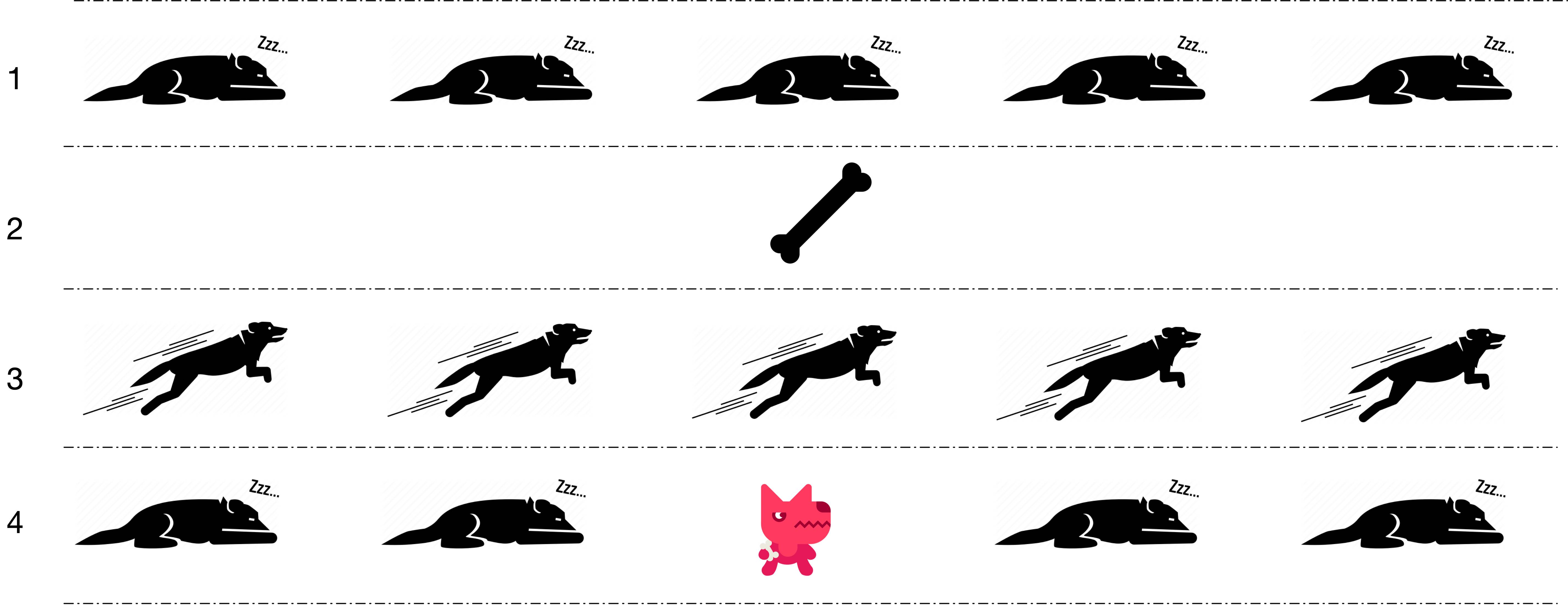
明明只有一块骨头只够一条小狗吃,五只小狗却一起从睡眠中醒来争抢,对于没有抢到小狗来说,浪费了很多精力
- 计算机中的惊群问题指的是:多进程/多线程同时监听同一个套接字,当有网络事件发生时,所有等待的进程/线程同时被唤醒,但是只有其中一个进程/线程可以处理该网络事件,其它的进程/线程获取失败重新进入休眠
- 惊群问题带来的是 CPU 资源的浪费和锁竞争的开销。根据使用方式的不同,Linux 上的网络惊群问题分为 accept 惊群和 epoll 惊群两种,linux内核2.6 版本中引入了 WQ_FLAG_EXCLUSIVE 选项解决了 accept 调用的惊群问题(非epoll 多进程直接accept)
epoll惊群
epoll 典型的工作模式是父进程执行 bind、listen 以后 fork 出子进程,使用 epoll_wait 等待事件发生,模式如下图所示:
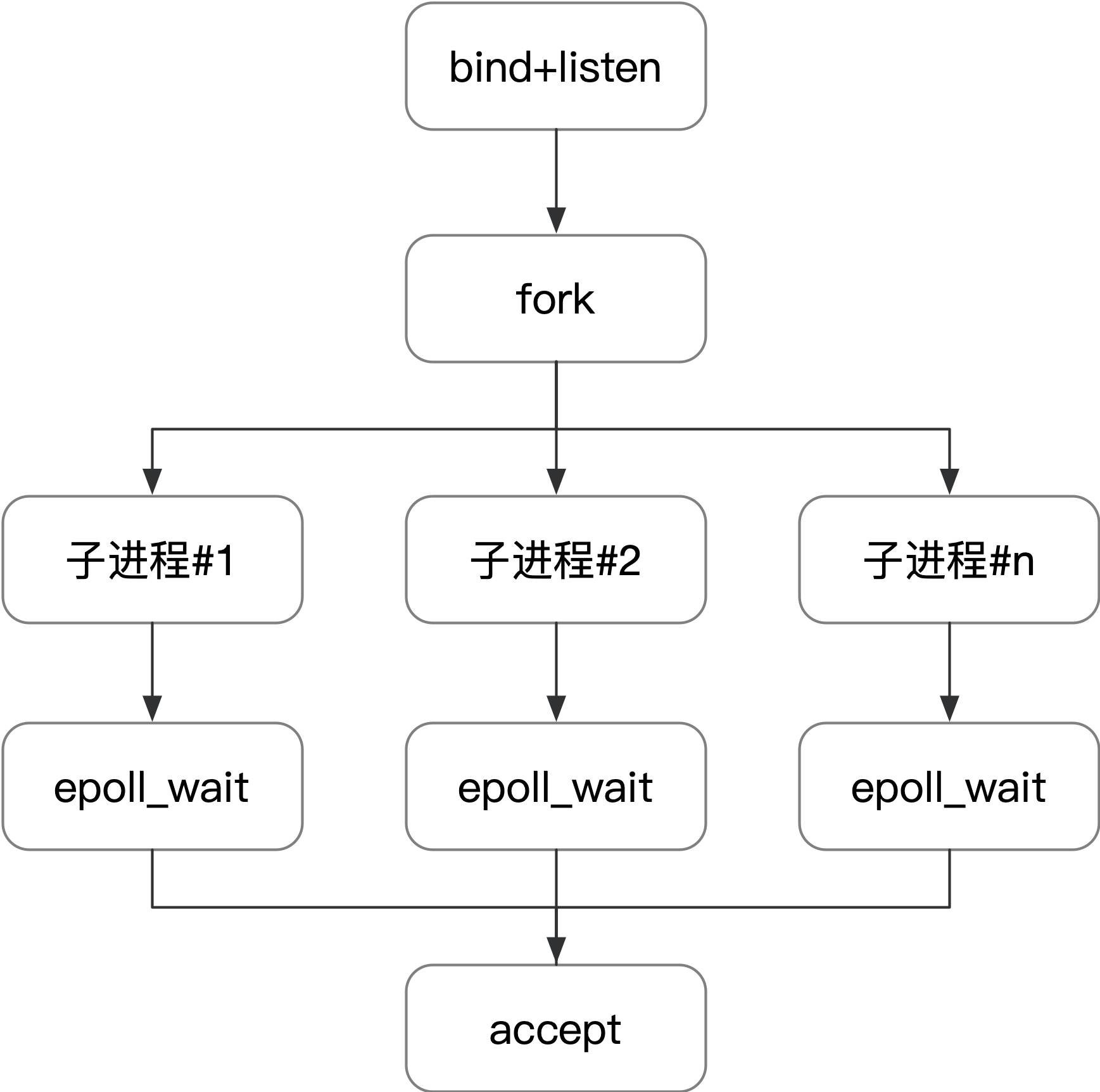
示例代码
int main(void) {
// ...
sock_fd = create_and_bind("9090");
listen(sock_fd, SOMAXCONN);
epoll_fd = epoll_create(1);
event.data.fd = sock_fd;
event.events = EPOLLIN;
epoll_ctl(epoll_fd, EPOLL_CTL_ADD, sock_fd, &event);
events = calloc(MAXEVENTS, sizeof(event));
for (int i = 0; i < 4; i++) {
if (fork() == 0) {
while (1) {
int n = epoll_wait(epoll_fd, events, MAXEVENTS, -1);
printf("return from epoll_wait, pid is %d\n", getpid());
sleep(2);
for (int j = 0; j < n; j++) {
if ((events[i].events & EPOLLERR) || (events[i].events & EPOLLHUP) ||
(!(events[i].events & EPOLLIN))) {
close(events[i].data.fd);
continue;
} else if (sock_fd == events[j].data.fd) {
struct sockaddr sock_addr;
socklen_t sock_len;
int conn_fd;
sock_len = sizeof(sock_addr);
conn_fd = accept(sock_fd, &sock_addr, &sock_len);
if (conn_fd == -1) {
printf("accept failed, pid is %d\n", getpid());
break;
}
printf("accept success, pid is %d\n", getpid());
close(conn_fd);
}
}
}
}
}
-
查看进程打开具柄情况
ls -l /proc/24735/fd lrwx------. 1 ya ya 64 Jan 28 06:20 0 -> /dev/pts/2 lrwx------. 1 ya ya 64 Jan 28 06:20 1 -> /dev/pts/2 lrwx------. 1 ya ya 64 Jan 28 00:10 2 -> /dev/pts/2 lrwx------. 1 ya ya 64 Jan 28 06:20 3 -> 'socket:[72919]' listen套接字 lrwx------. 1 ya ya 64 Jan 28 06:20 4 -> 'anon_inode:[eventpoll]' epollfd为了表示打开文件,linux 内核维护了三种数据结构,分别是:
- 内核为每个进程维护了一个其打开文件的「描述符表」(file descriptor table),我们熟知的 fd 为 0 的 stdin 就是属于文件描述符表。
- 内核为所有打开文件维护了一个系统级的「打开文件表」(open file table),这个打开文件表存储了当前文件的偏移量,状态信息和对 inode 的指针等信息,父子进程的 fd 可以指向同一个打开文件表项。
- 最后一个是文件系统的 inode 表(i-node table)
经过 for 循环的 fork,会生成 4 个子进程,这 4 个子进程会继承父进程的 fd。在这种情况下,对应的进程文件描述符表、打开文件表和 inode 表的关系如下图所示:
子进程的 epoll_wait 等待同一个底层的 open file table 项,当有事件发送时,会通知到所有的子进程
-
开启一个客户端连接
return from epoll_wait, pid is 25410 return from epoll_wait, pid is 25411 return from epoll_wait, pid is 25409 return from epoll_wait, pid is 25412 accept success, pid is 25410 accept failed, pid is 25411 accept failed, pid is 25409 accept failed, pid is 25412可以看到当有新的网络事件发生时,阻塞在 epoll_wait 的多个进程同时被唤醒。在这种情况下,epoll 的惊群还是存在,有不少的措施可以解决 epoll 的惊群。Nginx 为了处理惊群问题,在应用层增加了 accept_mutex 锁
当然也可以使用SO_REUSEPORT 选项
SO_REUSEPORT 选项
-
如果不加一个选项 同一个server程序 只能启动一次,否则机会提示失败
-
但加了这个选项 可以多个进程监听同一个端口
int optval = 1; setsockopt(sock_fd, SOL_SOCKET, SO_REUSEPORT, &optval, sizeof(optval)); -
启动2个服务器进程 查看端口情况
ketonghe@ubuntu:~/code$ ss -tlnpe | grep -i 8787 LISTEN 0 5 192.168.3.66:8787 0.0.0.0:* users:(("server",pid=88296,fd=3)) uid:1000 ino:1215520 sk:34b <-> LISTEN 0 5 192.168.3.66:8787 0.0.0.0:* users:(("server",pid=88294,fd=3)) uid:1000 ino:1215512 sk:34c <-> ketonghe@ubuntu:~/code$ netstat -anp|grep 8787 (Not all processes could be identified, non-owned process info will not be shown, you would have to be root to see it all.) tcp 0 0 192.168.3.66:8787 0.0.0.0:* LISTEN 88296/./server tcp 0 0 192.168.3.66:8787 0.0.0.0:* LISTEN 88294/./server -
ss命令介绍
-t, --tcp 显示 TCP 的 socket -l, --listening 只显示 listening 状态的 socket,默认情况下是不显示的。 -n, --numeric 显示端口号而不是映射的服务名 -p, --processes 显示进程名 -e, --extended 显示 socket 的详细信息
客户端连接来了分给谁?
linux4.5、4.6版本引入了SO_REUSEPORT group概念,在查找匹配的 socket 时,就不用遍历整条冲突链,对于设置了 SO_REUSEPORT 选项的 socket 经过二次哈希找到对应的 SO_REUSEPORT group
简单理解可以说是随机的。
SO_REUSEPORT与安全性
试想下面的场景,你的进程进程监听了某个端口,不怀好意的其他人也可以监听相同的端口来“窃取”流量信息,这种方式被称为端口劫持(port hijacking)。SO_REUSEPORT 在安全性方面的考虑主要是下面这两点。
1、只有第一个启动的进程启用了 SO_REUSEPORT 选项,后面启动的进程才可以绑定同一个端口。 2、后启动的进程必须与第一个进程的有效用户ID(effective user ID)匹配才可以绑定成功
SO_REUSEPORT 的应用
SO_REUSEPORT 带来了两个明显的好处:
-
实现了内核级的负载均衡
-
支持滚动升级(Rolling updates)
步骤如下所示。
- 新启动一个新版本 v2 ,监听同一个端口,与 v1 旧版本一起处理请求。
- 发送信号给 v1 版本的进程,让它不再接受新的请求
- 等待一段时间,等 v1 版本的用户请求都已经处理完毕时,v1 版本的进程退出,留下 v2 版本继续服务
SO_LINGER选项
TimeWait状态
MSL Max Segment lifetime
MSL(报文最大生存时间)是 TCP 报文在网络中的最大生存时间。这个值与 IP 报文头的 TTL 字段有密切的关系。
IP 报文头中有一个 8 位的存活时间字段(Time to live, TTL)如下图。 这个存活时间存储的不是具体的时间,而是一个 IP 报文最大可经过的路由数,每经过一个路由器,TTL 减 1,当 TTL 减到 0 时这个 IP 报文会被丢弃。

从上面可以看到 TTL 说的是「跳数」限制而不是「时间」限制,尽管如此我们依然假设最大跳数的报文在网络中存活的时间不可能超过 MSL 秒。Linux 的套接字实现假设 MSL 为 30 秒,因此在 Linux 机器上 TIME_WAIT 状态将持续 60秒
为什么要TIME_WAIT状态
避免当前关闭连接与后续连接混淆(让旧连接的包在网络中消逝)
数据报文可能在发送途中延迟但最终会到达,因此要等老的“迷路”的重复报文段在网络中过期失效,这样可以避免用相同源端口和目标端口创建新连接时收到旧连接姗姗来迟的数据包,造成数据错乱。
假设客户端 10.211.55.2 的 61594 端口与服务端 10.211.55.10 的 8080 端口一开始建立了一个 TCP 连接。
假如客户端发送完 FIN 包以后不等待直接进入 CLOSED 状态,老连接 SEQ=3 的包因为网络的延迟。过了一段时间相同的 IP 和端口号又新建了另一条连接,这样 TCP 连接的四元组就完全一样了。恰好 SEQ 因为回绕等原因也正好相同,那么 SEQ=3 的包就无法知道到底是旧连接的包还是新连接的包了,造成新连接数据的混乱。
TIME_WAIT 等待时间是 2 个 MSL,已经足够让一个方向上的包最多存活 MSL 秒就被丢弃,保证了在创建新的 TCP 连接以后,老连接姗姗来迟的包已经在网络中被丢弃消逝,不会干扰新的连接
确保可靠实现TCP全双工终止连接
-
关闭连接的四次挥手中,最终的 ACK 由主动关闭方发出,如果这个 ACK 丢失,对端(被动关闭方)将重发 FIN,如果主动关闭方不维持 TIME_WAIT 直接进入 CLOSED 状态,则无法重传 ACK,被动关闭方因此不能及时可靠释放
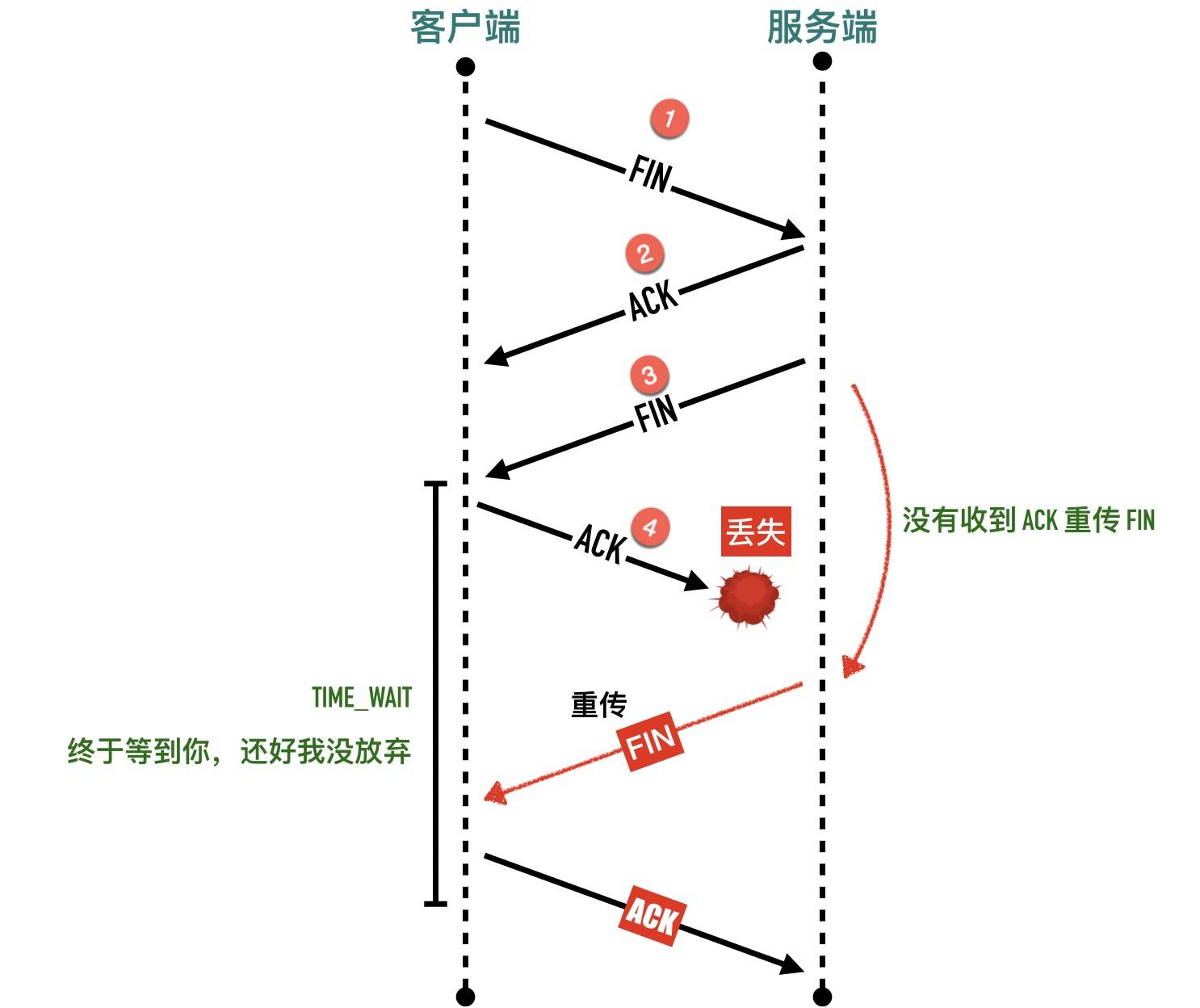
-
如果上述情况没有TIME_WAIT等待 直接CLOSED
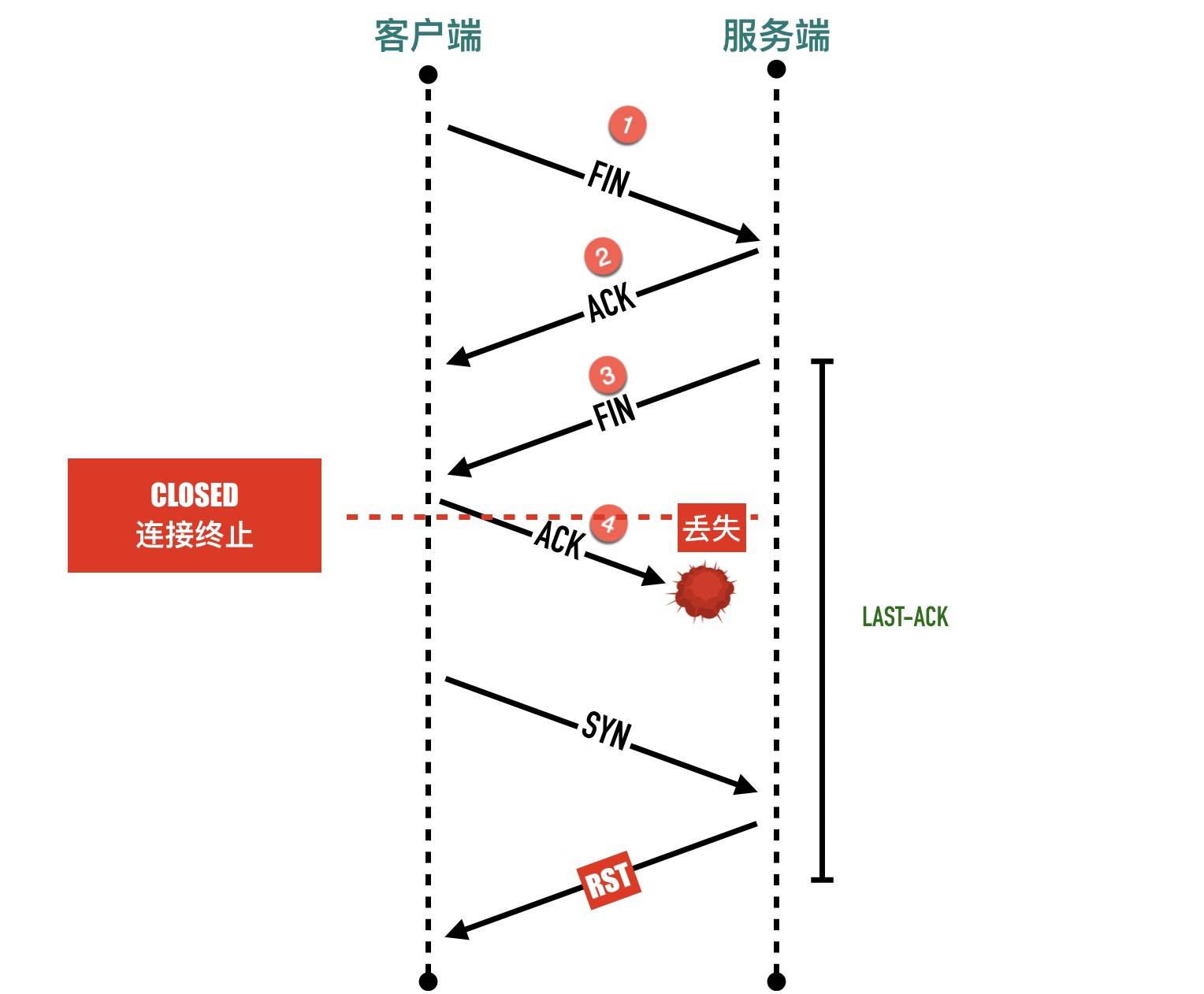
主动关闭方如果马上进入 CLOSED 状态,被动关闭方这个时候还处于LAST-ACK状态,主动关闭方认为连接已经释放,
端口可以重用了,如果使用相同的端口三次握手发送 SYN 包,会被处于 LAST-ACK状态状态的被动关闭方返回一个 RST,三次握手失败
为什么要2个MSL
- 1 个 MSL 确保四次挥手中主动关闭方最后的 ACK 报文最终能达到对端
- 1 个 MSL 确保对端没有收到 ACK 重传的 FIN 报文可以到达
2MS = 去向 ACK 消息最大存活时间(MSL) + 来向 FIN 消息的最大存活时间(MSL)
TIME_WAIT的问题
在一个非常繁忙的服务器上,如果有大量 TIME_WAIT 状态的连接会怎么样呢?
- 连接表无法复用
- socket 结构体内存占用
连接表无法复用 因为处于 TIME_WAIT 的连接会存活 2MSL(60s),意味着相同的TCP 连接四元组(源端口、源 ip、目标端口、目标 ip)在一分钟之内都没有办法复用,通俗一点来讲就是“占着茅坑不拉屎”。
在一台 Linux 机器上,端口最多是 65535 个( 2 个字节)。如果客户端与服务器通信全部使用短连接,不停的创建连接,接着关闭连接,客户端机器会造成大量的 TCP 连接进入 TIME_WAIT 状态,很有可能出现端口不够用的情况
应对TIME_WAIT
tcp_tw_reuse 选项
缓解紧张的端口资源,一个可行的方法是重用“浪费”的处于 TIME_WAIT 状态的连接,当开启 net.ipv4.tcp_tw_reuse 选项时,处于 TIME_WAIT 状态的连接可以被重用。下面把主动关闭方记为 A, 被动关闭方记为 B,它的原理是:
-
如果主动关闭方 A 收到的包时间戳比当前存储的时间戳小,说明是一个迷路的旧连接的包,直接丢弃掉
-
如果因为 ACK 包丢失导致被动关闭方还处于
LAST-ACK状态,并且会持续重传 FIN+ACK。这时 A 发送SYN 包想三次握手建立连接,此时 A 处于SYN-SENT阶段。当收到 B 的 FIN 包时会回以一个 RST 包给 B,B 这端的连接会进入 CLOSED 状态,A 因为没有收到 SYN 包的 ACK,会重传 SYN,后面就一切顺利了。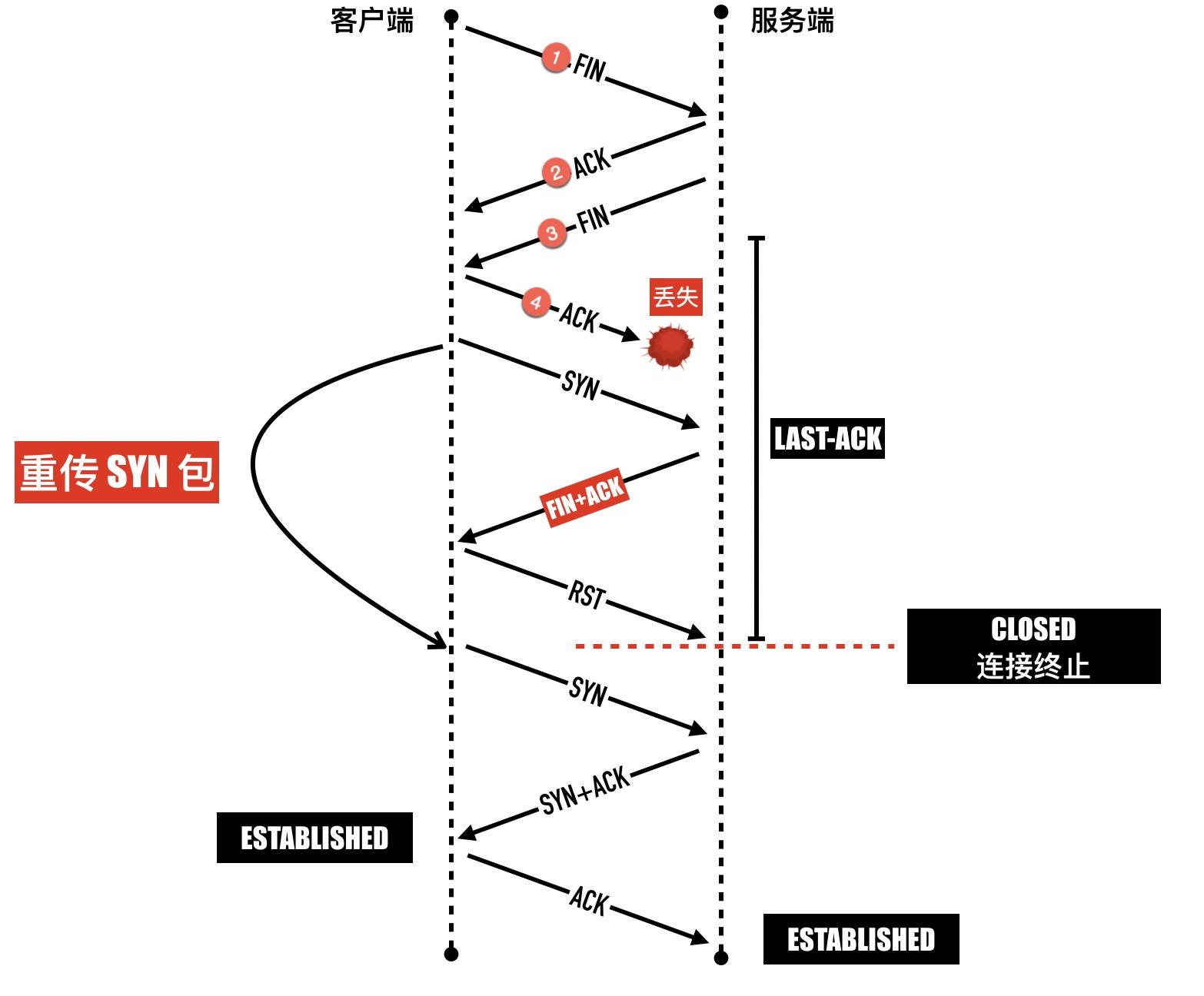
RST创建的几种情况
- 在tcp协议中,RST表示复位,用来异常的关闭连接,发送 RST 关闭连接时,不必等缓冲区的数据都发送出去,直接丢弃缓冲区中的数据,连接释放进入
CLOSED状态。而接收端收到 RST 段后,也不需要发送 ACK 确认。
端口未监听
-
这种情况很常见,比如 web 服务进程断电挂掉或者未启动,客户端使用 connect 建连,都会出现 “Connection Reset” 或者"Connection refused" 错误
-
这样机制可以用来检测对端端口是否打开,发送 SYN 包对指定端口,看会不会回复 SYN+ACK 包。如果回复了 SYN+ACK,说明监听端口存在,如果返回 RST,说明端口未对外监听,如下图所示
-
如果调用了close函数,设置SO_LINGER为true 也会出现close后丢掉缓冲区 直接发送RST包 重置连接,立马进入CLOSED状态
如果RST中途丢失了怎么办
-
如果另外一方没有收到RST会重试一定次数后 再次放弃。
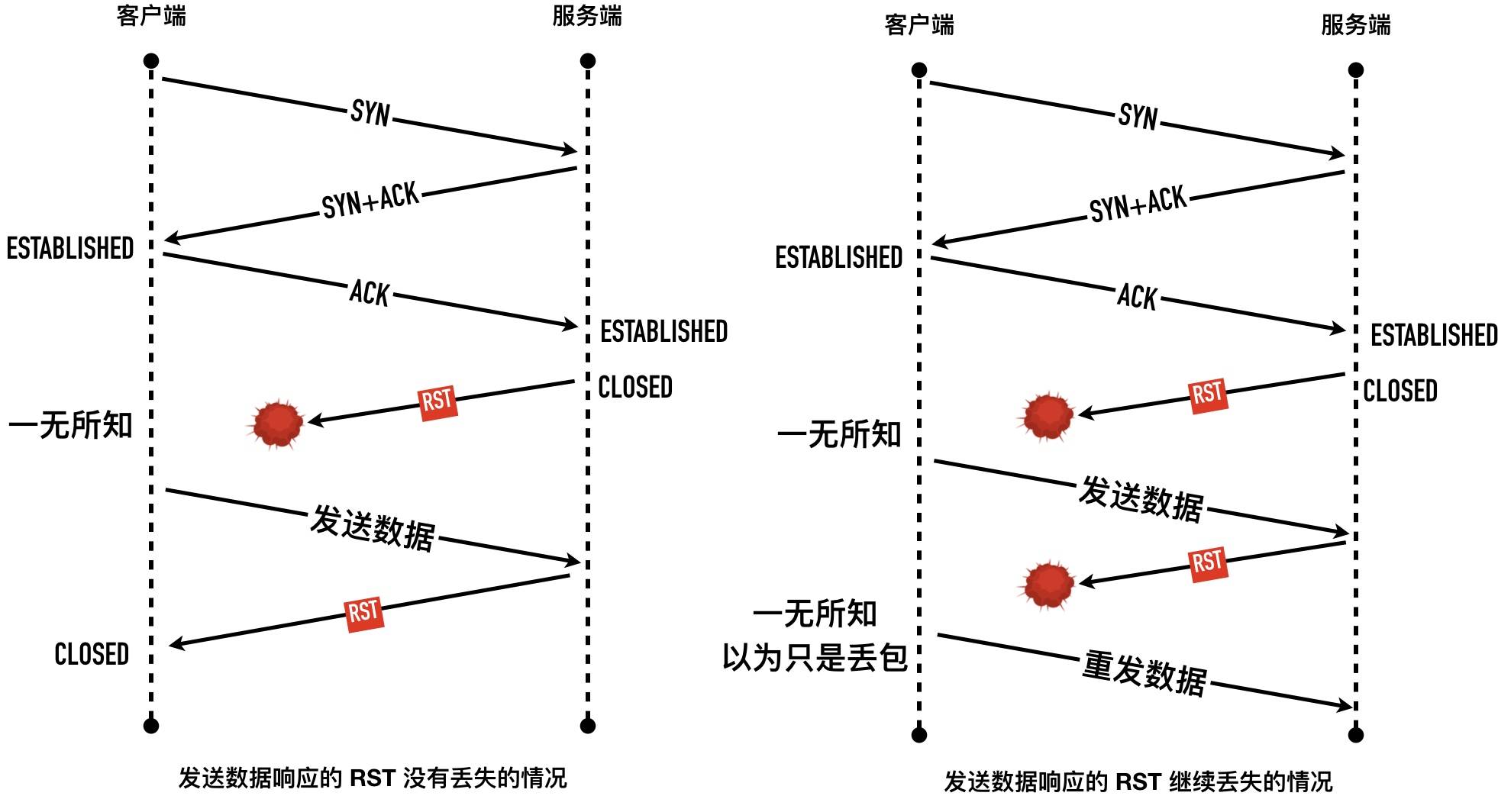
Broken Pipe和Connection reset by peer
Broken pipe 与 Connection reset by peer 错误在网络编程中非常常见,出现的前提都是连接已关闭。
-
Connection reset by peer 这个错误很好理解,就是对方已经关闭连接了
-
Broken pipe出现时机是:在一个RST的套接字中继续写数据,因为连接已经关闭了,再写数据,内核就直接返回这个异常。
-
当一个进程向某个已收到 RST 的套接字执行写操作时,内核向该进程发送一个 SIGPIPE 信号。该信号的默认行为是终止进程,因此进程一般会捕获这个信号进行处理。不论该进程是捕获了该信号并从其信号处理函数返回,还是简单地忽略该信号,写操作都将返回 EPIPE 错误(也就Broken pipe 错误),这也是 Broken pipe 只在写操作中出现的原因
重传相关:
重传示意
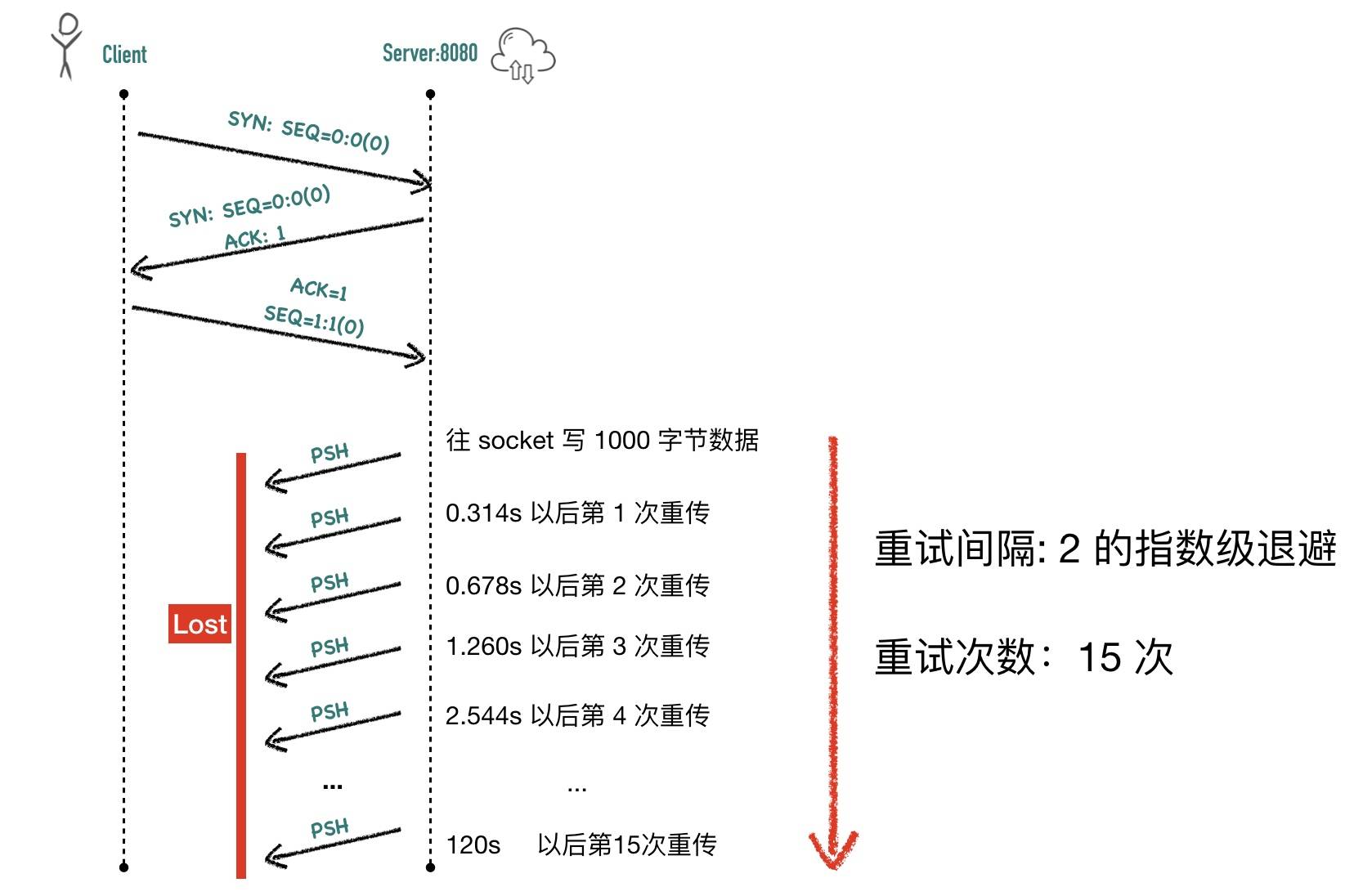
Ack延迟确认
如果发送 5000 个字节的数据包,因为 MSS 的限制每次传输 1000 个字节,分 5 段传输
- 包1 (序列号1 长度1000)
- 包2 (序列号1001 长度1000)
- 包3 (序列号2001 长度1000)
- 包4 (序列号3001 长度1000)
- 包2 (序列号4001 长度1000)
数据包 1 发送的数据正常到达接收端,接收端回复 ACK 1001,表示 seq 为1001之前的数据包都已经收到,下次从1001开始发。
数据包 2因为某些原因未能到达服务端,其他包(3,4,5)正常到达,这时接收端也不能 ack 3 4 5 数据包,因为数据包 2 还没收到,接收端只能回复 ack 1001
第 2 个数据包重传成功以后服务器会回复5001,表示seq 为 5001 之前的数据包都已经收到了,这就是Ack延迟确认
简单示意图如下:
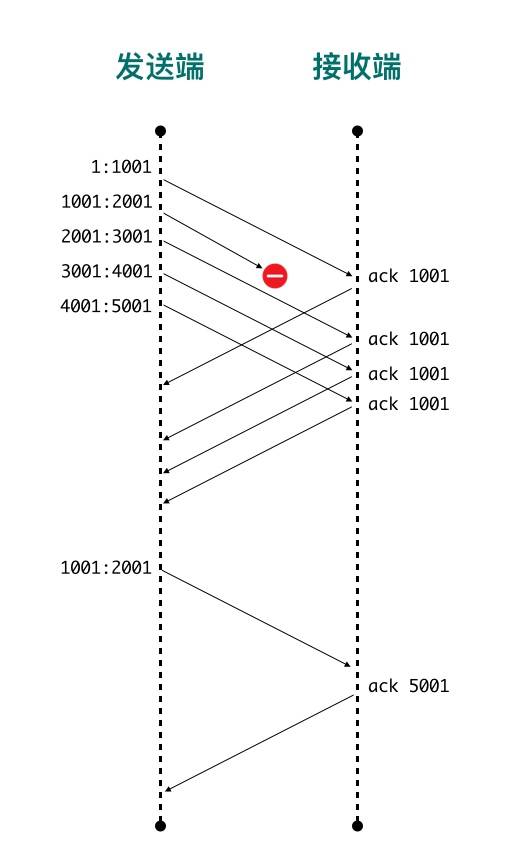
快速重传机制和SACK
网络协议设计者们想到了一种方法:「快速重传」
快速重传的含义是:当发送端收到 3 个或以上重复 ACK,就意识到之前发的包可能丢了,于是马上进行重传,不用傻傻的等到超时再重传
这就引入了另外一个问题,发送 3、4、5 包收到的全部是 ACK=1001,快速重传解决了一个问题: 需要重传。因为除了 2 号包,3、4、5 包也有可能丢失,那到底是只重传数据包 2 还是重传 2、3、4、5 所有包呢?
- 收到 3 号包的时候在 ACK 包中告诉发送端:喂,小老弟,我目前收到的最大连续的包序号是 1000(ACK=1001),[1:1001]、[2001:3001] 区间的包我也收到了
- 收到 4 号包的时候在 ACK 包中告诉发送端:喂,小老弟,我目前收到的最大连续的包序号是 1000(ACK=1001),[1:1001]、[2001:4001] 区间的包我也收到了
- 收到 5 号包的时候在 ACK 包中告诉发送端:喂,小老弟,我目前收到的最大连续的包序号是 1000(ACK=1001),[1:1001]、[2001:5001] 区间的包我也收到了
这样发送端就清楚知道只用重传 2 号数据包就可以了,数据包 3、4、5已经确认无误被对端收到。这种方式被称为 SACK(Selective Acknowledgment)
大值流程如下:
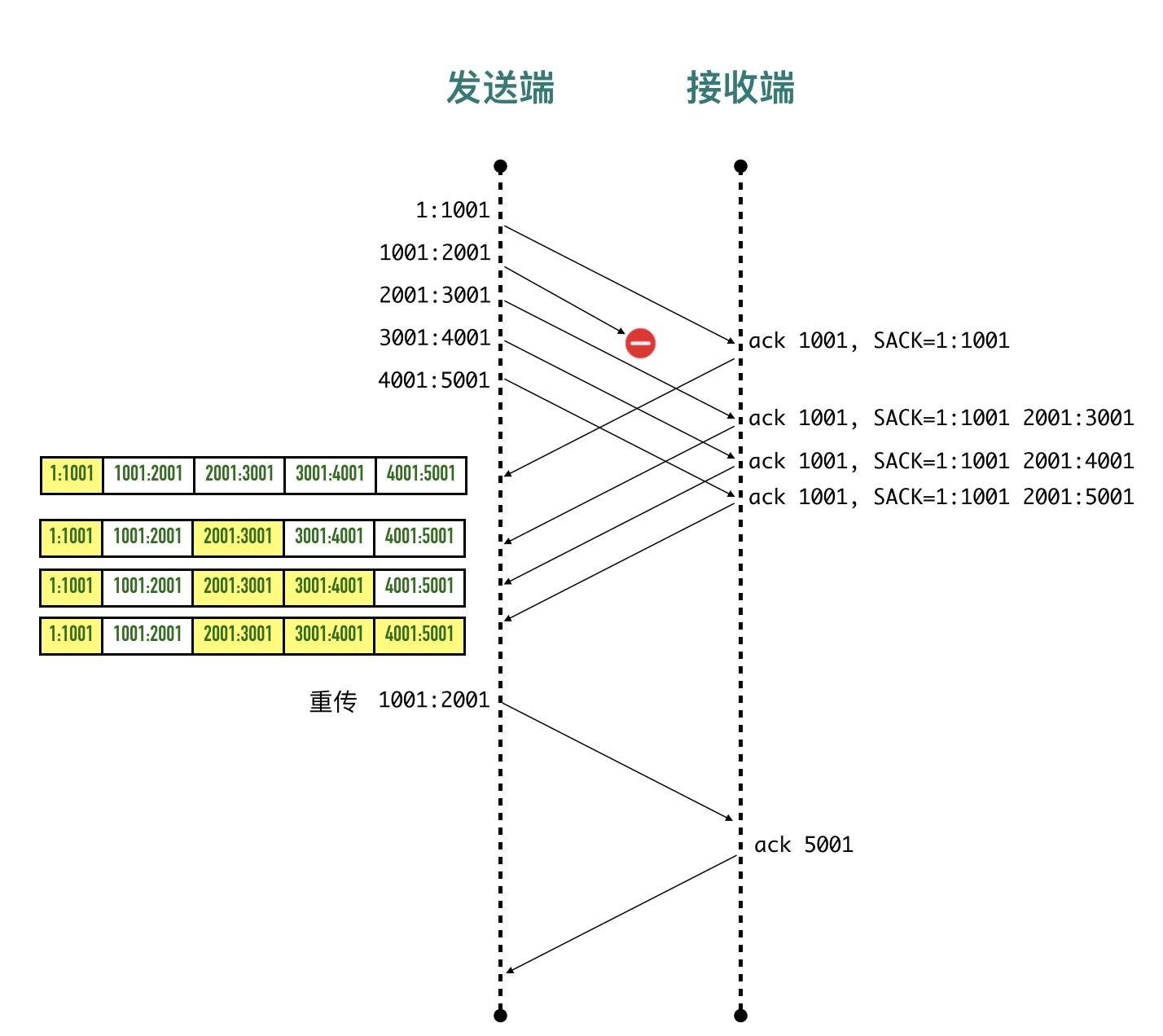
打开单个包的详情,在 ACK 包的 option 选项里,包含了 SACK 的信息,如下图:
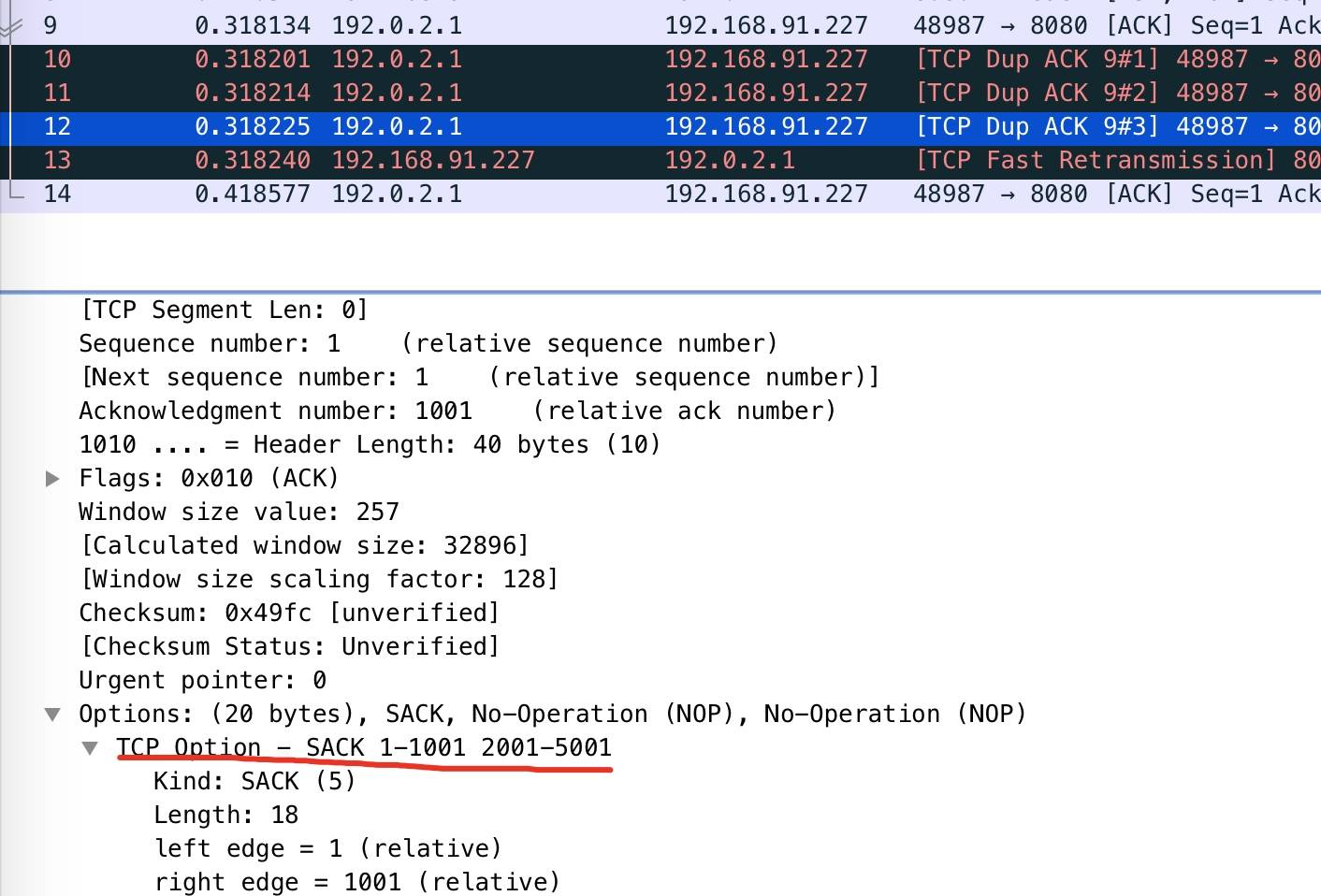
隔多久重传?
经典方法(适用 RTT 波动较小的情况)
一个最简单的想法就是取平均值,比如第一次 RTT 为 500ms,第二次 RTT 为 800ms,那么第三次发送时,各让一步取平均值 RTO 为 650ms。经典算法的思路跟取平均值是一样的,只不过系数不一样而已。
经典算法引入了「平滑往返时间」(Smoothed round trip time,SRTT)的概念:经过平滑后的RTT的值,每测量一次 RTT 就对 SRTT 作一次更新计算。
SRTT = ( α * SRTT ) + ((1- α) * RTT)
标准方法(Jacobson / Karels 算法)
传统方法最大的问题是RTT 有大的波动时,很难即时反应到 RTO 上,因为都被平滑掉了。标准方法对 RTT 的采样增加了一个新的因素
SRTT = (1 - α) * SRTT + α * RTT
RTTVAR = (1 - β) * RTTVAR + β * (|RTT-SRTT|)
RTO= µ * SRTT + ∂ * RTTVar
重传二义性与 Karn / Partridge 算法
前面的算法都很精妙,但是有一个最基本的问题还没解决,如何重传情况下计算 RTT,下面列举了三种常见的场景
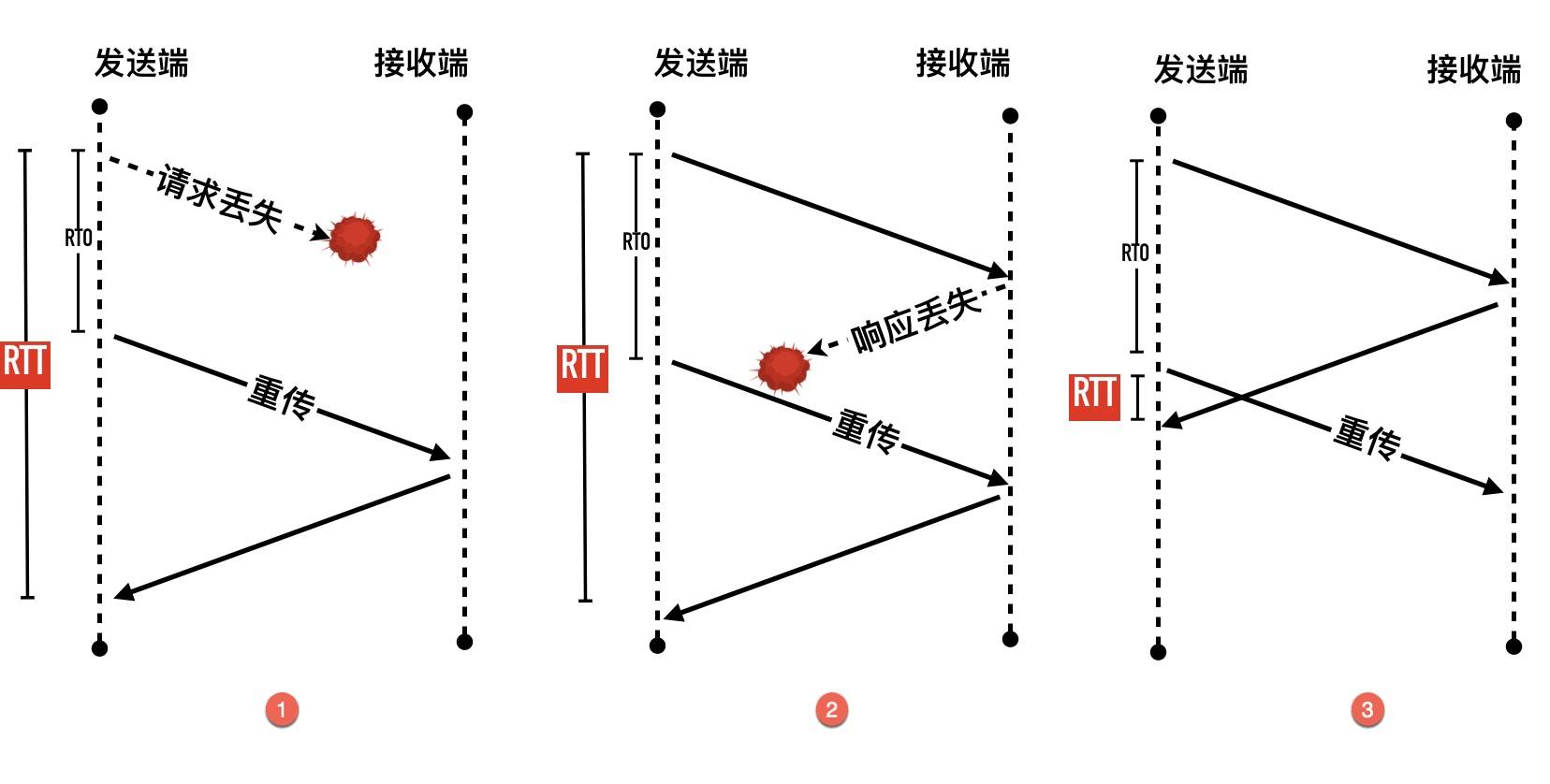
Karn / Partridge 算法就是为了解决重传二义性的。它的思路也是很奇特,解决问题的最好办法就是不解决它:
- 既然不能确定 ACK 包到底对应重传包还是非重传包,那这次就忽略吧,这次重传的 RTT 不会被用来更新 SRTT 及后面的 RTO
- 只有当收到未重传过的某个请求的 ACK 包时,才更新 SRTT 等变量并重新计算RTO
仅仅有上面的规则是远远不够的,放弃掉重传那次不管看起来就像遇到危险把头埋在沙子里的鸵鸟。如果网络抖动,倒是突然出现大量重传,但这个时候 RTO 没有更新,就很坑了,本身 RTO 就是为了自适应网络延迟状况的,结果出问题了没有任何反应。这里 Karn 算法采用了出现重传就将 RTO 翻倍的方法,这就是我们前面看到过的指数级退避(Exponential backoff)。这种方式比较粗暴,但是非常简单。
滑动窗口
背景
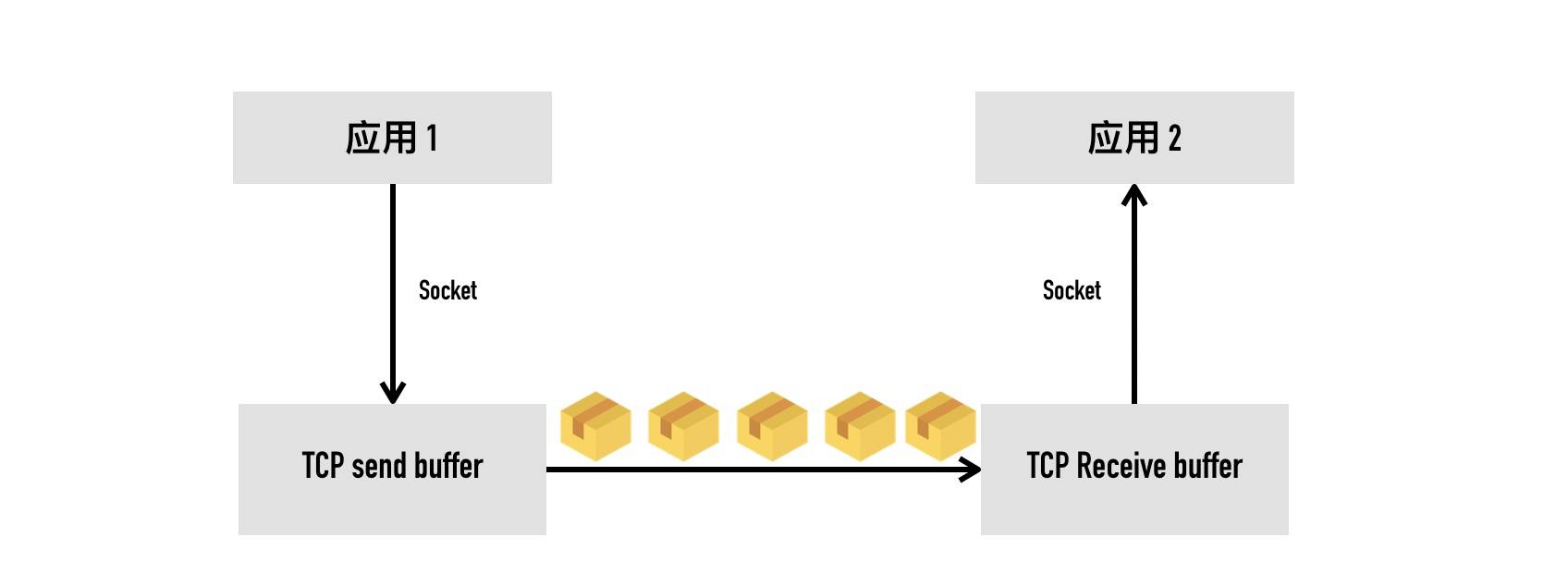
从socket的角度看TCP,大概如上面所示,TCP 会把要发送的数据放入发送缓冲区(Send Buffer),接收到的数据放入接收缓冲区(Receive Buffer),应用程序会不停的读取接收缓冲区的内容进行处理。
流量控制做的事情就是,如果接收缓冲区已满,发送端应该停止发送数据。那发送端怎么知道接收端缓冲区是否已满呢?
为了控制发送端的速率,接收端会告知客户端自己接收窗口(rwnd),也就是接收缓冲区中空闲的部分。
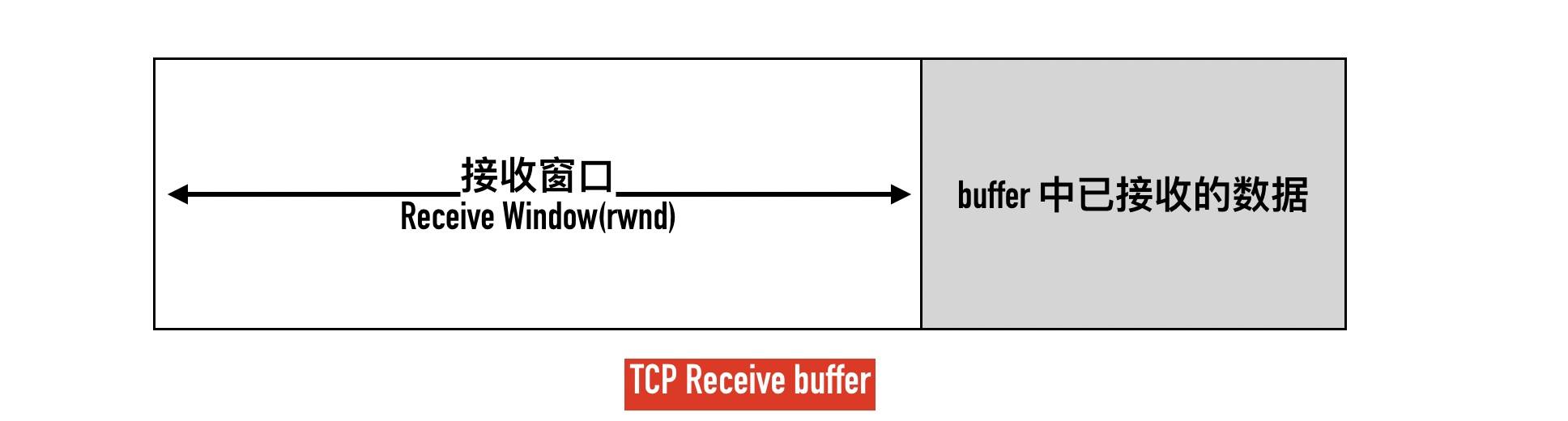
TCP 在收到数据包回复的 ACK 包里会带上自己接收窗口的大小,接收端需要根据这个值调整自己的发送策略。
抓包中的win是什么?

这里的Win是告诉对方,自己接收窗口的大小。这里的Win=29312是告诉对方自己当前能接收数据最大为29312,对方收到以后,会把自己的「发送窗口」限制在 29312 大小之内。如果自己的处理能力有限,导致自己的接收缓冲区满,接收窗口大小为 0,发送端应该停止发送数据。
TCP包状态分类
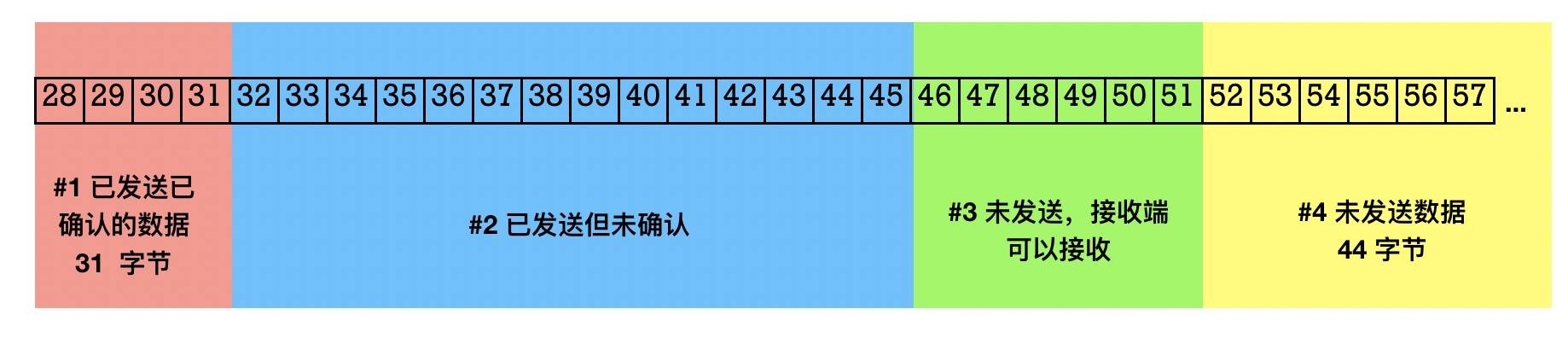
- 粉色部分#1 (Bytes Sent and Acknowledged):表示已发送且已收到 ACK 确认的数据包。
- 蓝色部分#2 (Bytes Sent but Not Yet Acknowledged):表示已发送但未收到 ACK 的数据包。发送方不确定这部分数据对端有没有收到,如果在一段时间内没有收到 ACK,发送端需要重传这部分数据包。
- 绿色部分#3 (Bytes Not Yet Sent for Which Recipient Is Ready):表示未发送但接收端已经准备就绪可以接收的数据包(有空间可以接收)
- 黄色部分#4 (Bytes Not Yet Sent,Not Ready to Receive):表示还未发送,且这部分接收端没有空间接收
发送窗口(send window)与可用窗口(usable window)
首先这两个概念都是站在发送数据方说的,需要考虑接收方的Win窗口大小。
-
发送窗口是 TCP 滑动窗口的核心概念,它表示了在某个时刻一端能拥有的最大未确认的数据包大小(最大在途数据),发送窗口是发送端被允许发送的最大数据包大小,其大小等于上图中 #2 区域和 #3 区域加起来的总大小,说白了就是发送数据方最多能发送多少数据(包括已发送但是没有被Ack的数据)
-
可用窗口是发送端还能发送的最大数据包大小,它等于发送窗口的大小减去在途数据包大小,是发送端还能发送的最大数据包大小,对应于上图中的 #3 号区域。说白了就是发送方当前实际最多能发送多少数据(发送窗口大小减掉已发送但未Ack的大小)
-
窗口的左边界表示成功发送并已经被接收方确认的最大字节序号,窗口的右边界是发送方当前可以发送的最大字节序号,滑动窗口的大小等于右边界减去左边界,如下图:
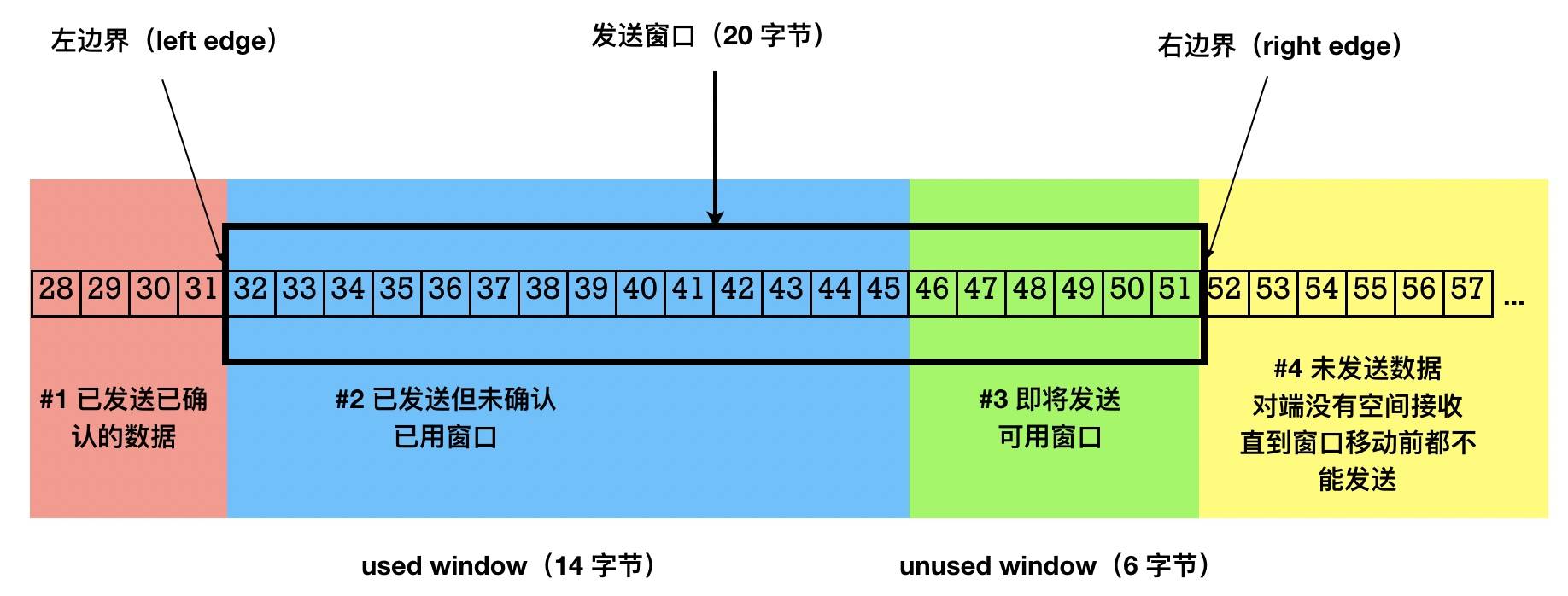
当上图中的可用区域的6个字节(46~51)发送出去,可用窗口区域减小到 0,这个时候除非收到接收端的 ACK 数据,否则发送端将不能发送数据。
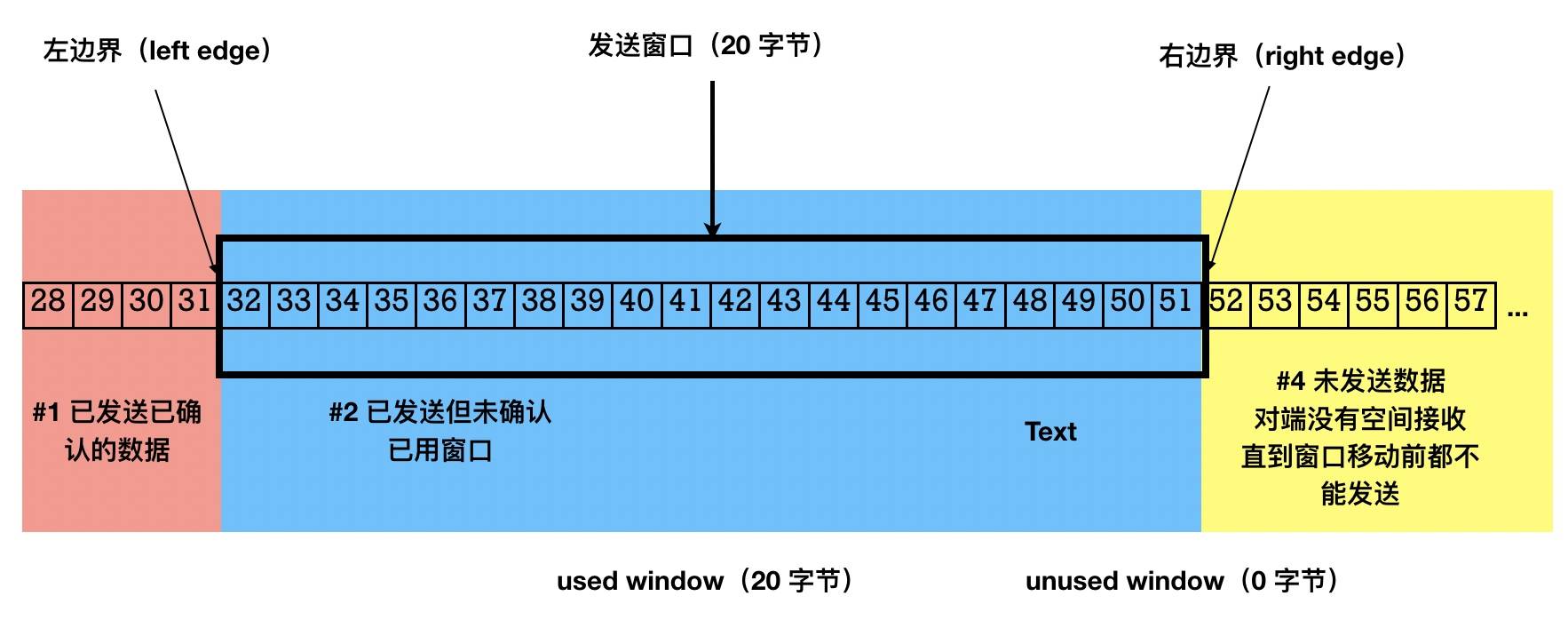
利用packetdrill模拟滑动窗口用光
脚本
--tolerance_usecs=100000
0 socket(..., SOCK_STREAM, IPPROTO_TCP) = 3
+0 setsockopt(3, SOL_SOCKET, SO_REUSEADDR, [1], 4) = 0
// 禁用 nagle 算法
+0 setsockopt(3, SOL_TCP, TCP_NODELAY, [1], 4) = 0
+0 bind(3, ..., ...) = 0
+0 listen(3, 1) = 0
// 三次握手
+0 < S 0:0(0) win 20 <mss 1000>
+0 > S. 0:0(0) ack 1 <...>
+.1 < . 1:1(0) ack 1 win 20
+0 accept(3, ..., ...) = 4
// 演示已经发送并 ACK 前 31 字节数据
+.1 write(4, ..., 15) = 15
+0 < . 1:1(0) ack 16 win 20
+.1 write(4, ..., 16) = 16
+0 < . 1:1(0) ack 32 win 20
+0 write(4, ..., 14) = 14
+0 write(4, ..., 6) = 6
+.1 < . 1:1(0) ack 52 win 20
+0 `sleep 1000000`
解析如下:
- 一开始我们禁用了 Nagle 算法以便后面可以连续发送包。
- 三次握手以后,客户端声明自己的窗口大小为 20 字节
- 通过两次发包和确认前 31 字节的数据
- 发送端发送(32,46)部分的 14 字节数据,滑动窗口的可用窗口变为 6
- 发送端发送(46,52)部分的 6 字节数据,滑动窗口的可用窗口变为 0,此时发送端不能往接收端发送任何数据了,除非有新的 ACK 到来
- 接收端确认(32,52)部分 20 字节的数据,可用窗口重现变为 20.
wireshark抓包
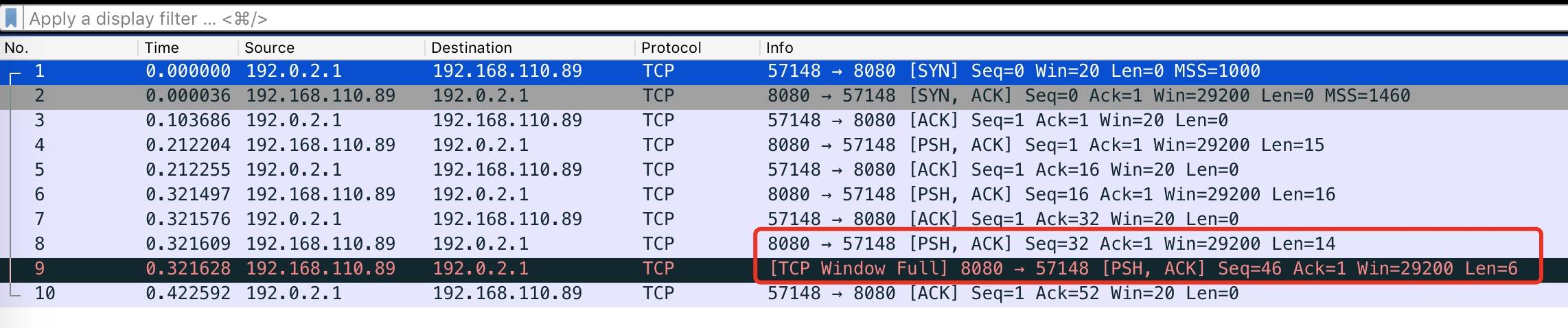
- 1—>3 为三次握手 客户端声明自己Win为20(缓冲区最多存放20字节 也就是服务端的发送窗口为20)
- 4为服务端发送15字节 然后5为客户端ack这15自己已经收到
- 6为服务端发送16字节 然后7为客户端ack这16自己已经收到
- 8为服务端发送14字节,然后客户端没有ack(所以服务端的可用窗口由20—->6)
- 9为服务端再次发送6个字节 把可用窗口用光 这个时候 不能再发送数据了
- 10为客户端回复ack,8、9发送的20字节都已经收到,这个是Win又变为20,也就是告诉服务端可以继续发送数据了
抓包显示的 TCP Window Full不是一个 TCP 的标记,而是 wireshark 智能帮忙分析出来的,表示包的发送方已经把对方所声明的接收窗口耗尽了,三次握手中客户端声明自己的接收窗口大小为 20,这意味着发送端最多只能给它发送 20 个字节的数据而无需确认,在途字节数最多只能为 20 个字。
滑动窗口变化示意图

利用packetdrill模拟滑动窗口为0 继续发包会出现什么情况
--tolerance_usecs=100000
0 socket(..., SOCK_STREAM, IPPROTO_TCP) = 3
+0 setsockopt(3, SOL_SOCKET, SO_REUSEADDR, [1], 4) = 0
+0 bind(3, ..., ...) = 0
+0 listen(3, 1) = 0
+0 < S 0:0(0) win 4000 <mss 1000>
+0 > S. 0:0(0) ack 1 <...>
// 三次握手确定客户端接收窗口大小为 360
+.1 < . 1:1(0) ack 1 win 360
+0 accept(3, ..., ...) = 4
// 第一步:往客户端(接收端)写 140 字节数据
+0 write(4, ..., 140) = 140
// 第二步:模拟客户端回复 ACK,接收端滑动窗口减小为 260
+.01 < . 1:1(0) ack 141 win 260
// 第四步:服务端(发送端)接续发送 180 字节数据给客户端(接收端)
+0 write(4, ..., 180) = 180
// 第五步:模拟客户端回复 ACK,接收端滑动窗口减小到 80
+.01 < . 1:1(0) ack 321 win 80
// 第七步:服务端(发送端)继续发送 80 字节给客户端(接收端)
+0 write(4, ..., 80) = 80
// 第八步:模拟客户端回复 ACK,接收端滑动窗口减小到 0
+.01 < . 1:1(0) ack 401 win 0
// 这一步很重要,写多少数据没关系,一定要有待发送的数据。如果没有待发的数据,不会进行零窗口探测
// 这 100 字节数据实际上不会发出去
+0 write(4, ..., 100) = 100
+0 `sleep 1000000`
wireshark抓包结果
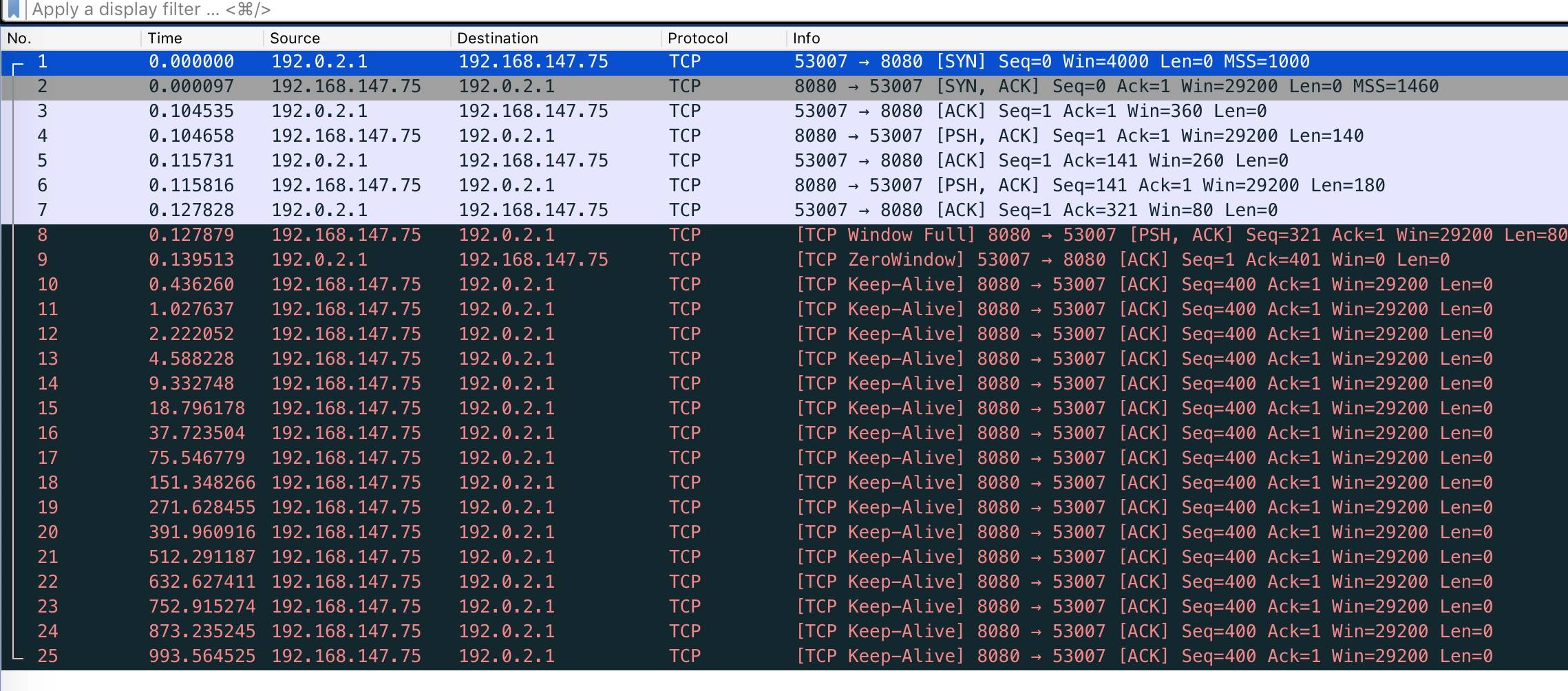
- No = 8 的包,发送端发送 80 以后,自己已经把接收端声明的接收窗口大小耗尽了,wireshark 帮我们把这种行为识别为了 TCP Window Full。
- No = 9 的包,是接收端回复的 ACK,携带了 win=0,wireshark 帮忙把这个包标记为了 TCP Zero window
- No = 10 ~ 25 的包就是我们前面提到的TCP Zero Window Probe(零窗口探测包),但是 wireshark 这里识别这个包为了 Keep-Alive,之所以被识别为Keep-Alive 是因为这个包跟 Keep-Alive 包很像。这个包的特点是:一个长度为 0 的 ACK 包,Seq 为当前连接 Seq 最大值减一。因为发出的探测包一直没有得到回应,所以会一直发送端会一直重试。重试的策略跟前面介绍的超时重传的机制一样,时间间隔遵循指数级退避,最大时间间隔为 120s,重试了 16,总共花费了 16 分钟
利用零窗口探测搞死服务器
有等待重试的地方就有攻击的可能,上面的零窗口探测也会成为攻击的对象。试想一下,一个客户端利用服务器上现有的大文件,向服务器发起下载文件的请求,在接收少量几个字节以后把自己的 window 设置为 0,不再接收文件,
服务端就会开始漫长的十几分钟时间的零窗口探测,如果有大量的客户端对服务端执行这种攻击操作,那么服务端资源很快就被消耗殆尽。
TCP window full 与 TCP zero window
这两者都是发送速率控制的手段,
- TCP Window Full 是站在发送端角度说的,表示在途字节数等于对方接收窗口的情况,此时发送端不能再发数据给对方直到发送的数据包得到 ACK。
- TCP zero window 是站在接收端角度来说的,是接收端接收窗口满,告知对方不能再发送数据给自己。
TCP拥塞控制
-
滑动窗口只关注了发送端和接收端自身的情况,并没有考虑整个网络的情况,所以就有了拥塞控制
-
TCP的拥塞控制主要涉及3个处理机制
- 慢启动(Slow Start)
- 拥塞避免(Congestion Avoidance)
- 快速重传(Fast Retransmit)、快速恢复(Fast Recovery)
为了实现这三个机制,每个TCP链接都有2个核心状态值
- 拥塞窗口(Congestion Window)—cwnd
- 慢启动阀值(Slow Start Threshold)—ssthresh
拥塞窗口 (Congestion Window,cwnd)
-
拥塞窗口指的是在收到对端 ACK 之前自己还能传输的最大 MSS 段数。
-
接收窗口(rwnd)是接收端的限制,是接收端还能接收的数据量大小
-
拥塞窗口(cwnd)是发送端的限制,是发送端在还未收到对端 ACK 之前还能发送的数据量大小
-
前面滑动窗口讲的发送窗口是单纯不考虑网络的情况,考虑网络,真正的发送窗口大小 = 「接收端接收窗口大小」 与 「发送端自己拥塞窗口大小」 两者的最小值
发送端能发送多少数据,取决于两个因素:
- 对方能接收多少数据(接收窗口)
- 自己为了避免网络拥塞主动控制不要发送过多的数据(拥塞窗口)
TCP不会在双方数据交互过程中,交换彼此的cwnd,这个值是维护在本地内存中的一个值。
拥塞控制的核心就是控制拥塞窗口的大小变化(cwnd)
慢启动Slow Start
-
所谓慢启动指的是 刚开始拥塞窗口很小,不至于让网络瘫痪,然后测试看看是否丢跑,如果对端及时Ack了,说明网络ok,慢慢增加拥塞窗口,多发送数据,持续这个过程,直到拥塞避免阶段(拥塞窗口达到慢启动阀值)。
-
大致过程如下:
- 第一步,三次握手以后,双方通过 ACK 告诉了对方自己的接收窗口(rwnd)的大小,之后就可以互相发数据了
- 第二步,通信双方各自初始化自己的「拥塞窗口」(Congestion Window,cwnd)大小。
- 第三步,cwnd 初始值较小时,每收到一个 ACK,每经过一个 RTT,cwnd 变为之前的两倍。
-
linux现在默认初始cwnd为10(根据 Google 的研究,90% 的 HTTP 请求数据都在 16KB 以内,约为 10 个 TCP 段。再大比如 16,在某些地区会出现明显的丢包,因此 10 是一个比较合理的值)
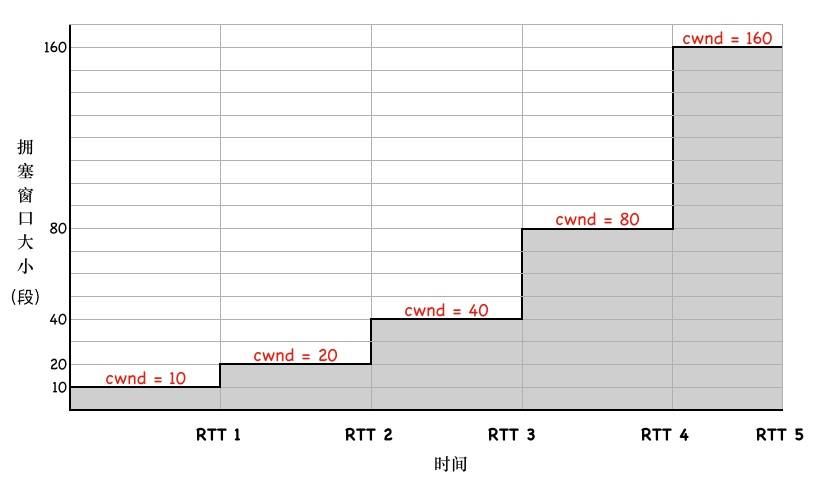
-
因此可以得到拥塞窗口到达N所花费时间为:
time(cwnd到达N)=RTT * (log ( N/initcwnd) )//这里假设RTT稳定 假设RTT为50ms,客户端和服务端的接收窗口为65535字节(64KB),初始拥塞窗口为10个MSS。 这里的N我们要先换算为MSS段数 MSS按照1460算 N=65535/1460=45 所以到达65536字节,也就是到达64K的吞吐量需要的时间为: 50ms * log(45/10)=50ms*2.12=106ms,如果RTT更小 那么这个时间也会相应变小 甚至可以忽略
慢启动阈值(Slow Start Threshold,ssthresh)
慢启动拥塞窗口(cwnd)肯定不能无止境的指数级增长下去,否则拥塞控制就变成了「拥塞失控」了,它的阈值称为「慢启动阈值」(Slow Start Threshold,ssthresh),这是文章开头介绍的拥塞控制的第二个核心状态值。ssthresh 就是一道刹车,让拥塞窗口别涨那么快。
- 当 cwnd < ssthresh 时,拥塞窗口按指数级增长(慢启动)
- 当 cwnd >= ssthresh 时,拥塞窗口按线性增长(拥塞避免)
拥塞避免(Congestion Avoidance)
当 cwnd > ssthresh 时,拥塞窗口进入「拥塞避免」阶段,在这个阶段,每一个往返 RTT,拥塞窗口大约增加 1 个 MSS 大小,直到检测到拥塞为止(三次重复Ack)。
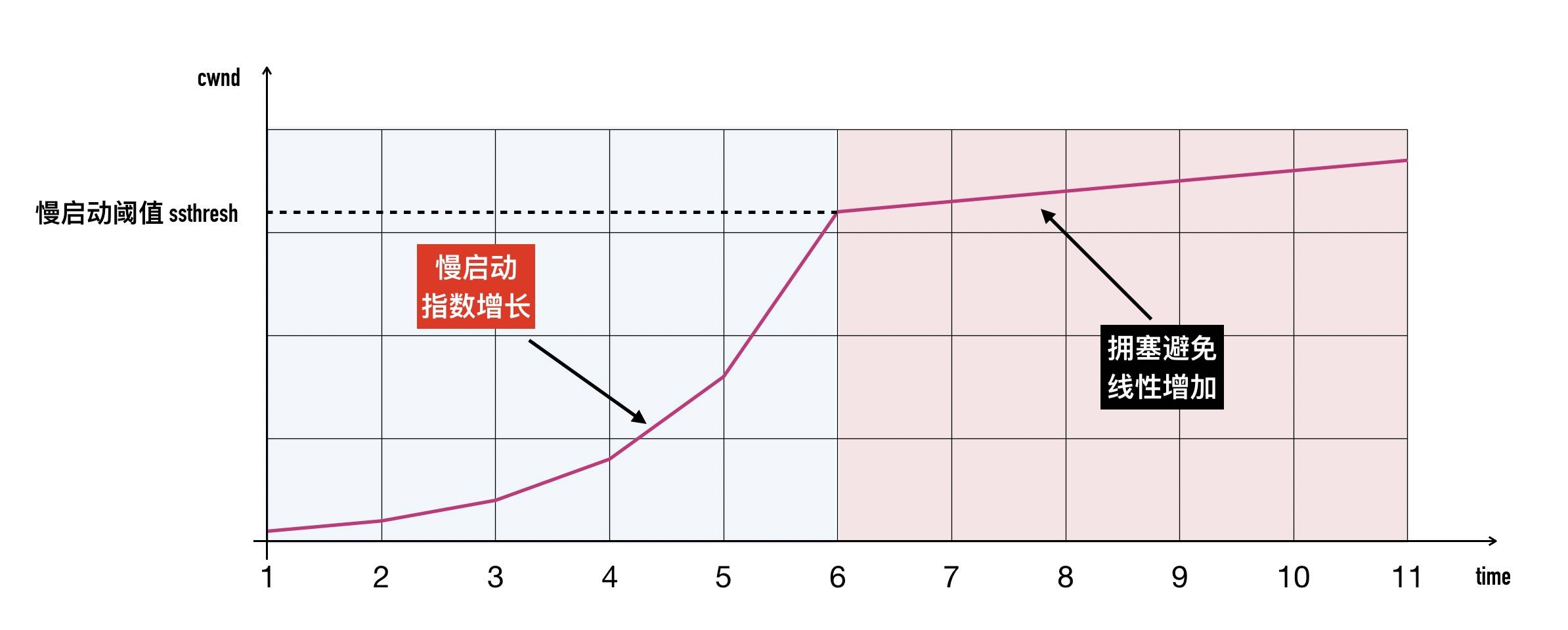
与慢启动的区别在于
- 慢启动的做法是 RTT 时间内每收到一个 ACK,也就是每经过 1 个 RTT,cwnd 翻倍
- 拥塞避免的做法保守的多,每经过一个RTT 才将拥塞窗口加 1,不管期间收到多少个 ACK
快速重传与快速恢复
-
当发送方收到3次或者更多次重复的Ack,就认为网络已经轻度拥塞了,这个时候会进行快速重传(只传SACK里面没有的包),同时进入快速恢复阶段:
- 拥塞阈值 ssthresh 降低为 cwnd 的一半:ssthresh = cwnd / 2
- 拥塞窗口 cwnd 设置为 ssthresh
- 拥塞窗口线性增加 (直到再次出现重复Ack,然后再次进行快速重发和快速恢复 如此循环)
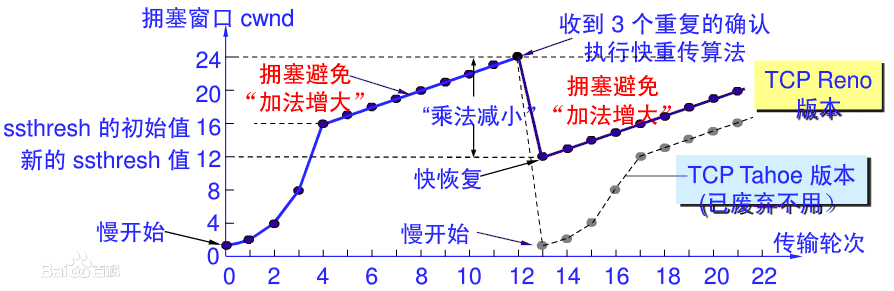
现在的initcwnd已经不是1了 上图还是1
Nagle 算法
if there is new data to send
if the window size >= MSS and available data is >= MSS
send complete MSS segment now
else
if there is unconfirmed data still in the pipe
enqueue data in the buffer until an acknowledge is received
else
send data immediately
end if
end if
end if
- Nagle 算法的作用是减少小包在客户端和服务端直接传输,一个包的 TCP 头和 IP 头加起来至少都有 40 个字节,如果携带的数据比较小的话,那就非常浪费了。就好比开着一辆大货车运一箱苹果一样
- Nagle 算法在通信时延较低的场景下意义不大。在 Nagle 算法中 ACK 返回越快,下次数据传输就越早
- 假设 RTT 为 10ms 且没有延迟确认,那么你敲击键盘的间隔大于 10ms 的话就不会触发 Nagle 的条件:只有接收到所有的在传数据的 ACK 后才能继续发数据,也即如果所有的发出去的包 ACK 都收到了,就不用等了。如果你想触发 Nagle 的停等(stop-wait)机制,1s 内要输入超过 100 个字符。因此如果在局域网内,Nagle 算法基本上没有什么效果
关闭Nagle算法
TCP_NODELAY选项设置为true
小结
Nagle 算法,这个算法可以有效的减少网络上小包的数量。Nagle 算法是应用在发送端的,简而言之就是,对发送端而言:
- 当第一次发送数据时不用等待,就算是 1byte 的小包也立即发送
- 后面发送数据时需要累积数据包直到满足下面的条件之一才会继续发送数据:
- 数据包达到最大段大小MSS
- 接收端收到之前数据包的确认 ACK
不过 Nagle 算法是时代的产物,可能会导致较多的性能问题,尤其是与ack延迟确认一起使用的时候。很多组件为了高性能都默认禁用掉了这个特性
Nagle 算法出现的时候网络带宽都很小,当有大量小包传输时,很容易将带宽占满,出现丢包重传等现象。因此对 ssh 这种交互式的应用场景,选择开启 Nagle 算法可以使得不再那么频繁的发送小包,而是合并到一起,代价是稍微有一些延迟。现在的 ssh 客户端已经默认关闭了 Nagle 算法。
Ack延迟确认 delayed ack
- 不是每个数据包都对应一个 ACK 包,因为可以合并确认。
- 也不是接收端收到数据以后必须立刻马上回复确认包
如果收到一个数据包以后暂时没有数据要分给对端,它可以等一段时间(Linux 上是 40ms)再确认。如果这段时间刚好有数据要传给对端,ACK 就可以随着数据一起发出去了。如果超过时间还没有数据要发送,也发送 ACK,以免对端以为丢包了。这种方式成为「延迟确认」
这个原因跟 Nagle 算法其实一样,回复一个空的 ACK 太浪费了。
- 如果接收端这个时候恰好有数据要回复客户端,那么 ACK 搭上顺风车一块发送。
- 如果期间又有客户端的数据传过来,那可以把多次 ACK 合并成一个立刻发送出去
- 如果一段时间没有顺风车,那么没办法,不能让接收端等太久,一个空包也得发。
什么场景立马回复Ack
- 如果接收到了大于一个frame 的报文,且需要调整窗口大小
- 处于 quickack 模式(tcp_in_quickack_mode)
- 收到乱序包(We have out of order data.)
其它情况一律采用Delayed ack
- pingpong就是有来有回 一般是R-W-R-W…
- 延迟确认出现的最多的场景是
W-W-R(写写读)
Delayed ack例子
-
服务端 readLine 有返回非空字符串(读到
\n 或 \r)就把字符串原样返回给客户端public class DelayAckServer { private static final int PORT = 8888; public static void main(String[] args) throws IOException { ServerSocket serverSocket = new ServerSocket(); serverSocket.bind(new InetSocketAddress(PORT)); System.out.println("Server startup at " + PORT); while (true) { Socket socket = serverSocket.accept(); InputStream inputStream = socket.getInputStream(); OutputStream outputStream = socket.getOutputStream(); int i = 1; while (true) { BufferedReader reader = new BufferedReader(new InputStreamReader(inputStream)); String line = reader.readLine(); if (line == null) break; System.out.println((i++) + " : " + line); outputStream.write((line + "\n").getBytes()); } } } } -
客户端分两次调用 write 方法,模拟 http 请求的 header 和 body。第二次 write 包含了换行符(\n),然后测量 write、write、read 所花费的时间
public class DelayAckClient { public static void main(String[] args) throws IOException { Socket socket = new Socket(); socket.connect(new InetSocketAddress("server_ip", 8888)); InputStream inputStream = socket.getInputStream(); OutputStream outputStream = socket.getOutputStream(); BufferedReader reader = new BufferedReader(new InputStreamReader(inputStream)); String head = "hello, "; String body = "world\n"; for (int i = 0; i < 10; i++) { long start = System.currentTimeMillis(); outputStream.write(("#" + i + " " + head).getBytes()); // write outputStream.write((body).getBytes()); // write String line = reader.readLine(); // read System.out.println("RTT: " + (System.currentTimeMillis() - start) + ": " + line); } inputStream.close(); outputStream.close(); socket.close(); } } -
运行结果:
javac DelayAckClient.java; java -cp . DelayAckClient RTT: 1: #0 hello, world RTT: 44: #1 hello, world RTT: 46: #2 hello, world RTT: 44: #3 hello, world RTT: 42: #4 hello, world RTT: 41: #5 hello, world RTT: 41: #6 hello, world RTT: 44: #7 hello, world RTT: 44: #8 hello, world RTT: 44: #9 hello, world除了第一次,剩下的 RTT 全为 40 多毫秒。这刚好是 Linux 延迟确认定时器的时间 40ms .
对包逐个分析一下 1 ~ 3:三次握手 4 ~ 9:第一次 for 循环的请求,也就是 W-W-R 的过程
- 4:客户端发送 “#0 hello, " 给服务端
- 5:因为服务端只收到了数据还没有回复过数据,tcp 判断不是 pingpong 的交互式数据,属于 quickack 模式,立刻回复 ACK
- 6:客户端发送 “world\n” 给服务端
- 7:服务端因为还没有回复过数据,tcp 判断不是 pingpong 的交互式数据,服务端立刻回复 ACK
- 8:服务端读到换行符,readline 函数返回,会把读到的字符串原样写入到客户端。TCP 这个时候检测到是 pingpong 的交互式连接,进入延迟确认模式
- 9:客户端收到数据以后回复 ACK
10 ~ 14:第二次 for 循环
- 10:客户端发送 “#1 hello, " 给服务端。服务端收到数据包以后,因为处于 pingpong 模式,开启一个 40ms 的定时器,奢望在 40ms 内有数据回传
- 11:很不幸,服务端等了 40ms 定期器到期都没有数据回传,回复确认 ACK 同时取消 pingpong 状态
- 12:客户端发送 “world\n” 给服务端
- 13:因为服务端不处于 pingpong 状态,所以收到数据立即回复 ACK
- 14:服务端读到换行符,readline 函数返回,会把读到的字符串原样写入到客户端。这个时候又检测到收发数据了,进入 pingpong 状态。
从第二次 for 开始,后面的数据包都一样了。 整个过程包交互图如下:
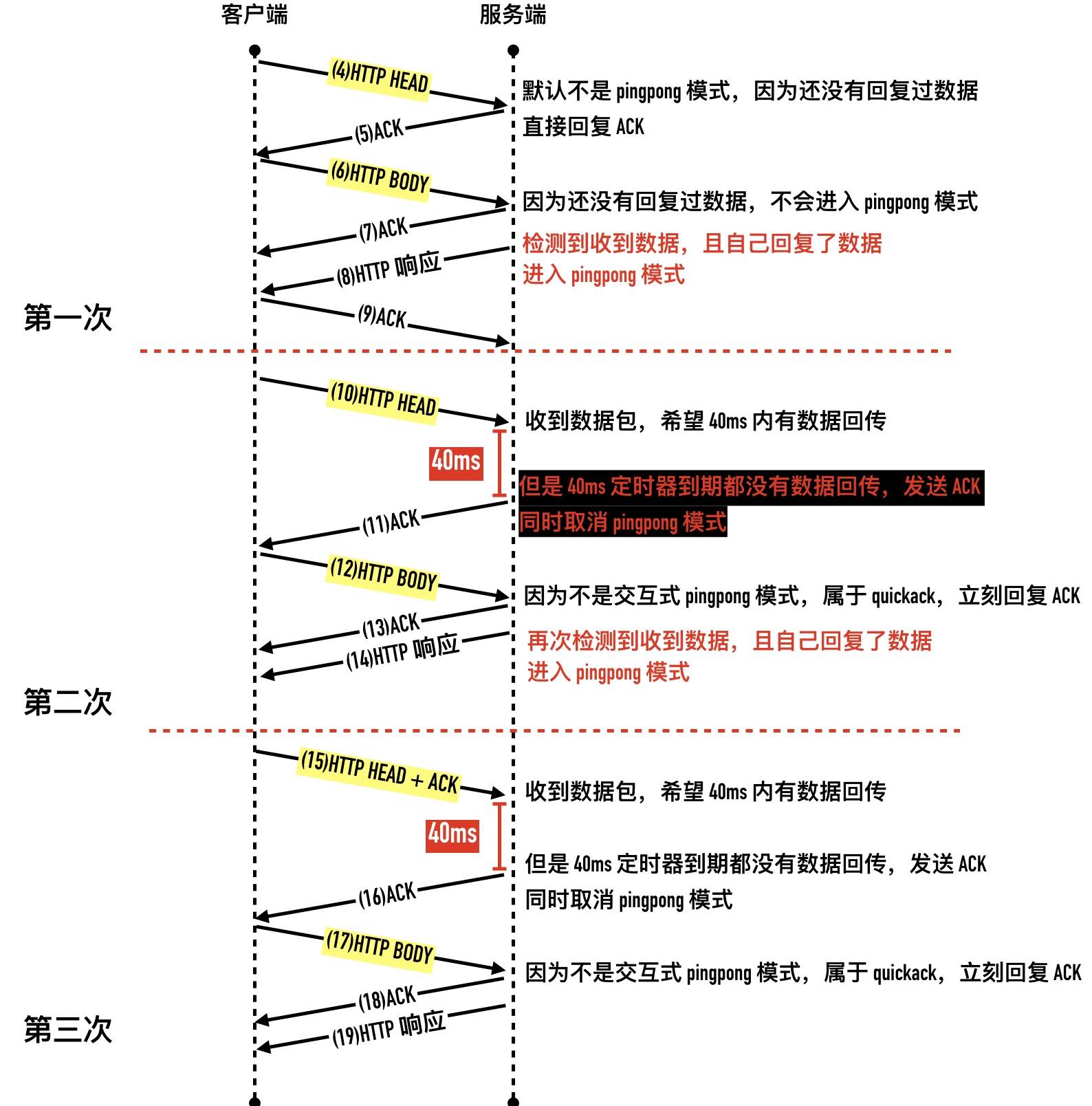
Nagle算法+Dealyed Ack
上面结果其实是默认开启了Nagle算法的,如果将其关闭 每次RTT都差不多,几乎为0.
禁用 Nagle 的情况下,不用等一个包发完再发下一个,而是几乎同时把两次写请求发送出来了。服务端收到带换行符的包以后,立马可以返回结果,ACK 可以捎带过去,就不会出现延迟 40ms 的情况
TCP的keepalive
背景
络故障或者系统宕机都将使得对端无法得知这个消息。如果应用程序不发送数据,可能永远无法得知该连接已经失效。假设应用程序是一个 web 服务器,客户端发出三次握手以后故障宕机或被踢掉网线,对于 web 服务器而已,下一个数据包将永远无法到来,但是它一无所知。TCP 不会采用类似于轮询的方式来询问:小老弟你有什么东西要发给我吗?
这一个情况就是如果在未告知另一端的情况下通信的一端关闭或终止连接,那么就认为该条TCP连接处于半打开状态。
这种情况发现在通信的一方的主机崩溃、电源断掉的情况下。 只要不尝试通过半开连接来传输数据,正常工作的一端将不会检测出另外一端已经崩溃。
那么有一段将一直有一个ESTABLISHED状态的连接 占用资源
linux tcp keepalive相关参数
// 多少秒 没有数据包交互发送keepalive探测包 默认
ketonghe@ubuntu:~/code$ cat /proc/sys/net/ipv4/tcp_keepalive_time
7200
//每次keepalive探测时间间隔 单位秒
ketonghe@ubuntu:~/code$ cat /proc/sys/net/ipv4/tcp_keepalive_intvl
75
//最多探测多少次
ketonghe@ubuntu:~/code$ cat /proc/sys/net/ipv4/tcp_keepalive_probes
9
为什么大部分应用程序都没有开启 keepalive 选项
现在大部分应用程序)都没有开启 keepalive 选项,一个很大的原因就是默认的超时时间太长了,从没有数据交互到最终判断连接失效,需要花 2.1875 小时(7200 + 75 * 9),显然太长了。但如果修改这个值到比较小,又违背了 keepalive 的设计初衷(为了检查长时间死连接)
生产实践
- 一般都有心跳包:比如服务端针对每个连接计时,如果长时间没有收到客户端的数据就直接close掉这个连接。客户端如果想要维持长连接就间隔一定时间发送心跳包。
TCP的定时器
连接建立定时器(connection establishment)
当发送端发送 SYN 报文想建立一条新连接时,会开启连接建立定时器,如果没有收到对端的 ACK 包将进行重传。
时间变化规律为: 间隔 1s、2s、4s、8s、16s、32s。。。。重传次数为配置:
/proc/sys/net/ipv4/tcp_syn_retries 默认6
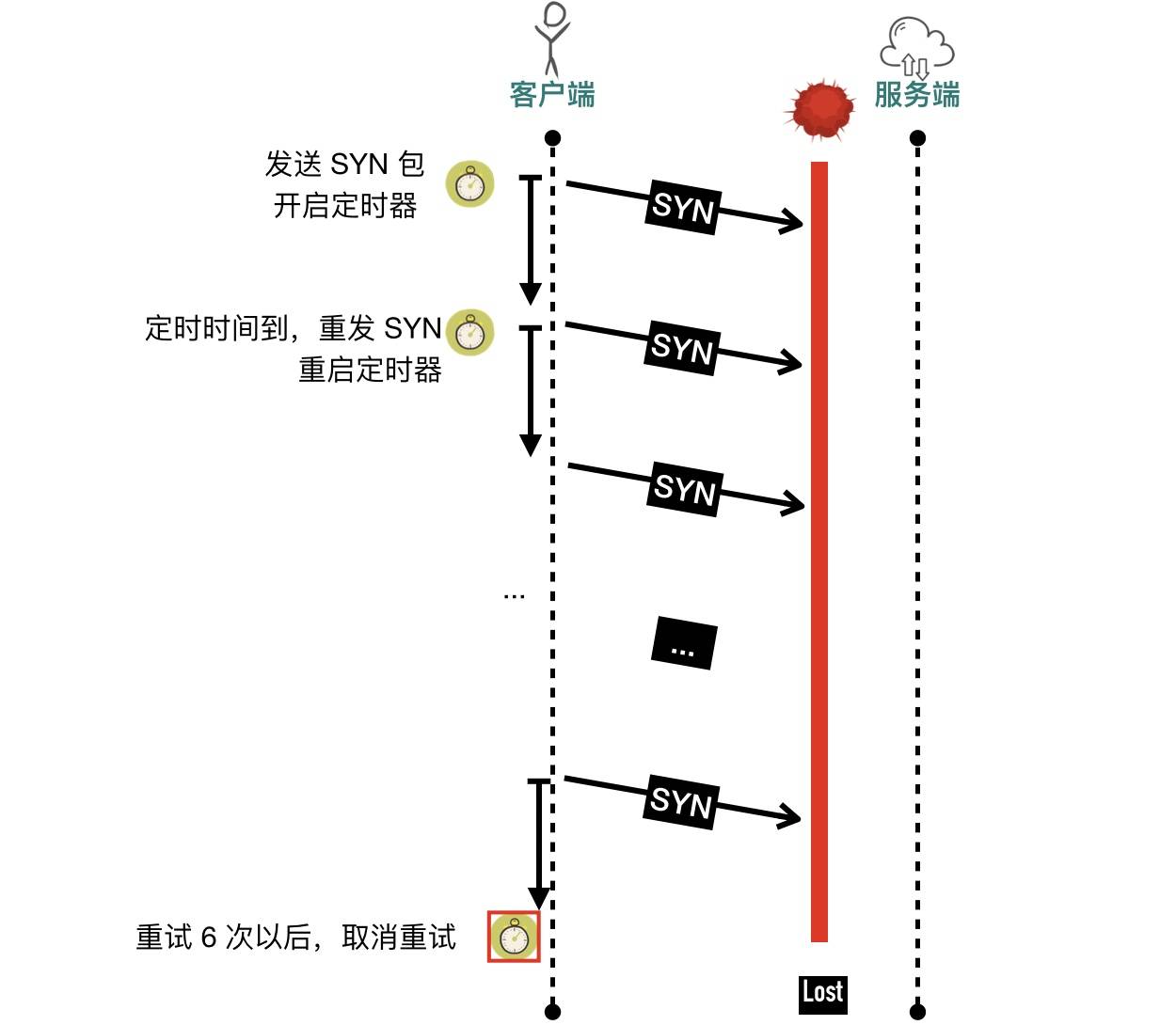
重传定时器(retransmission)
如果在发送数据包的时候没有收到 ACK 呢?这就是这里要讲的第二个定时器重传定时器。重传定时器在时间是动态计算的,取决于 RTT 和重传的次数。
/proc/sys/net/ipv4/tcp_retries2 配置最大重传次数 默认15
延迟 ACK 定时器
TCP 收到数据包以后在没有数据包要回复时,不马上回复 ACK。这时开启一个定时器,等待一段时间看是否有数据需要回复。如果期间有数据要回复,则在回复的数据中捎带 ACK,如果时间到了也没有数据要发送,则也发送 ACK。linux很多默认40ms,这个可以参见上面的delayed ack章节
坚持计时器(persist timer)
专门为零窗口探测而准备的,我们都知道 TCP 利用滑动窗口来实现流量控制,当接收端 B 接收窗口为 0 时,发送端 A 此时不能再发送数据,发送端A此时开启 Persist 定时器,超时后发送一个特殊的报文给接收端看对方窗口是否已经恢复,这个特殊的报文只有一个字节
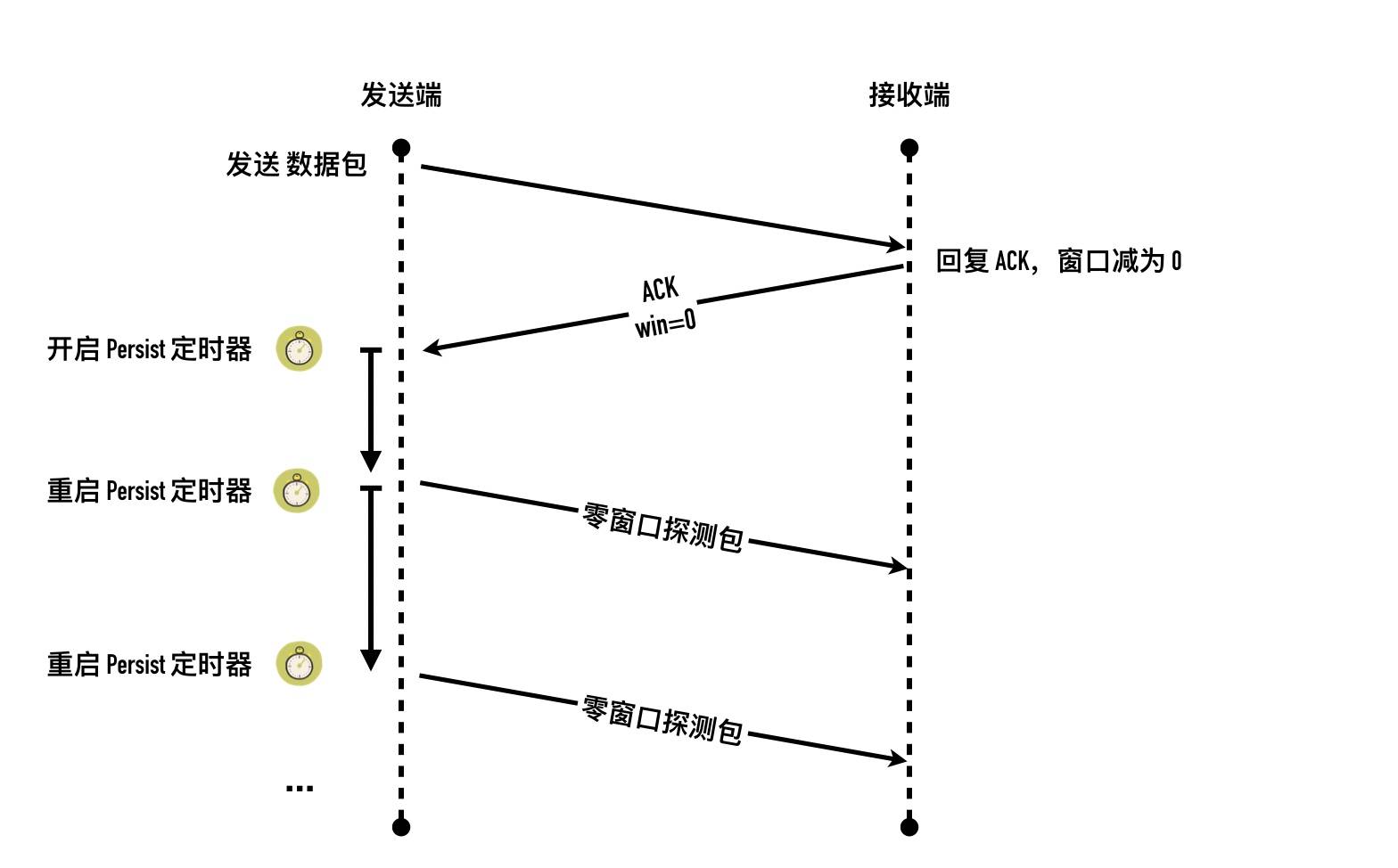
保活定时器(keepalive timer)
通信以后一段时间有再也没有传输过数据,怎么知道对方是不是已经挂掉或者重启了呢?于是 TCP 提出了一个做法就是在连接的空闲时间超过 2 小时,会发送一个探测报文,如果对方有回复则表示连接还活着,对方还在,如果经过几次探测对方都没有回复则表示连接已失效,客户端会丢弃这个连接。
FIN_WAIT_2 定时器
四次挥手过程中,主动关闭的一方收到 ACK 以后从 FIN_WAIT_1 进入 FIN_WAIT_2 状态等待对端的 FIN 包的到来,FIN_WAIT_2 定时器的作用是防止对方一直不发送 FIN 包,防止自己一直傻等。这个值由/proc/sys/net/ipv4/tcp_fin_timeout 决定
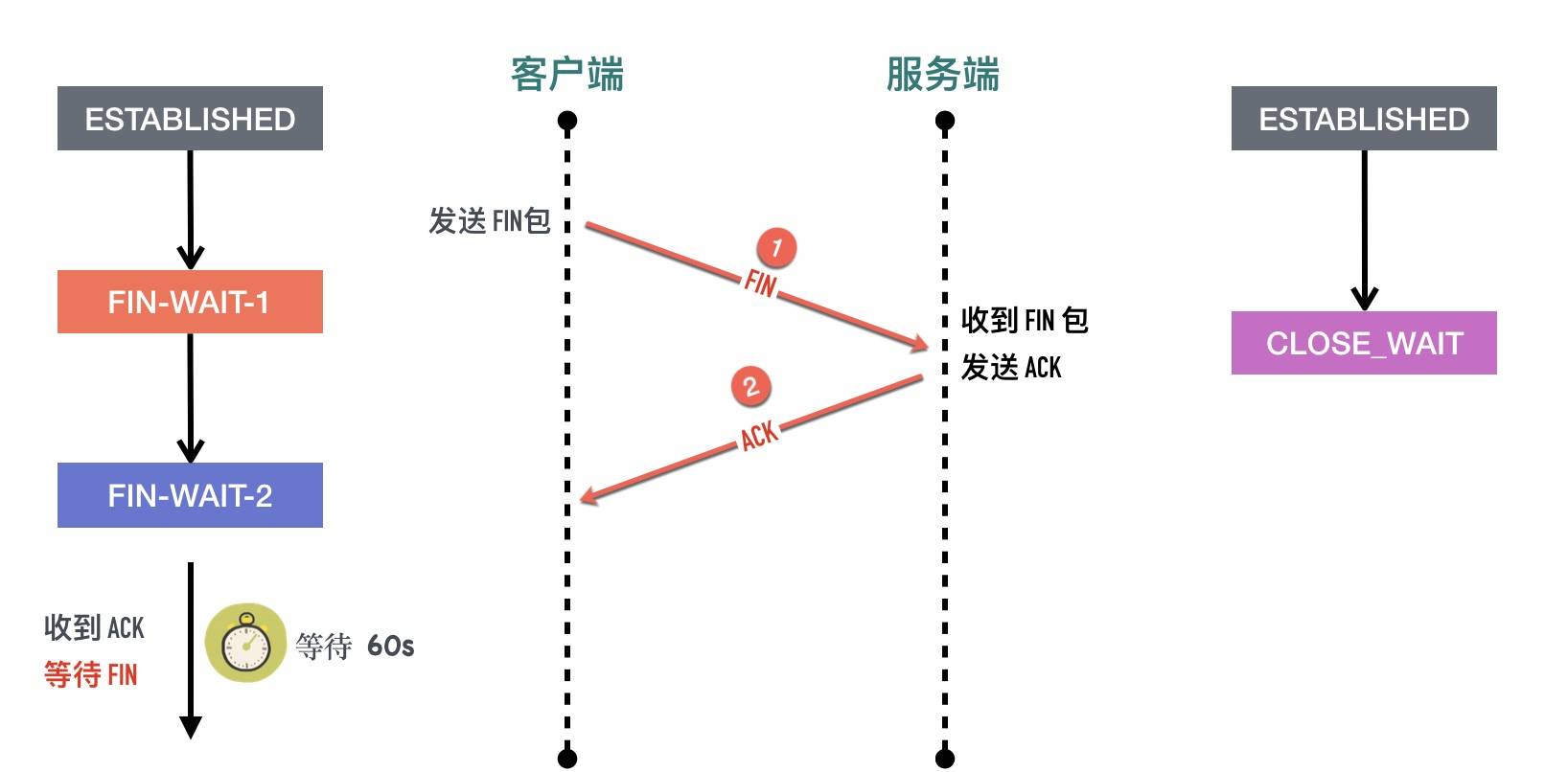
TIME_WAIT 定时器
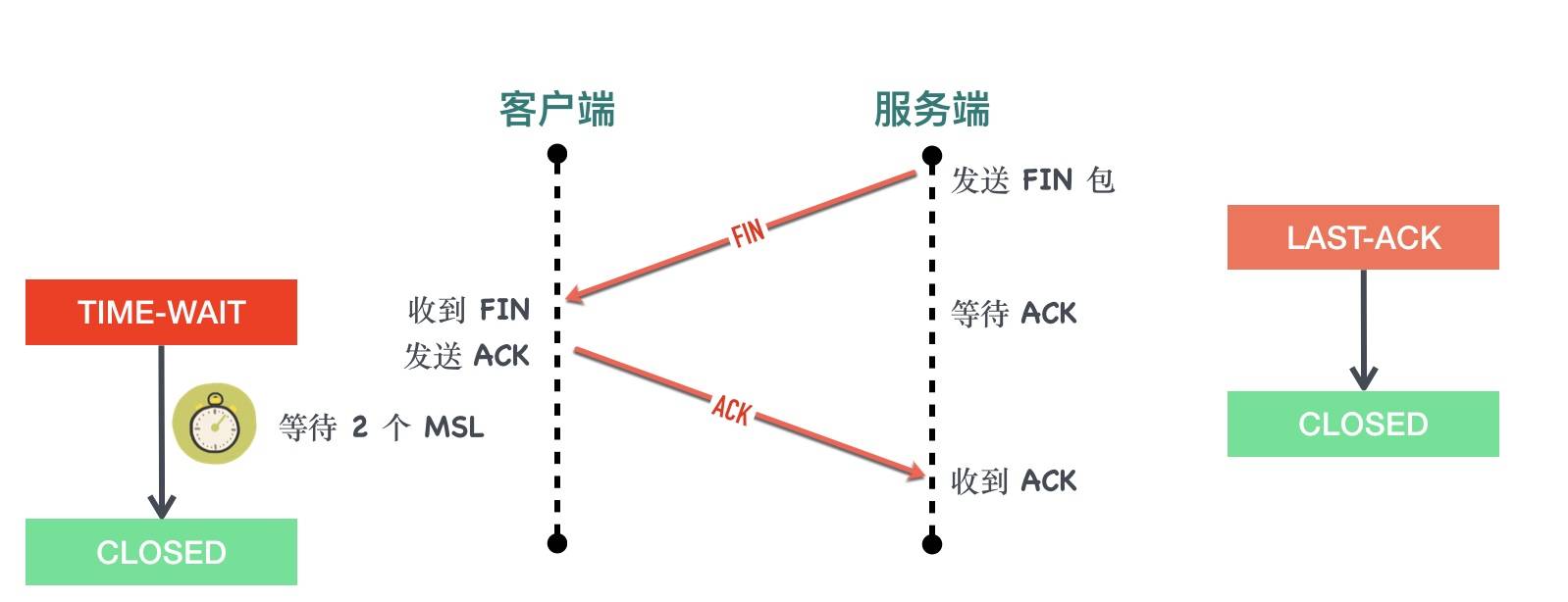
TIME_WAIT存在的意义有两个:
- 可靠的实现 TCP 全双工的连接终止(处理最后 ACK 丢失的情况)
- 避免当前关闭连接与后续连接混淆(让旧连接的包在网络中消逝)
一些工具使用
telnet
//检查端口是否打开
telnet [domainname or ip] [port]
-------------------------------------------------------------------------------------
//发送http请求
telnet www.baidu.com 80
GET / HTTP/1.1
Host: www.baidu.com
-------------------------------------------------------------------------------------
//连接redis 执行命令
$ telnet 127.0.0.1 6379
Trying 127.0.0.1...
Connected to localhost.
Escape character is '^]'.
set hello world
+OK
get hello
$5
world
netcat
-------------------------------------------------------------------------------------
//快速启动监听 或者聊天
nc -l 9090 //快速启动进程 监听9090端口 l为监听listen的意思
nc localhost 9090 //连接本机的9090端口 接下来2端就可以聊天了
-------------------------------------------------------------------------------------
//可以跟telnet一样 发送http请求
$ nc www.baidu.com 80
GET / HTTP/1.1
host: www.baidu.com
HTTP/1.1 200 OK
Accept-Ranges: bytes
Cache-Control: no-cache
Connection: keep-alive
Content-Length: 14615
....
-------------------------------------------------------------------------------------
//用unix管道的形式 发送http请求
echo -ne "GET / HTTP/1.1\r\nhost:www.baidu.com\r\n\r\n" | nc www.baidu.com 80
echo 的 -n 参数很关键,echo 默认会在输出的最后增加一个换行,加上 -n 参数以后就不会在最后自动换行了。
执行上面的命令,可以看到也返回了百度的首页 html
-------------------------------------------------------------------------------------
//查看远端端口是否打开 -z 参数表示不发送任何数据包,tcp 三次握手完后自动退出进程。有了 -v 参数则会输出更多详细信息(verbose)
nc -zv [host or ip] [port]
$ nc -zv www.baidu.com 80
Connection to www.baidu.com port 80 [tcp/http] succeeded!
-------------------------------------------------------------------------------------
//也可以访问redis
nc localhost 6379
... 然后就可以执行命令了
$ echo get hello | nc localhost 6379 //也可以这样直接执行一个命令
$5
world
-------------------------------------------------------------------------------------
netstat
//参数说明
-a 列出所有套接字 包括各种协议 各种状态的
-t 列出tcp相关的
-u 列出udp相关的
-l 列出处于监听状态的
-n 禁用端口和ip映射
-p 显示进程
-i 显示所有网卡信息
-------------------------------------------------------------------------------------
//查看某个状态处于某个状态的连接 同时打印相关进程信息
ketonghe@ubuntu:~/code$ netstat -tnp|grep 8787|grep xxx
(Not all processes could be identified, non-owned process info
will not be shown, you would have to be root to see it all.)
tcp 0 0 192.168.3.66:8787 192.168.3.66:43072 ESTABLISHED 88296/./server
tcp 0 0 192.168.3.66:43072 192.168.3.66:8787 ESTABLISHED 88303/./client
-------------------------------------------------------------------------------------
//统计某个端口处于各个状态的连接个数
ketonghe@ubuntu:~/code$ netstat -ant | grep 8787|awk '{print $6}' | sort | uniq -c | sort -n
2 LISTEN
4 ESTABLISHED
tcpdump
//常用参数说明 另外一般都要root权限
-i 指定网卡 tcpdump -i any就是所有网卡 ifconfig可以查看网卡信息 -i en1就是只监控en1网卡的
host 指定主机
sudo tcpdump -i en1 host 10.211.55.2 //监控en1网卡 主机是xxx的信息 这里没有指定src dst所以可以是源ip或者目标ip
sudo tcpdump -i any src 10.211.55.10//只抓取主机xx发出的包
sudo tcpdump -i any dst 10.211.55.1//只抓去主机xx收到的包
port选项 指定端口
sudo tcpdump -i any dst port 80 //只抓取80端口收到的包
tcpdump portrange 21-23 //抓取 21 到 23 区间所有端口的流量 限定端口范围
-n 禁止ip映射 显示真实ip -nn 显示真实ip和端口 都不映射
sudo tcpdump -i any -nn udp //过滤协议 只查看udp
-A 用 ASCII 打印报文内容,比如常用的 HTTP 协议传输 json 、html 文件等都可以用这个选项
sudo tcpdump -i any -nn port 80 -A
输出如下:
11:04:25.793298 IP 183.57.82.231.80 > 10.211.55.10.40842: Flags [P.], seq 1:1461, ack 151, win 16384, length 1460
HTTP/1.1 200 OK
Server: Tengine
Content-Type: application/javascript
-X 命令,用来同时用 HEX 和 ASCII 显示报文内容。
sudo tcpdump -i any -nn port 80 -X
11:33:53.945089 IP 36.158.217.225.80 > 10.211.55.10.45436: Flags [P.], seq 1:1461, ack 151, win 16384, length 1460
0x0000: 4500 05dc b1c4 0000 8006 42fb 249e d9e1 E.........B.$...
0x0010: 0ad3 370a 0050 b17c 3b79 032b 8ffb cf66 ..7..P.|;y.+...f
0x0020: 5018 4000 9e9e 0000 4854 5450 2f31 2e31 P.@.....HTTP/1.1
0x0030: 2032 3030 204f 4b0d 0a53 6572 7665 723a .200.OK..Server:
0x0040: 2054 656e 6769 6e65 0d0a 436f 6e74 656e .Tengine..Conten
0x0050: 742d 5479 7065 3a20 6170 706c 6963 6174 t-Type:.applicat
-s 选项 限制包大小 当包体很大,可以用 -s 选项截取部分报文内容,一般都跟 -A 一起使用。查看每个包体前 500 字节可以用下面的命令
sudo tcpdump -i any -nn port 80 -A -s 500
-s 0 就是显示包的所有内容
-c 选项 抓取固定个数的报文 可以抓取 number 个报文后退出。在网络包交互非常频繁的服务器上抓包比较有用,可能运维人员只想抓取 1000 个包来分析一些网络问题,就比较有用了
sudo tcpdump -i any -nn port 80 -c 5
-w 报文输出到文件
sudo tcpdump -i any port 80 -w test.pcap 生成的 pcap 文件就可以用 wireshark 打开进行更详细的分析了
也可以加上 -U 强制立即写到本地磁盘。性能较差
-S 显示绝对的序列号 不加都是默认从0开始 也就是相对的
相关布尔运算使用
tcpdump 真正强大的是可以用布尔运算符and(或&&)、or(或||)、not(或!)来组合出任意复杂的过滤器
抓取 ip 为 10.211.55.10 到端口 3306 的数据包
sudo tcpdump -i any host 10.211.55.10 and dst port 3306
抓取源 ip 为 10.211.55.10,目标端口除了22 以外所有的流量
sudo tcpdump -i any src 10.211.55.10 and not dst port 22
复杂分组问题
如果要抓取:来源 ip 为 10.211.55.10 且目标端口为 3306 或 6379 的包,按照前面的描述,我们会写出下面的语句
sudo tcpdump -i any src 10.211.55.10 and (dst port 3306 or 6379)
----上面这个是错误的 因为有特殊符号() 解决办法是使用单引号把复杂的组合条件包起来
sudo tcpdump -i any 'src 10.211.55.10 and (dst port 3306 or 6379)' ---这个是正确的
- 如果想显示所有的 RST 包,要如何来写 tcpdump 的语句呢?答案如下:
tcpdump 'tcp[13] & 4 != 0'

tcp[13] 表示 tcp 头部中偏移量为 13 字节,如上图中红色框的部分,
!=0 表示当前 bit 置 1,即存在此标记位,跟 4 做与运算是因为 RST 在 TCP 的标记位的位置在第 3 位(00000100)
如果想过滤 SYN + ACK 包,那就是 SYN 和 ACK 包同时置位(00010010),写成 tcpdump 语句就是
tcpdump 'tcp[13] & 18 != 0'
tcpdump输出解读
A机器用nc -l 8080启动一个 tcp 的服务器,然后启动 tcpdump 抓包(sudo tcpdump -i any port 8080 -nn -A )
B机器 用 nc 10.211.55.10 8080进行连接,然后输入"hello, world"回车 过一段时间 ctrl-c结束连接 整个抓包过程如下
1 16:46:22.722865 IP 10.211.55.5.45424 > 10.211.55.10.8080: Flags [S], seq 3782956689, win 29200, options [mss 1460,sackOK,TS val 463670960 ecr 0,nop,wscale 7], length 0
2 16:46:22.722903 IP 10.211.55.10.8080 > 10.211.55.5.45424: Flags [S.], seq 3722022028, ack 3782956690, win 28960, options [mss 1460,sackOK,TS val 463298257 ecr 463670960,nop,wscale 7], length 0
3 16:46:22.723068 IP 10.211.55.5.45424 > 10.211.55.10.8080: Flags [.], ack 1, win 229, options [nop,nop,TS val 463670960 ecr 463298257], length 0
4 16:46:25.947217 IP 10.211.55.5.45424 > 10.211.55.10.8080: Flags [P.], seq 1:13, ack 1, win 229, options [nop,nop,TS val 463674184 ecr 463298257], length 12
hello world
5 16:46:25.947261 IP 10.211.55.10.8080 > 10.211.55.5.45424: Flags [.], ack 13, win 227, options [nop,nop,TS val 463301481 ecr 463674184], length 0
6 16:46:28.011057 IP 10.211.55.5.45424 > 10.211.55.10.8080: Flags [F.], seq 13, ack 1, win 229, options [nop,nop,TS val 463676248 ecr 463301481], length 0
7 16:46:28.011153 IP 10.211.55.10.8080 > 10.211.55.5.45424: Flags [F.], seq 1, ack 14, win 227, options [nop,nop,TS val 463303545 ecr 463676248], length 0
8 16:46:28.011263 IP 10.211.55.5.45424 > 10.211.55.10.8080: Flags [.], ack 2, win 229, options [nop,nop,TS val 463676248 ecr 463303545], length 0
-
第 1~3 行是 TCP 的三次握手的过程
- 第 1 行 中,第一部分是这个包的时间(16:46:22.722865),显示到微秒级。接下来的 “10.211.55.5.45424 > 10.211.55.10.8080” 表示 TCP 四元组:包的源地址、源端口、目标地址、目标端口,中间的大于号表示包的流向。接下来的 “Flags [S]” 表示 TCP 首部的 flags 字段,这里的 S 表示设置了 SYN 标志,其它可能的标志有
- F:FIN 标志
- R:RST 标志
- P:PSH 标志
- U:URG 标志
- . :没有标志,ACK 情况下使用
接下来的 “seq 3782956689” 是 SYN 包的序号。需要注意的是默认的显示方式是在 SYN 包里的显示真正的序号,在随后的段中,为了方便阅读,显示的序号都是相对序号。
接下来的 “win 29200” 表示自己声明的接收窗口的大小
接下来用[] 包起来的 options 表示 TCP 的选项值,里面有很多重要的信息,比如 MSS、window scale、SACK 等
最后面的 length 参数表示当前包的长度
- 第 2 行是一个 SYN+ACK 包,如前面所说,SYN 包中包序号用的是绝对序号,后面的 win = 28960 也声明的发送端的接收窗口大小。
- 从第 3 行开始,后面的包序号都用的是相对序号了。第三行是客户端 B 向服务端 A 发送的一个 ACK 包。注意这里 win=229,实际的窗口并不是 229,因为窗口缩放(window scale) 在三次握手中确定,后面的窗口大小都需要乘以 window scale 的值 2^7(128),比如这里的窗口大小等于 229 * 2^7 = 229 * 128 = 29312
- 第 1 行 中,第一部分是这个包的时间(16:46:22.722865),显示到微秒级。接下来的 “10.211.55.5.45424 > 10.211.55.10.8080” 表示 TCP 四元组:包的源地址、源端口、目标地址、目标端口,中间的大于号表示包的流向。接下来的 “Flags [S]” 表示 TCP 首部的 flags 字段,这里的 S 表示设置了 SYN 标志,其它可能的标志有
-
第 4 行是客户端 B 向服务端 A 发送"hello world"字符串,这里的 flag 为
P.,表示 PSH+ACK。发送包的 seq 为 1:13,长度 length 为 12。窗口大小还是 229 * 128 -
第 5 行是服务端 A 收到"hello world"字符串以后回复的 ACK 包,可以看到 ACK 的值为 13,表示序号为 13 之前的所有的包都已经收到,下次发包从 13 开始发
-
第 6 行是客户端 B 执行 Ctrl+C 以后nc 客户端准备退出时发送的四次挥手的第一个 FIN 包,包序号还是 13,长度为 0
-
第 7 行是服务端 A 对 B 发出的 FIN 包后,也同时回复 FIN + ACK,因为没有往客户端传输过数据包,所以这里的 SEQ 还是 1
-
第 8 行是客户端 A 对 服务端 B 发出的 FIN 包回复的 ACK 包
当然可以用-w选项 输出到文件 然后用wireshark分析就更方便了
wireshark
图形化界面抓包工具,对应命令行版本是 tshark 用的比较少
抓包过滤
抓包的过程很耗 CPU 和内存资源而且大部分情况下我们不是对所有的包都感兴趣,因此可以只抓取满足特定条件的包,丢弃不感兴趣的包,比如只想抓取 ip 为172.18.80.49 端口号为 3306 的包,可以输入host 172.18.80.49 and port 3306,语法跟tcpdump差不多
可以在抓包之前设置
显示结果过滤 Display fliter
显示过滤可以算是 wireshark 最常用的功能了,与抓包过滤不一样的是,显示过滤不会丢弃包的内容,不符合过滤条件的包被隐藏起来,方便我们阅读。

过滤的方式常见的有以下几种:
- 协议、应用过滤器(ip/tcp/udp/arp/icmp/ dns/ftp/nfs/http/mysql)
- 字段过滤器(http.host/dns.qry.name)
比如我们只想看 http 协议报文,在过滤器中输入 http 即可

字段过滤器可以更加精确的过滤出想要的包,比如我们只想看锤科网站t.tt域名的 dns 解析,可以输入dns.qry.name == t.tt
再比如,我只想看访问锤科的 http 请求,可以输入http.host == t.tt
可以随便找一个 dns 的查询,找到查询报文,展开详情里面的内容,然后鼠标选中想过滤的字段,最下面的状态码就会出现当前 wireshark 对应的查看条件,比如下图中的dns.qry.name
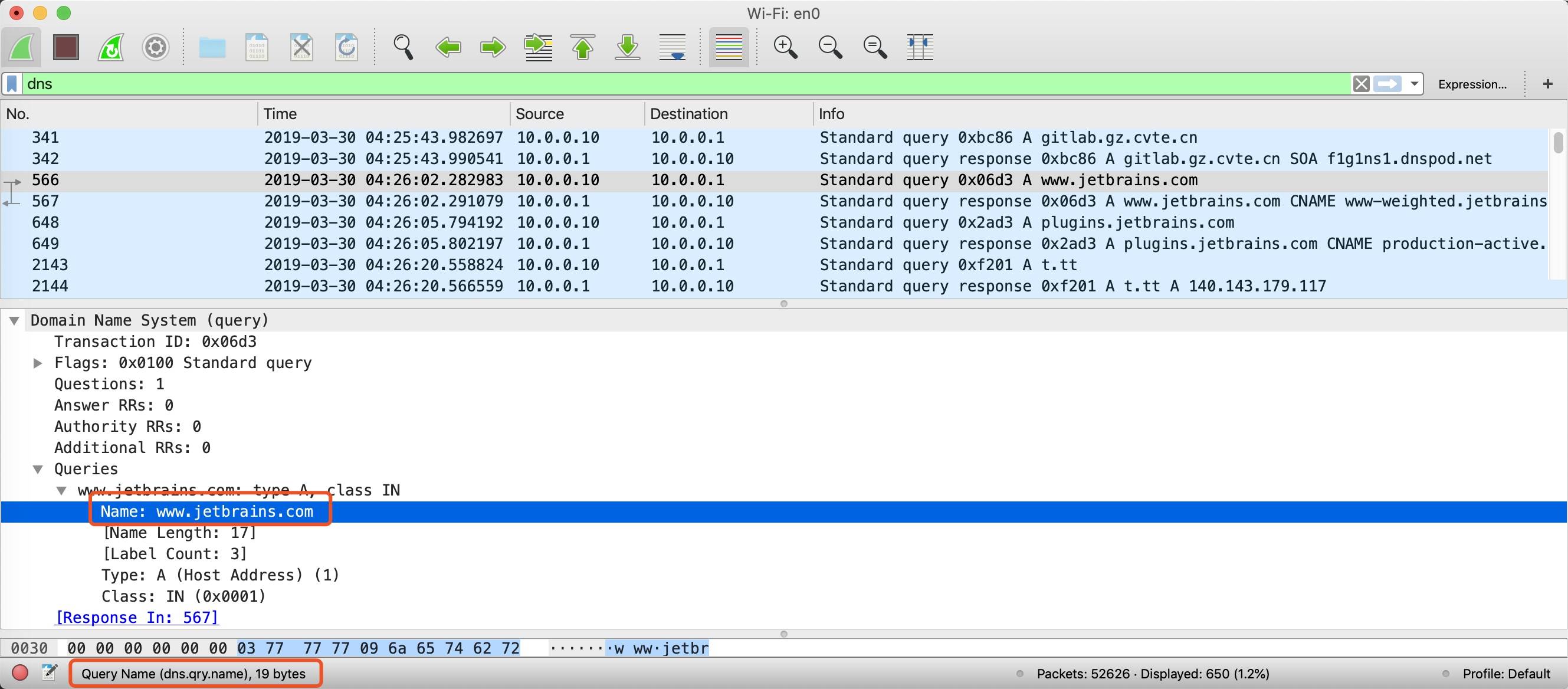
常用的查询条件有:
tcp 相关过滤器
- tcp.flags.syn==1:过滤 SYN 包
- tcp.flags.reset==1:过滤 RST 包
- tcp.analysis.retransmission:过滤重传包
- tcp.analysis.zero_window:零窗口
http 相关过滤器
- http.host==t.tt:过滤指定域名的 http 包
- http.response.code==302:过滤http响应状态码为302的数据包
- http.request.method==POST:过滤所有请求方式为 POST 的 http 请求包
- http.transfer_encoding == “chunked” 根据transfer_encoding过滤
- http.request.uri contains “/appstock/app/minute/query”:过滤 http 请求 url 中包含指定路径的请求
通信延迟常用的过滤器
http.time>0.5:请求发出到收到第一个响应包的时间间隔,可以用这个条件来过滤 http 的时延- tcp.time_delta>0.3:tcp 某连接中两次包的数据间隔,可以用这个来分析 TCP 的时延
- dns.time>0.5:dns 的查询耗时
wireshakr 所有的查询条件在这里可以查到:https:/ /www.wireshark.org/docs/dfref/
比较预算符
wireshark 支持比较运算符和逻辑运算符。这些运算符可以灵活的组合出强大的过滤表达式。
- 等于:== 或者 eq
- 不等于:!= 或者 ne
- 大于:> 或者 gt
- 小于:< 或者 lt
- 包含 contains
- 匹配 matches
- 与操作:AND 或者 &&
- 或操作:OR 或者 ||
- 取反:NOT 或者 !
比如想过滤 ip 来自 10.0.0.10 且是 TCP 协议的数据包:
ip.addr == 10.0.0.10 and tcp
协议分层解释
- Frame:物理层的数据帧
- Ethernet II:数据链路层以太网帧头部信息
- Internet Protocol Version 4:互联网层IP包头部信息
- Transmission Control Protocol:传输层的数据段头部信息,此处是TCP协议
- Hypertext Transfer Protocol:应用层 HTTP 的信息
跟踪 TCP 数据流(Follow TCP Stream)
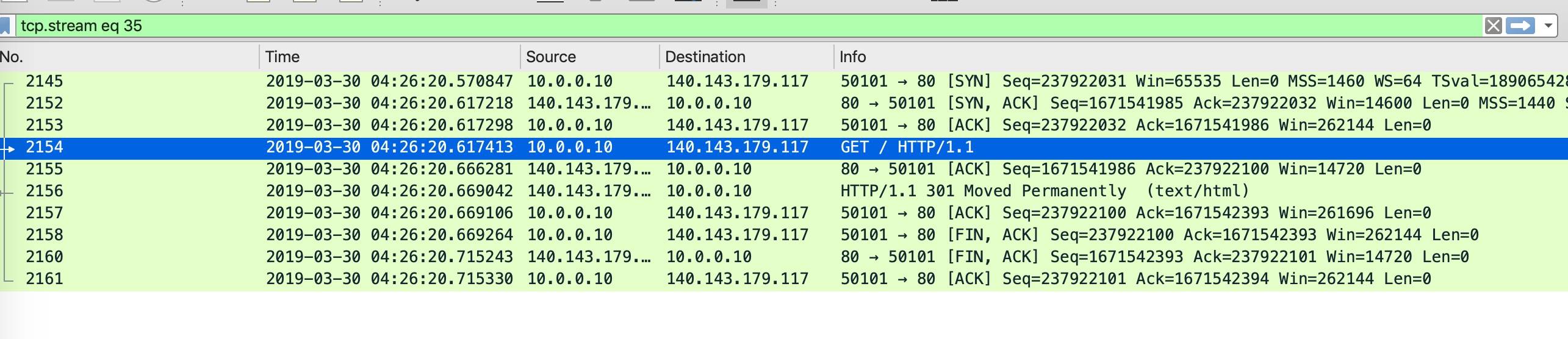
在实际使用过程中,跟踪 TCP 数据流是一个很高频的使用。我们通过前面介绍的那些过滤条件找到了一些包,大多数情况下都需要查看这个 TCP 连接所有的包来查看上下文。
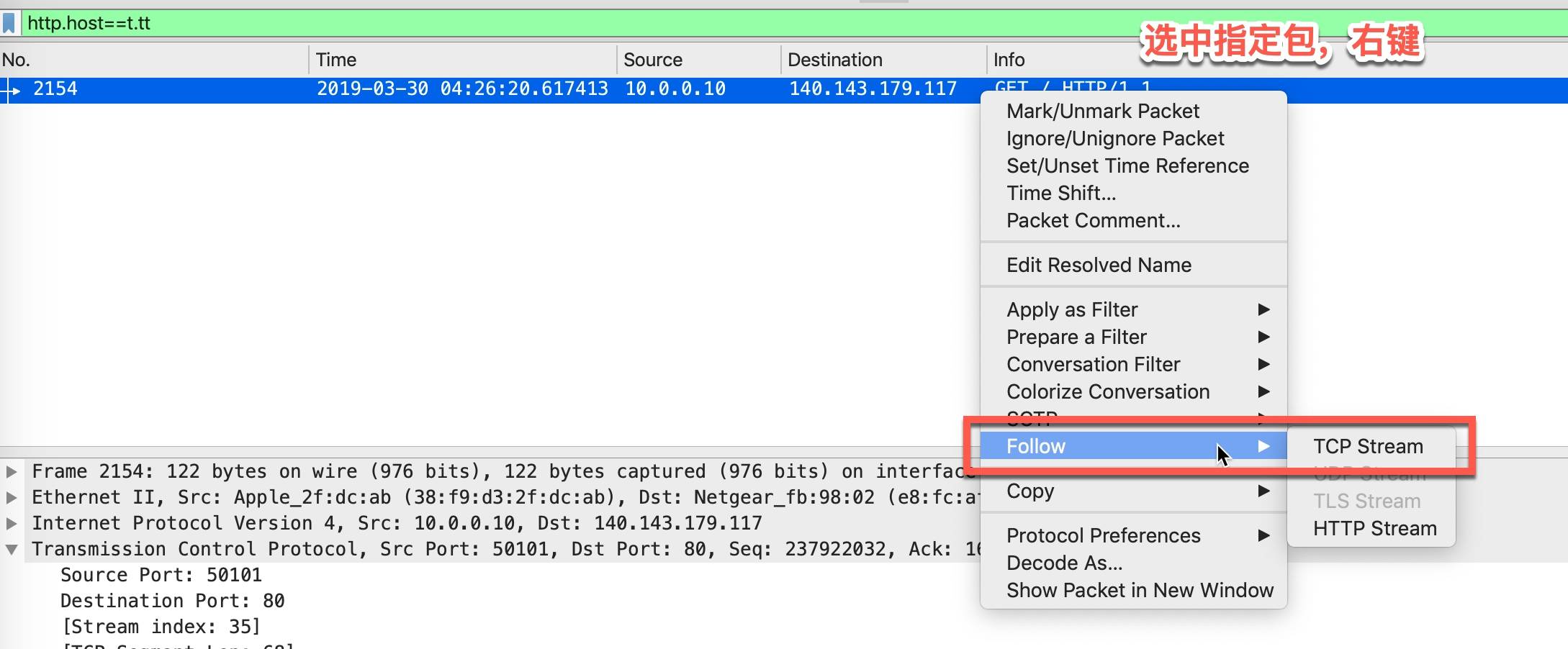
这样就可以查看整个连接的所有包交互情况了,如下图所示,三次握手、数据传输、四次挥手的过程一目了然
解密HTTPS包
随着 https 和 http2.0 的流行,https 正全面取代 http,这给我们抓包带来了一点点小困难。Wireshark 的抓包原理是直接读取并分析网卡数据。 下图是访问 www.baidu.com 的部分包截图,传输包的内容被加密了。
要想让它解密 HTTPS 流量,要么拥有 HTTPS 网站的加密私钥,可以用来解密这个网站的加密流量,但这种一般没有可能拿到。要么某些浏览器支持将 TLS 会话中使用的对称加密密钥保存在外部文件中,可供 Wireshark 解密流量。 在启动 Chrome 时加上环境变量 SSLKEYLOGFILE 时,chrome 会把会话密钥输出到文件。
SSLKEYLOGFILE=/tmp/SSLKEYLOGFILE.log /Applications/Google\ Chrome.app/Contents/MacOS/Google\ Chrome
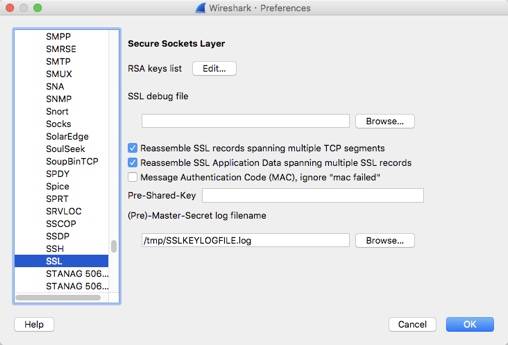
wireshark 可以在Wireshark -> Preferences... -> Protocols -> SSL打开Wireshark 的 SSL 配置面板,在(Pre)-Master-Secret log filename选项中输入 SSLKEYLOGFILE 文件路径。
抓包的一些应用实战(转载)
JDBC批量插入问题排查
几年前遇到过一个问题,使用 jdbc 批量插入,插入的性能总是上不去,看代码又查不出什么结果。代码简化以后如下:
public static void main(String[] args) throws ClassNotFoundException, SQLException {
Class.forName("com.mysql.jdbc.Driver");
String url = "jdbc:mysql://localhost:3306/test?useSSL=false";
Connection connection = DriverManager.getConnection(url, "root", "");
PreparedStatement statement = connection.prepareStatement("insert into batch_insert_test(name)values(?)");
for (int i = 0; i < 10; i++) {
statement.setString(1, "name#" + System.currentTimeMillis() + "#" + i);
statement.addBatch();
}
statement.executeBatch();
}
通过 wireshark 抓包,结果如下
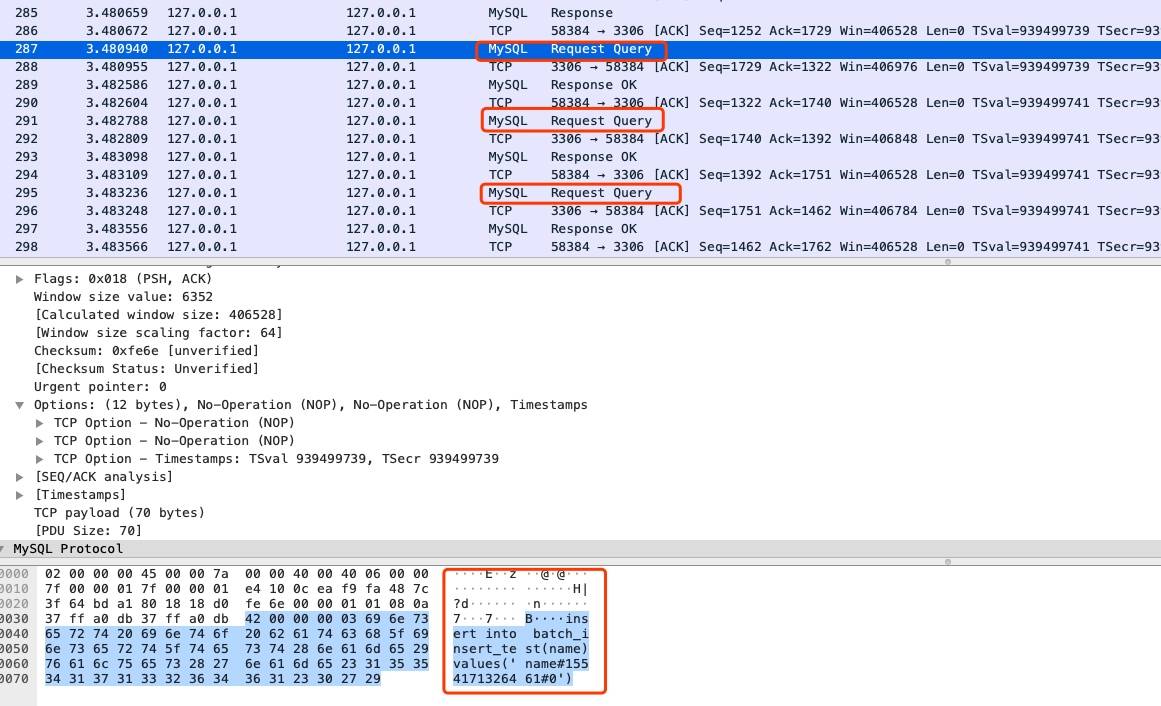
可以看到 jdbc 实际上是发送了 10 次 insert 请求,既不能降低网络通信的成本,也不能在服务器上批量执行。
单步调试,发现调用到了executeBatchSerially
看源码发现跟connection.getRewriteBatchedStatements()有关,当等于 true 时,会进入批量插入的流程,等于 false 时,进入逐条插入的流程。
修改 sql 连接的参数,增加rewriteBatchedStatements=true
// String url = "jdbc:mysql://localhost:3306/test?useSSL=false";
String url = "jdbc:mysql://localhost:3306/test?useSSL=false&rewriteBatchedStatements=true";
wireshark 抓包情况如下,可以确认批量插入生效了
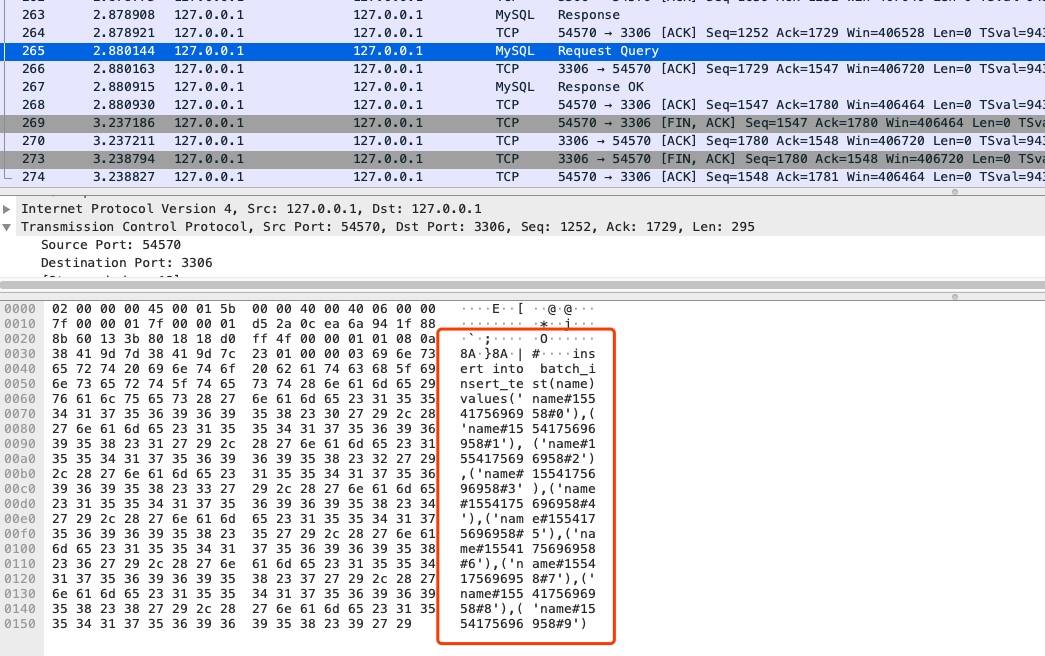
rewriteBatchedStatements 参数将
insert into batch_insert_test(name)values('name#1554175696958#0')
insert into batch_insert_test(name)values('name#1554175696958#1')
insert into batch_insert_test(name)values('name#1554175696958#2')
insert into batch_insert_test(name)values('name#1554175696958#3')
insert into batch_insert_test(name)values('name#1554175696958#4')
insert into batch_insert_test(name)values('name#1554175696958#5')
insert into batch_insert_test(name)values('name#1554175696958#6')
insert into batch_insert_test(name)values('name#1554175696958#7')
insert into batch_insert_test(name)values('name#1554175696958#8')
insert into batch_insert_test(name)values('name#1554175696958#9')
改写为真正的批量插入
insert into batch_insert_test(name)values
('name#1554175696958#0'),('name#1554175696958#1'),
('name#1554175696958#2'),('name#1554175696958#3'),
('name#1554175696958#4'),('name#1554175696958#5'),
('name#1554175696958#6'),('name#1554175696958#7'),
('name#1554175696958#8'),('name#1554175696958#9')
思考
我们经常会用很多第三方的库,这些库我们一般没有精力把每行代码都读通读透,遇到问题时,抓一些包也许就可以很快确定问题的所在,这就是抓包网络分析的魅力所在。
Nginx 频繁出现 OOM问题排查
在最近的一次百万长连接压测中,32C 128G 的四台 Nginx 频繁出现 OOM(内存耗尽)
现象描述
这是一个 websocket 百万长连接收发消息的压测环境,客户端 jmeter 用了上百台机器,经过四台 Nginx 到后端服务,简化后的部署结构如下图所示。
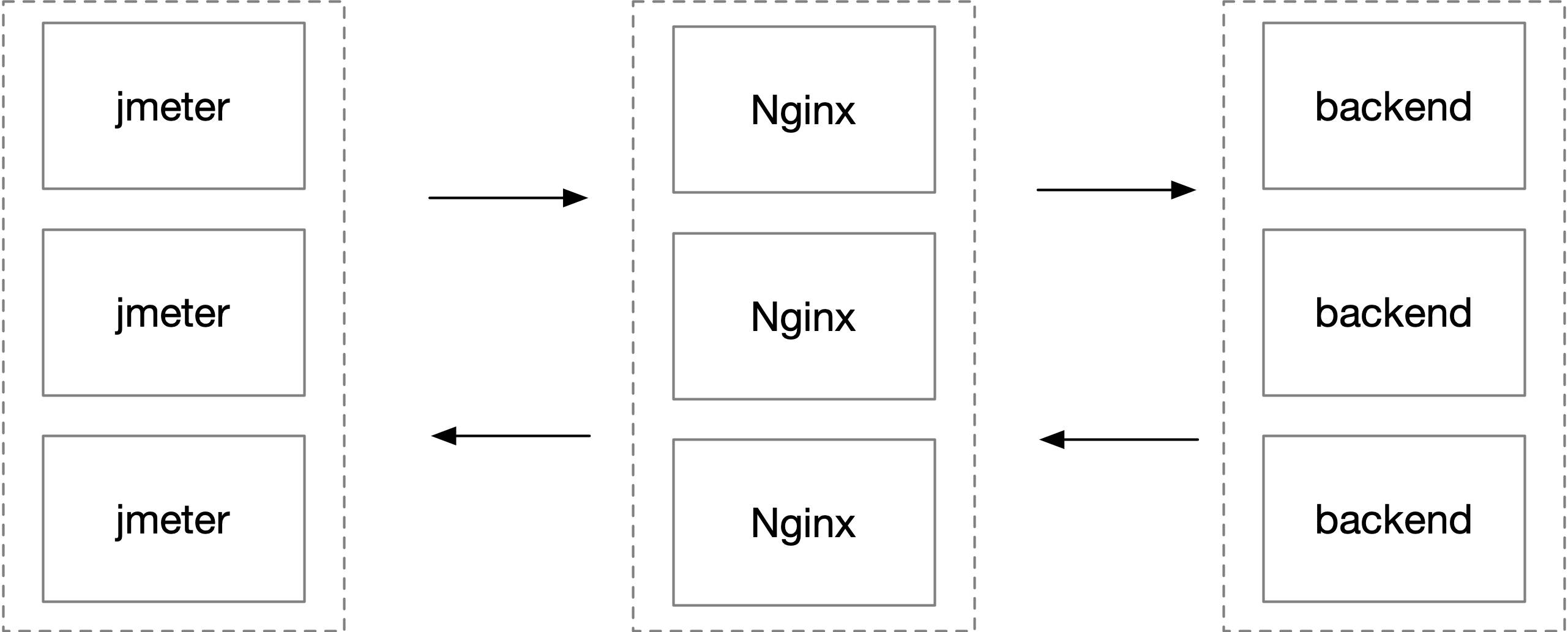
在维持百万连接不发数据时,一切正常,Nginx 内存稳定。在开始大量收发数据时,Nginx 内存开始以每秒上百 M 的内存增长,直到占用内存接近 128G,woker 进程开始频繁 OOM 被系统杀掉。32 个 worker 进程每个都占用接近 4G 的内存。dmesg -T 的输出如下所示
[Fri Mar 13 18:46:44 2020] Out of memory: Kill process 28258 (nginx) score 30 or sacrifice child
[Fri Mar 13 18:46:44 2020] Killed process 28258 (nginx) total-vm:1092198764kB, anon-rss:3943668kB, file-rss:736kB, shmem-rss:4kB
work 进程重启后,大量长连接断连,压测就没法继续增加数据量
排查过程分析
- 拿到这个问题,首先查看了 Nginx 和客户端两端的网络连接状态,使用
ss -nt命令可以在 Nginx 看到大量 ESTABLISH 状态连接的 Send-Q 堆积很大,客户端的 Recv-Q 堆积很大。Nginx 端的 ss 部分输出如下所示
State Recv-Q Send-Q Local Address:Port Peer Address:Port
ESTAB 0 792024 1.1.1.1:80 2.2.2.2:50664
...
如果不是listen套接字 这里的Send-Q就是发送缓冲区的大小 说明nginx发给客户端的缓冲区太大了
- 在 jmeter 客户端抓包偶尔可以看到较多零窗口,如下所示。
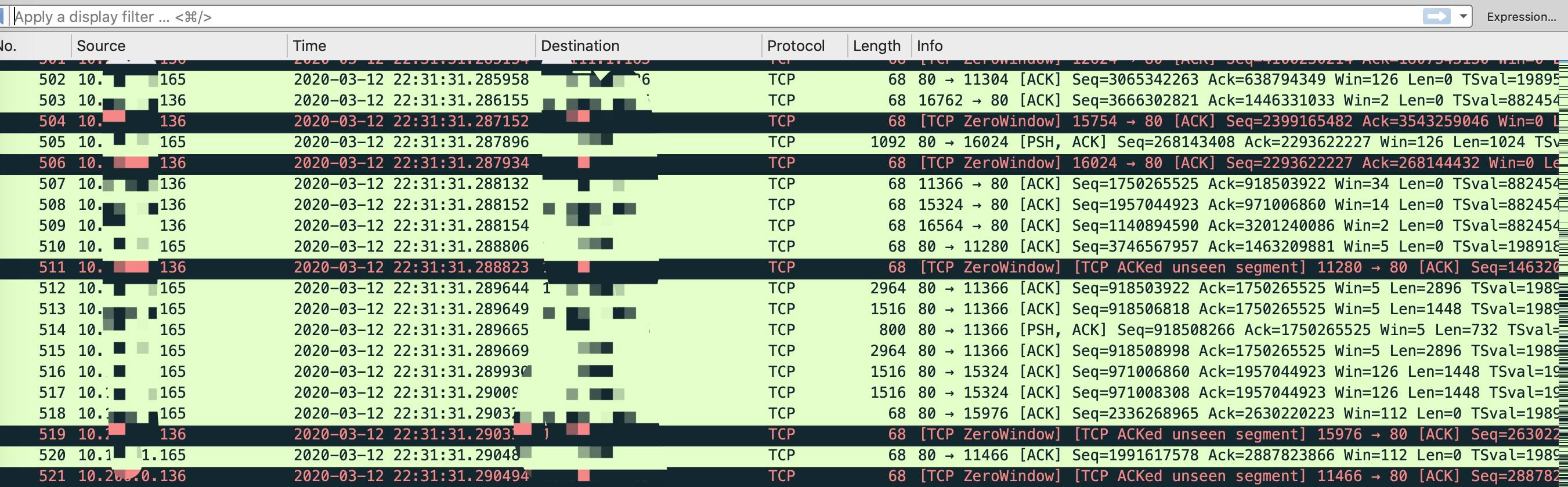
到了这里有了一些基本的方向,首先怀疑的就是 jmeter 客户端处理能力有限,有较多消息堆积在中转的 Nginx 这里。
-
为了验证想法,想办法 dump 一下 nginx 的内存看看。因为在后期内存占用较高的状况下,dump 内存很容易失败,这里在内存刚开始上涨没多久的时候开始 dump。
首先使用 pmap 查看其中任意一个 worker 进程的内存分布,这里是 4199,使用 pmap 命令的输出如下所示。
pmap -x 4199 | sort -k 3 -n -r 00007f2340539000 475240 461696 461696 rw--- [ anon ] ...随后使用
cat /proc/4199/smaps | grep 7f2340539000查找某一段内存的起始和结束地址,如下所示。cat /proc/3492/smaps | grep 7f2340539000 7f2340539000-7f235d553000 rw-p 00000000 00:00 0随后使用 gdb 连上这个进程,dump 出这一段内存。
gdb -pid 4199 dump memory memory.dump 0x7f2340539000 0x7f235d553000随后使用 strings 命令查看这个 dump 文件的可读字符串内容,可以看到是大量的请求和响应内容。
这样坚定了是因为缓存了大量的消息导致的内存上涨。随后看了一下 Nginx 的参数配置
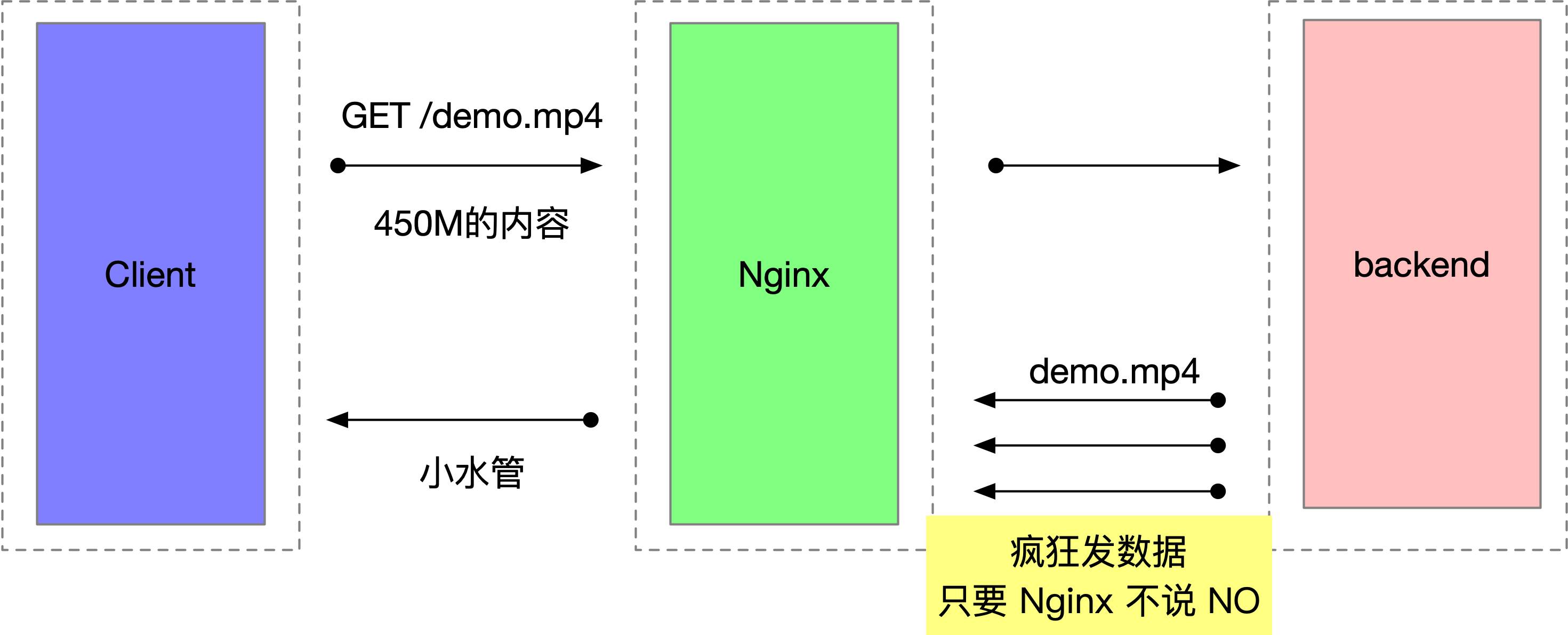
location / { proxy_pass http://xxx; proxy_set_header X-Forwarded-Url "$scheme://$host$request_uri"; proxy_redirect off; proxy_http_version 1.1; proxy_set_header Upgrade $http_upgrade; proxy_set_header Connection "upgrade"; proxy_set_header Cookie $http_cookie; proxy_set_header Host $host; proxy_set_header X-Forwarded-Proto $scheme; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; client_max_body_size 512M; client_body_buffer_size 64M; proxy_connect_timeout 900; proxy_send_timeout 900; proxy_read_timeout 900; proxy_buffer_size 64M; proxy_buffers 64 16M; proxy_busy_buffers_size 256M; proxy_temp_file_write_size 512M; }可以看到 proxy_buffers 这个值设置的特别大。可以模拟重现:
解决方案
因为要支持上百万的连接,针对单个连接的资源配额要小心又小心。一个最快改动方式是把 proxy_buffering 设置为 off,如下所示。
proxy_buffering off;
经过实测,在压测环境修改了这个值以后,以及调小了 proxy_buffer_size 的值以后,内存稳定在了 20G 左右,没有再飙升过.
后面可以开启 proxy_buffering,调整 proxy_buffers 的大小可以在内存消耗和性能方面取得更好的平衡
- Nginx 的 buffering 机制设计的初衷确实是为了解决收发两端速度不一致问题的,没有 buffering 的情况下,数据会直接从后端服务转发到客户端,如果客户端的接收速度足够快,buffering 完全可以关掉。但是这个初衷在海量连接的情况下,资源的消耗需要同时考虑进来,如果有人故意伪造比较慢的客户端,可以使用很小的代价消耗服务器上很大的资源。
- 其实这是一个非阻塞编程中的典型问题,接收数据不会阻塞发送数据,发送数据不会阻塞接收数据。如果 Nginx 的两端收发数据速度不对等,缓冲区设置得又过大,就会出问题了。
思考
有过程中一些辅助的判断方法,比如通过 strace、systemtap 工具跟踪内存的分配、释放过程,这里没有展开,这些工具是分析黑盒程序的神器。
除此之外,在这次压测过程中还发现了 worker_connections 参数设置不合理导致 Nginx 启动完就占了 14G 内存等问题,这些问题在没有海量连接的情况下是比较难发现的。
最后,底层原理是必备技能,调参是门艺术。


...