高并发性能相关指标或术语回顾
连接相关
服务端能保持,管理,处理多少客户端的连接
- 活跃连接数:所有ESTABLISHED状态的TCP连接,某个瞬时,这些连接正在传输数据。如果您采用的是长连接的情况,一个连接会同时传输多个请求。也可以间接考察后端服务并发处理能力,注意不同于并发量。
- 非活跃连接数:表示除ESTABLISHED状态的其它所有状态的TCP连接数。
- 并发连接数:所有建立的TCP连接数量。=活跃连接数+非活跃连接数。
- 新建连接数:在统计周期内,从客户端连接到服务器端,新建立的连接请求的平均数。主要考察应对 突发流量或从正常到高峰流量的能力。如:秒杀、抢票场景。
- 丢弃连接数:每秒丢弃的连接数。如果连接服务器做了连接熔断处理,这部分数据即熔断的连接
在linux上socket连接体现上就是文件描述符,高并发中相关的参数一定要调优。
流量相关
主要是网络带宽的配置。
- 流入流量:从外部访问服务器所消耗的流量。
- 流出流量:服务器对外响应的流量。
数据包数
数据包是TCP三次握手建立连接后,传输的内容封装
- 流入数据包数:服务器每秒接到的请求数据包数量。
- 流出数据包数:服务器每秒发出的数据包数量。
如果数据包太大可以考虑压缩,因为传输的数据包小 效率一般会提升,但解压缩也需要性能消耗,不能无限制压缩
应用传输协议
传输协议压缩率好,传输性能好,对并发性能提升高。但是也需要看调用双方的语言可以使用协议才行。可以自己定义,也可以使用成熟的传输协议。比如redis的序列化传输协议、json传输协议、Protocol Buffers传输协议、http协议等。 尤其在 rpc调用过程中,这个传输协议选择需要仔细甄别选型。
长连接、短连接
- 长连接是指在一个TCP连接上,可以重用多次发送数据包,在TCP连接保持期间,如果没有数据包发送,需要双方发检测包以维持此连接。
- 半开连接的处理:当客户端与服务器建立起正常的TCP连接后,如果客户主机掉线(网线断开)、电源掉电、或系统崩溃,服务器将永远不会知道。长连接中间件,需要处理这个细节。linux默认配置2小时,可以配置修改。不过现实项目一般不用系统的这个机制,很多直接使用客户端心跳包维持连接,服务端启动定时器,超时就close掉连接
- 短连接是指通信双方有数据交互时,就建立一个TCP连接,数据发送完成后,则断开此TCP连接。但是每次建立连接需要三次握手、断开连接需要四次挥手。
- 关闭连接最好由客户端主动发起,TIME_WAIT这个状态最好不要在服务器端,减少占用资源,当然如果是使用短连接,客户端高频的出现TIME_WAIT也要注意临时端口耗尽的问题,可以有很多优化(比如SO_REUSEADDR选项、SO_LINGER选项,临时端口范围调优等)
选择建议:
- 在客户端数量少场景一般使用长连接。后端中间件、微服务之间通信最好使用长连接。如:数据库连接,duboo默认协议等。
- 而大型web、app应用,使用http短连接(http1.1的keep alive变相的支持长连接,但还是串行请求/响应交互)。http2.0支持真正的长连接。
- 长连接会对服务端耗费更多的资源,上百万用户,每个用户独占一个连接,对服务端压力多大,成本多高。IM、push应用会使用长连接,但是会做很多优化工作。
- 由于https需要加解密运算等,最好使用http2.0(强制ssl),传输性能很好。但是服务端需要维持更多的连接。
并发连接和并发量
- 并发连接数:=活跃连接数+非活跃连接数。所有建立的TCP连接数量。网络服务器能并行管理的连接数。
- 并发量:瞬时通过活跃连接传输数据的量,这个量一般在处理端好评估。跟活跃连接数没有绝对的关系。网络服务器能并行处理的业务请求数。
- rt响应时间:各类操作单机rt肯定不相同。比如:从cache中读数据和分布式事务写数据库,资源的消耗不同,操作时间本身就不同。
- 吞吐量:QPS/TPS,每秒可以处理的查询或事务数,这个是关键指标。
IO多路复用
相关观念回顾
用户空间与内核空间
-
linux操作系统采用虚拟存储器技术,对于32位操作系统,内存寻址空间就是4G(2^32)。操作系统的核心叫做内核kernel,独立于普通的Application,内核是可以访问受保护的内存空间,也有访问底层硬件的权限。为了保证用户进程不能直接操作内核(内核要足够稳定),所以操作系统将虚拟空间划分2部分,一部分叫做内核空间,一部分叫做用户空间。
-
linux操作系统32位,将最高的1G(虚拟地址0xC0000000到0xFFFFFFFF) 是给内核使用的,叫做内核空间,而较低的3G字节(虚拟地址从0x00000000到0xBFFFFFFF),给各个应用进程使用,叫做用户空间。
-
每个进程可以通过系统调用进入内核,因此linux内核有系统内的所有进程共享,空间分配图大致如下:
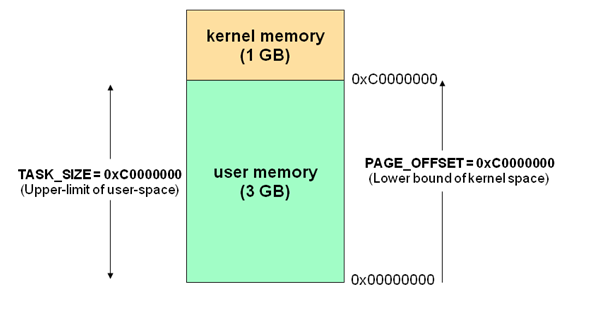
-
linux系统内部结构大值图示:
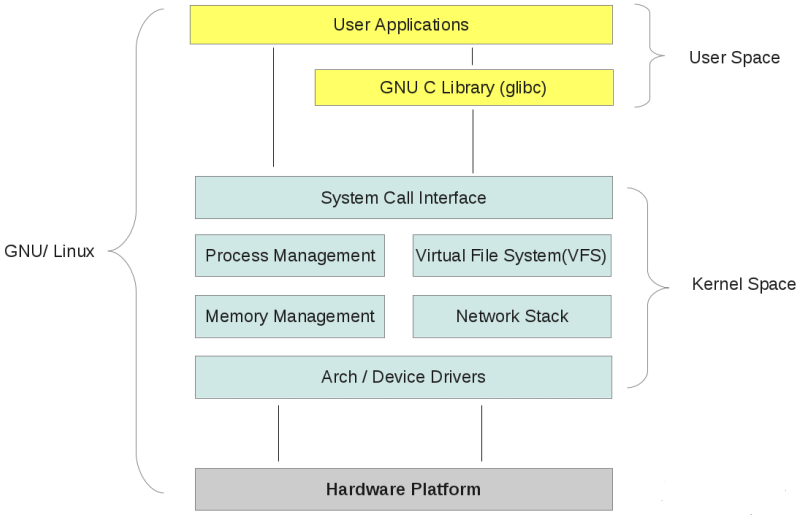
-
当一个任务(往往是进程或者线程)执行系统调用也就是执行内核代码,进程就进入内核态,当任务执行用户自己的代码,称为处于用户运行态(用户态)
进程切换
-
为了控制各个进程的执行,内核必须有能力挂起某个正在运行的进程(正在使用cpu),并具有恢复以前挂起进程并执行的能力。这种挂起与恢复执行往往被称为进程切换,任何进程都是在操作系统内核的支持下才能正常运行,跟内核密切相关。
-
进程切换大致涉及内容:
- 保存处理机的上下文,比如程序计数器、寄存器
- 更新进程PCB(Process Control Block)信息
- 将进程PCB放入相应的队列,如就绪队列,某些时间的阻塞等待队列等等
- 选择另外一个进程执行,更新其PCB信息
- 更新内存管理的数据结构
- 恢复处理机上下文
-
linux一个注释
- 当一个进程在执行时,CPU的所有寄存器中的值、进程的状态以及堆栈中的内容被称为该进程的上下文。当内核需要切换到另一个进程时,它需要保存当前进程的所有状态,即保存当前进程的上下文,以便在再次执行该进程时,能够必得到切换时的状态执行下去。在LINUX中,当前进程上下文均保存在进程的任务数据结构中。在发生中断时,内核就在被中断进程的上下文中,在内核态下执行中断服务例程。但同时会保留所有需要用到的资源,以便中继服务结束时能恢复被中断进程的执行
进程阻塞
- 正在执行的进程,由于等待某些事件(等待系统资源,等待某种操作完成,新的数据尚未到达或者没有新的工作等),则会有操作系统自动执行阻塞原语(Block),使自己由运行状态变为阻塞状态,进度阻塞状态之后,进程不占用cpu资源,等待的事件完成后再由内核将其唤醒。
文件描述符
- File Descriptor为计算机科学中的一个术语,是一个抽象概念,用于表述指向文件的引用
- 在形式上是一个非负整数,实际上是一个索引值,指向内核为每个进程维护的一个打开文件的记录表。
- 当进程打开一个现有文件或者创建一个新文件,内核将返回其一个文件描述符
- 一些类Unix底层程序往往会围绕文件描述符展开工作
缓冲I/O
- linux有I/O缓存机制,操作系统会将I/O数据缓存在文件系统的页缓存(page catch)中,也就是数据往往先被操作系统拷贝到内核的缓冲区,然后再由操作系统内核的缓冲区拷贝到用户程序的地址空间。
- 缓存I/O机制导致数据在传输过程中需要用户空间和内核空间进行多次拷贝,这就必然导致cpu和内存开销
常见I/O模式复习
-
就拿read距离,数据先被拷贝到内核缓存区,然后再拷贝到用户地址空间,所以会经过2个阶段
- 内核等待数据准备(Waiting for the data to be ready)
- 数据从内核拷贝到进程(Copying the data from the kernel to the process)
-
正是因为I/O缓存机制带来的2阶段,所以有了linux系统常见的5种I/O模式
-
阻塞I/O ( blocking IO)
-
非阻塞I/O (nonblocking IO)
-
I/O多路复用 (IO multiplexing)
-
信号驱动I/O (signal driven IO)
-
异步I/O ( asynchronous IO)
其中信号驱动IO实际开发中用到的不太多,下面复习下几个常用的IO模式
-
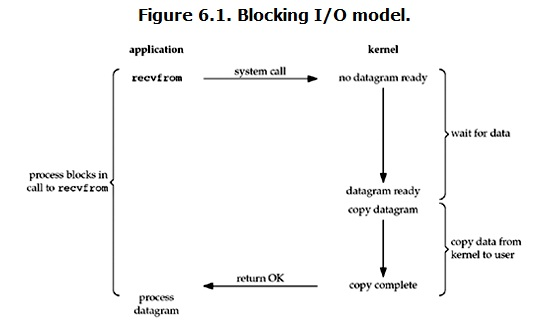
Blocking IO 阻塞IO
-
默认linux所有的socket都是blocking的(有API设置为nonblocking),典型读操作流程如下:
-
process call recv/recvform —>process blocking 进程执行系统调用 进程阻塞
- Kernel wait for the data 内核等待缓冲区数据达到(网络IO数据到缓冲区一般需要一定时间) process still blocking
- Data is ready ,copy data to user 数据达到后 内核将其拷贝到用户空间
- process unblock to run 进程解除阻塞,这个地方也需要cpu调度,其实也需要时间
blocking IO的特点就是IO执行的2个阶段,进程一致处于阻塞状态 不能执行其它任务
下面再摘一个图:
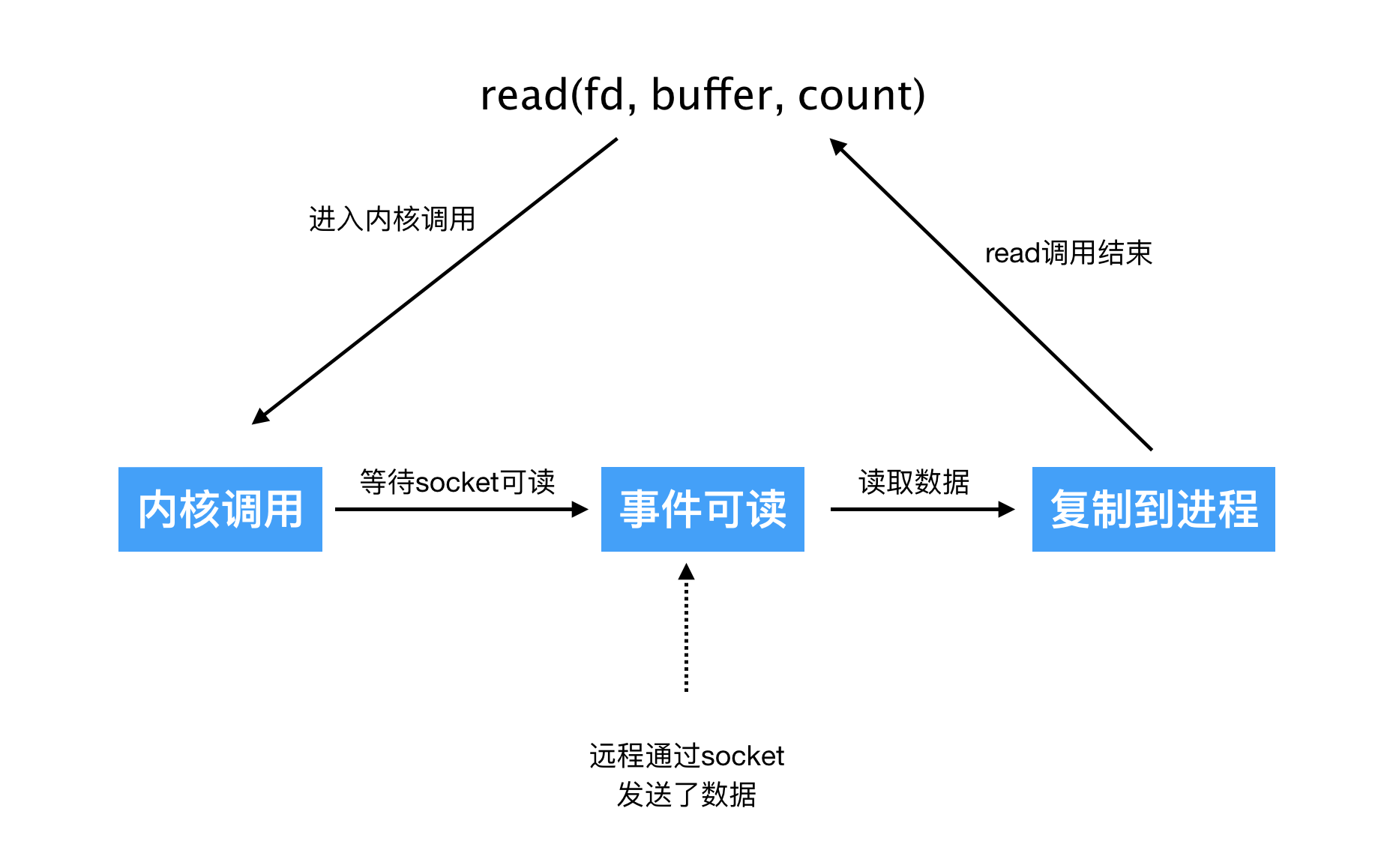
NonBlocking IO 非阻塞IO
- 可以调用API将socket设置为non-blocking 大致流程如下
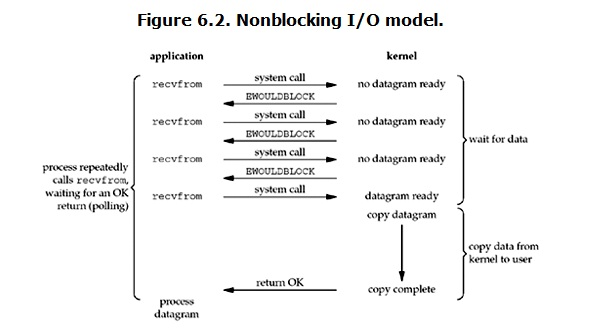
while ( recv(data)!=OK ){//系统调用recv不会阻塞,如果data is not ready,内核立马返回失败
wait sometime;//进程判断失败 往往休眠一定时间 再次调用recv系统调用
}
- 因为没有阻塞 系统调用会立马返回,但往往数据不会立马ready,所以非阻塞IO往往要不断的执行系统调用询问内核数据是否准备好了
IO multiplexing IO多路复用
-
这里常常就是指的select、pol、epoll,多路是指管理多个文件描述符,复用是指同一个进程或者一个线程,所以总结起来就是同一个进程(线程)管理多个文件描述符,提高IO处理效率的技术
-
select方式多路复用图解
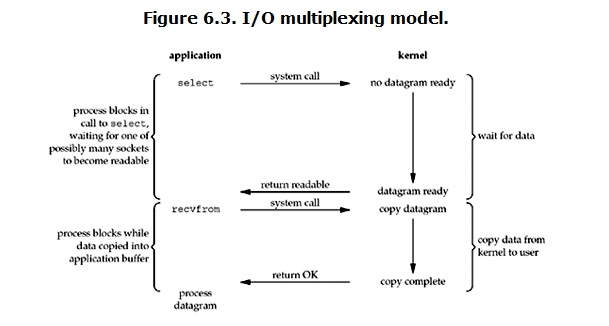
select过程大致如下
- 进程首先要将需要管理的描述符扔进select集合
- 进程调用select API(往往会设置超时时间,因为不设置没有数据到达就需要循环select),此时进程进入blocking状态
- 内核收到api调用就会循环监视注册的文件描述符对应的数据是否准备好了 如果有一个好了,select就立马返回
- 然后进程收到select返回 再调用read操作,将数据从内核拷贝到用户进程
-
select模式跟阻塞IO模式没有太大的不同,而且有2次系统调用(select、recv),普通的阻塞只有一个recv,但select的优势在于一个进程可以管理很多个文件描述符,也就是同时处理多个链接(socket conn)
-
如果需要处理的连接数不高的话,单任务select/poll/epoll的服务器 不一定比多任务的blocking IO性能高,因为让内核轮询每个描述符也是需要花费时间的,有可能延迟会更大,IO多路复用的优势在于能够处理更多的连接,而不是单个连接的处理速度更快。
-
IO多路复用下一般都将socket设置为non-blocking,而且要注意此时进程还是blocking的 只不过是被select/poll/epoll调用blocking,之前是被recvfrom调用blocking,但这个blocking的代价较小,因为我们可以管理更多的套接字。
Asynchronous IO 异步IO
-
异步IO个人接触的也不多,也是大致了解流程,看个图:
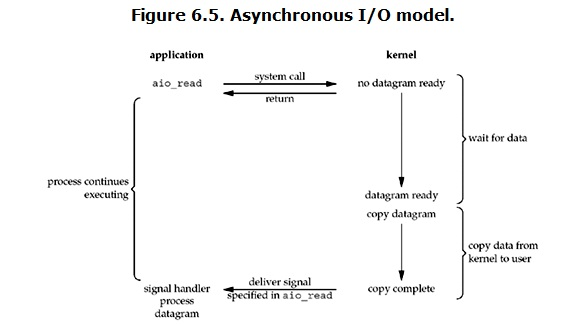
-
用户发起异步read操作后,kernel直接返回,进程也该干嘛干嘛,没有blocking
-
kernel等数据ready后 copy to user,然后给用户进程发送一个信号(singnal)
-
进程收到信号,调用注册的处理函数进行数据读取
-
貌似异步IO非常NB,但其实linux并没有实现一个完美的AIO,而且异步IO必须预先分配缓存,这个可能造成内存浪费,这都可能是AIO没有流行的原因
Blocking与non-blocking 阻塞与非阻塞
- 通常是说调用操作后,如何数据尚未到达,或者不具备条件,kernel是否返回,如果立马返回(不管有无数据),就是non-blocking,如果kernel等待数据到达,没有立马返回,那就是阻塞
Synchronous IO与asynchronous IO
Posix定义如下:
- A synchronous I/O operation causes the requesting process to be blocked until that I/O operation completes
- An asynchronous I/O operation does not cause the requesting process to be blocked
如果执行IO操作 进程被block就是同步,否则就是异步 上面的4种IO模式,除了最后的AIO都是同步IO,IO多路复用虽然将socket设置为non-blocking,但其实调用select/poll/epoll还是会blocking
几种IO模式比较图

同步阻塞BIO 服务端单任务
listenFd=socket(...);//创建socket
bind(listenFd,...);//绑定端口
listen(listenFd,...);//开启监听
while(1) {
// accept阻塞
client_fd = accept(listen_fd);//这里会阻塞 导致没法及时处理已经连接的客户端的请求
if (recv(client_fd)) {//读取客户端请求数据 这里也会阻塞,会导致没法接受新的客户端请求
// logic
send(client_fd,...);//回包 这里也会阻塞,会导致没法接受新的客户端请求
}
}
// 这种模式教学可以,实际项目中没法处理高并发的请求
同步非阻塞 服务端单任务
listenFd=socket(...);//创建socket
setNonblocking(listen_fd)
bind(listenFd,...);//绑定端口
listen(listenFd,...);//开启监听
while(1) {
// accept阻塞
client_fd = accept(listen_fd);//这里会阻塞 导致没法及时处理已经连接的客户端的请求
setNonblocking(client_fd);//设置为非阻塞
fds.add(client_fd);//加入轮询集合;
for( fd in fds){//循环检查
if (recv(client_fd)) {//读取客户端请求数据 这里也会阻塞,会导致没法接受新的客户端请求
// logic
send(client_fd,...);//回包 这里也会阻塞,会导致没法接受新的客户端请求
}
}
}
//处理小量并发是没有问题,但比较浪费cpu,因为每一轮循环都要针对每一个客户端套接字执行检查
//同时因为是单任务,遇到高并发肯定也要歇菜,假设有1000个client,第一个发送了请求,但是for循环检查的时候跳过了,然后要等到其它999个连接都检查处理完了,才能轮到这个client,很有可能已经超时了
同步阻塞BIO 服务端多并发任务
listenFd=socket(...);//创建socket
bind(listenFd,...);//绑定端口
listen(listenFd,...);//开启监听
while(1) {
// accept阻塞
client_fd = accept(listen_fd);//主进程 或者主线程只负责accept新的client连接
new ThreadProcess(client_fd){//这里开启多任务(多线程或者多进程),一个client一个处理任务线程(进程)
if (recv(fd)) {//
// logic process
send(client_fd,...);//回包
}
}
}
//并发量不是很大的时候,这种模式是能够良好应对的,但如果并发量很大,比如上万,大量的线程或者进程也会占用大量内存,而且进程切换或者线程切换都会浪费cpu,就会导致真正工作的任务比例往往很低,所以这种模式遇到真正高并发也会歇菜。
//用go语言实现一个这样的模式非常简单 来一个client就开启一个routine去处理即可
IO多路复用—select
API原型
- //将一个fd从关心的fdset中移除 其实就是将对应的坑位置0 void FD_CLR(fd, fd_set *fdset);
- // 检查fd是否在对应的fdset中 也就是检查对应的坑位是否为1 int FD_ISSET(fd, fd_set *fdset);
- //将fd增加到要关心的fdset集合中 也就是将对应fdset坑位置1 比如客户端socket fd为9,就是将fdset[9]设置为1 void FD_SET(fd, fd_set *fdset);
- // 清空要关心的fdset集合 将fdset数组全部置0 void FD_ZERO(fd_set *fdset);
- // nfds为最大检查描述符 select将对fdset数组0—>ndfs下标做检查 如果下标对应的value为1 则需要检查描述符是否具备条件了 不用1024个都检查,传入这个最大检查描述符是为了提高select轮询的效率 //readfds为关心读事件的描述符集合 writefds为关心写事件的描述符集合 errorfds为关心异常事件的描述符集合 //timeout为一个结构体 如何设置为null,则对应3个fdset若都没有就绪的描述符 进程将一直blocking //timeout如果设置为0 则select检查一轮将直接返回 不会等待 //timeout如果设置为具体的秒+微秒 则select最多等待设置的时间,如果没有就返回 //同时要说明的是select是轮询所有设置fdset中的所有value为1的描述符,如何符合要求就全部都返回 int select(int nfds, fd_set *restrict readfds, fd_set *restrict writefds, fd_set *restrict errorfds, struct timeval *restrict timeout);
- 关于 fd_set一般是一个int类型数组 一般初始化大小为1024 用来保存哪些fd需要检查,这个1024是可以调整的,但比较麻烦这也是select不足的地方,而且能监控的一般没有1024,因为进程或者线程一般都有打开的文件描述符,比如标准输入输出出错,或者打开的有日志文件等等。
不足
- 能监控的描述符数量有限 修改起来也比较麻烦
- 每次select都需要全部设置一遍需要关心的fdset集合,这就涉及到用户态到内核态的拷贝 效率不会很高
- select内部实现是轮询,不管描述符对应是否就绪,所以性能也不会太高 ,当然如果监控的套接字都非常活跃,那这个轮询性能问题也可以忽略(但正是因为都非常活跃,所以select返回后单任务处理也会遇到瓶颈,因为大量活跃的连接等待处理,但是只有一个单任务进程/线程在处理)
其它说明
- select监控的socketfd 跟socketfd本身是否是blocking没有关系,所有套接字是阻塞时真正recv或者write的时候 如果数据不具备条件则内核直接返回或者阻塞等待,selelct只是检查数据是否具备读条件了,没有发生真正读写,而且是内核直接判断读写缓冲区是否符合条件的
- 但不能说调用select的进程是不阻塞的,理论上调用了select也是一直阻塞的,只是阻塞时间的长短(timeout设置为0 只轮询一次就返回,如果为null,无限等待直到至少有一个套接字符合条件,如果设置为具体时间,则最多等待这个设置时间),只是进程不是因为调用recv或者write阻塞,而是调用select阻塞,而且返回的可以是多个符合读写的fd。
代码
select示例代码转载加注释,简单优化c
```c #includeIO多路复用—poll
API原型
# include <poll.h>
int poll ( struct pollfd * fds, unsigned int nfds, int timeout);
struct pollfd {
int fd; /* 要监控的文件描述符 如果为负值 内核会直接忽略 可以通过修改为-1 让内核不再监控*/
short events; /* 期待等待的事件 */
short revents; /* 实际发生了的事件 */
} ;
-
poll跟select整体机制是一样的 也是传入需要监控的fd集合 然后轮询 只是数据结构不是用int数组,而是改为pollfd结构体数组,所以没有了大小数量限制,对于每个关心的描述符可以更灵活的设置期待时间 代码使用起来更加灵活
-
第一个参数fds为需要监控的fd信息结构体数组指针 每次poll之前都可以动态的添加或者移除(通常直接设置对应的fd为-1)
-
nfds为第一个参数fds的size也就是需要监控的fd的个数
-
timeout为超时时间
-
If timeout is greater than zero, it specifies a maximum interval (in milliseconds) to wait for any file descriptor to
become ready. >0 单位毫秒 内核最多等待timeout毫秒
-
If timeout is zero, then poll() will return without blocking. =0 如果没有描述符就位,直接返回不阻塞,如果有就位的就会立马返回
-
If the value of timeout is -1, the poll blocks indefinitely 如果是-1,则一直阻塞,直到至少一个描述符期待的事件发生
-
-
pollfd对应的events和revents取值解释
events revents 事件 描述 可作为输入 可作为输出 POLLIN 数据可读(包括普通数据&优先数据) 是 是 POLLOUT 数据可写(普通数据&优先数据) 是 是 POLLRDNORM 普通数据可读 是 是 POLLRDBAND 优先级带数据可读(linux不支持) 是 是 POLLPRI 高优先级数据可读,比如TCP带外数据 是 是 POLLWRNORM 普通数据可写 是 是 POLLWRBAND 优先级带数据可写 是 是 POLLRDHUP TCP连接被对端关闭,或者关闭了写操作,由GNU引入 是 是 POPPHUP 挂起 否 是 POLLERR 错误 否 是 POLLNVAL 文件描述符没有打开 否 是 -
可能的返回码
- 正常返回fds数组中revents不为0的文件描述符的个数
- 如果超时之前没有任何事件发生 则poll返回0
- 失败时 poll返回-1 errno设置如下: 不同os返回码可能不一致 可以man下
- EBADF 一个或多个结构体中指定的文件描述符无效
- EFAULT 指针指向的地址超出进程的地址空间。
- EINTR 请求的事件之前产生一个信号,调用可以重新发起
- EINVAL 参数超出PLIMIT_NOFILE值
- ENOMEM 可用内存不足,无法完成请求
不足及改进
- 相比select 没有了数量的限制 此为改进
- 每次poll fd数组都要经过用户态拷贝到内核态 性能还是会受影响
- 还是轮询机制 监控的fd数量如果太多 不论文件描述符是否就绪 开销随着监控数量增加而线性增大
代码
poll示例代码_转载整理加注释、简单优化 C
```c #includeIO多路复用—epoll
API原型
#include <sys/epoll.h>
int epoll_create(int size);
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout);
struct epoll_event {
__uint32_t events; /* Epoll events */
epoll_data_t data; /* User data variable */
};
events可以是以下几个宏的集合:
EPOLLIN :表示对应的文件描述符可以读(包括对端SOCKET正常关闭);
EPOLLOUT:表示对应的文件描述符可以写;
EPOLLPRI:表示对应的文件描述符有紧急的数据可读(这里应该表示有带外数据到来);
EPOLLERR:表示对应的文件描述符发生错误;
EPOLLHUP:表示对应的文件描述符被挂断;
EPOLLET: 将EPOLL设为边缘触发(Edge Triggered)模式,这是相对于水平触发(Level Triggered)来说的。
EPOLLONESHOT:只监听一次事件,当监听完这次事件之后,如果还需要继续监听这个socket的话,需要再次把这个socket加入到EPOLL队列里
-
epoll_create
- 创建一个epoll文件描述符,size是要告诉内核这个监听套接字的数量,创建好epoll句柄后,就会占用一个fd值,在linux系统以下目录/proc/pid/fd是可以看到的,所以epoll结束 好习惯也要close掉
-
epoll_ctl
- ctl就是control控制的缩写,是一个事件注册函数,epfd为epoll_create函数返回的epoll句柄
- 第二个参数op为操作类型 有以下三个
- EPOLL_CTL_ADD:注册新的fd到epfd中
- EPOLL_CTL_MOD:修改已经注册的fd的监听事件
- EPOLL_CTL_DEL:从epfd中删除一个fd
- 第三个参数fd为需要监听的套接字句柄
- 第四个参数是告诉内核针对fd要监听什么事件 events枚举上面有列出来
-
epoll_wait
- 类似select、poll调用名字也有wait,就是等待事件产生
- 第一个参数epfd为epoll_create返回的epoll句柄
- 第二个参数events用来从内核得到事件集合,内核会将就绪的描述符及发生的事件写到这个列表中
- 第三个参数是告知内核 这个列表有多大,不能大于调用epoll_create(int size)传入的size
- 第四个参数超时时间 单位毫秒 :
- timeout>0 如果没有套接字就绪 内核最多等到timeout毫秒
- timeout=0 如果没有套接字就绪 内核直接返回 不阻塞
- timeout=-1 会一直阻塞 直到有套接字就绪
-
epoll两者工作模式
-
LT(level trigger) 水平触发模式
epoll_wait检测到fd事件发生并将此事件通知应用程序,如果应用程序不立即处理,下次调用epoll_wait会再次告知应用程序
-
ET(edge trigger) 边缘触发模式
当epoll_wait检测到描述符事件发生并将此事件通知应用程序,应用程序必须立即处理该事件。如果不处理,下次调用epoll_wait时,不会再次响应应用程序并通知此事件
- ET模式很大程度减少了epoll事件被重复触发的次数,相对于LT效率更高,在ET模式下,必须使用非阻塞套接字,以避免由于一个套接字阻塞读写导致整个处理多套接字的任务搞死。
-
改进、不足
- 相对于select没有数量限制
- 相对于select、poll 对于监控的描述符集合 不用每次都从用户态拷贝到内核态,只是在epoll_ctl添加的时候拷贝一次
- epoll_wait不是轮询机制 而是采用回调函数的机制 所以效率更高
- epoll目前只有linux有 是从linux内核2.6开始提出的 不过windows和Mac(bsd)也有类似的实现
代码
epoll示例代码 转载加注释 简单优化 C
```c #include为什么需要多进程多线程
-
本质原因cpu、内存IO、磁盘IO因为介质不同,工作效率天壤之别,cpu速度远远大于内存,内存速度又远远大于磁盘。所以这么一来最开始的计算使用者就发现,cpu太闲了,而cpu贵,实在是太浪费了,所以后面就想尽办法办法,让cpu忙起来 下面的是简单的发展历史
-
单任务时代
计算机只负责计算,不能直接写入指令和输出结果,程序员把程序写到纸上,然后穿孔称卡片,再把卡片输入到计算机,计算机计算结果打印出来,程序员最后拿到结果。这个时代的计算机cpu是很闲的,程序员干半天,计算机一会完事。
-
批处理
程序由卡片改为了磁带,这时候一次可以录入更多的程序,一次批处理的方式执行多个任务,但计算机同时还是只能干一件事情,进行IO的时候不能计算,进行计算的时候不能IO,而cpu干活又贼快,所以cpu整体还是很闲。
-
支持多道程序设计 多进程时代
出现了多进程,每个进程拥有自己独立的内存空间,不同进程之间互不干涉,因为cpu太快而且又贵,所以大家就轮着用,也就是cpu时间片的概念,不同的进程使用cpu由操作系统统一管理,争取公平的分配给每个进程所需要的cpu时间片,一个进程用一会cpu,操作系统就保存现场,同时把cpu转给其它进程(也就是进程切换),这个时代进程如果够多,cpu其实已经很忙了,因为一堆进程轮番上阵,无休止的车轮战。
-
多线程时代
因为进程切换比较消耗时间,现场保存和切换工作因为进程比较重所以比较消耗时间和资源,所以就来了多线程,线程更加轻量级,一个进程的多个线程间共享进程的内存空间,所以切换起来更快,当然cpu也就会更累。
因为多线程的出现,cpu变得更加繁忙。
-
多cpu 多线程
进入了多线程时代后,终于彻底可以把cpu搞死了,所以人们开始嫌弃cpu没有那么快了,所以就想着搞多个cpu,让多个cpu同时工作,这个时候其实才是真正的任务并行了,之前是多个任务不断的抢一个cpu,因为cpu太快了,所以基本没什么感觉,进入多核cpu后才真正的让多个任务并行了。
-
多cpu并发可能产生的问题
多个cpu缓存导致的可见性问题
-
还是因为cpu太快,内存磁盘太慢所以有了cpu缓存,所以cpu执行数据操作过层导致如下:
- 从磁盘加载数据到内存
- 从内存加载到cpu缓存
- 执行相关计算操作 更新cpu缓存
- 更新内存
- 更新磁盘
-
多核cpu,就有多个cpu缓存,而它们彼此不可见,每个cpu也是操作的自己独立的cpu缓存,这就必然产生不可见性,比如a=a+1
cpu1修改了对应的cpu缓存,而此时cpu2是不知道的,必须等缓存同步以后才知道。
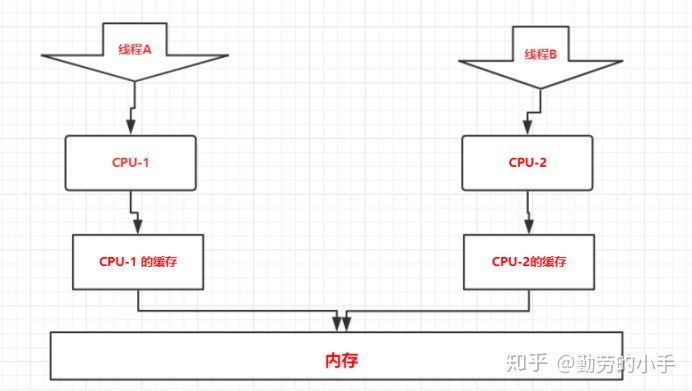
-
所以线程见如果操作共享资源要注意加锁,否则可能出现意想不到的结果
-
例子:2个线程 同时++一个变量10W次
cpu切换线程导致的原子性问题
-
原子性就是一个操作(多个相关子操作)在执行的过程中不能被打断,要么都执行,要么都不执行。
-
例子 int number=0;number=number+1;
number=number+1的指令可能如下:
指令1:CPU把number从内存拷贝到CPU缓存。
指令2:把number进行+1的操作。
指令3:把number回写到内存.
- 如果有2个线程都在执行上面的例子,cpu的执行流程可能如下:
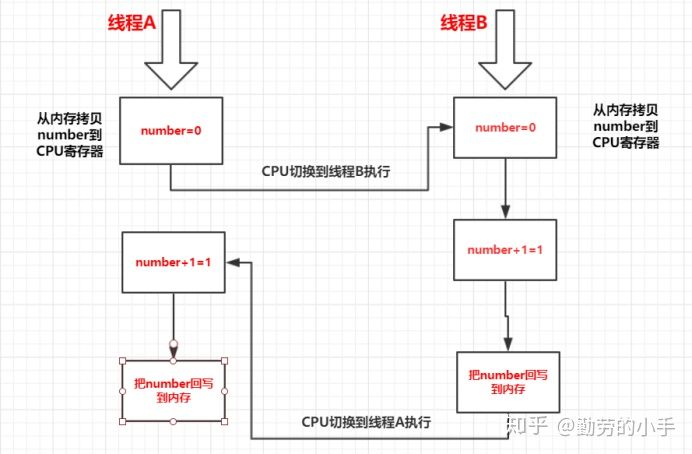
执行细节:
1、CPU先执行线程A的执行,把number=0拷贝到CUP寄存器。
2、然后CPU切换到线程B执行指令。
3、线程B 把number=0拷贝到CUP寄存器。
4、线程B 执行number=number+1 操作得到number=1。
5、线程B把number执行结果回写到缓存里面。
6、然后CPU切换到线程A执行指令。
7、线程A执行number=number+1 操作得到numbe=1。
8、线程A把number执行结果回写到缓存里面。
9、最后内存里面number的值为1。
编译器优化带来的指令重排序问题
-
编译器的有些优化会打乱执行本来人为理解的顺序
-
例子: 单例模式的double check,其实用了很长一段时间,直到内存reorder问题发现。
public class Singleton { private Singleton() {} private static Singleton sInstance; public static Singleton getInstance() { if (sInstance == null) { //第一次验证是否为null synchronized (Singleton.class) { //加锁 if (sInstance == null) { //第二次验证是否为null sInstance = new Singleton(); //创建对象 } } } return sInstance; } }Instance = new Singleton();这行代码时会分解成三个指令执行。
1、为对象分配一个内存空间。
2、在分配的内存空间实例化对象。
3、把Instance 引用地址指向内存空间
而且2 3的顺序可能发生变化,如果先执行3,然后另外一个线程抢到cpu 发现对象指针不为空,直接返回然后使用,而这个时候对象还没有完成初始化工作,是会出问题的。
c++11 多线程
创建线程
c++11 创建一个线程相对比较简单 大致步骤如下:
1. #include<thread>
2. 定义线程代码执行路径(线程就是可以单独执行代码的通道,要定义线程启动后要从哪个地方开始从上往下执行代码)
3. 在main主线程 创建一个thread对象(这个时候线程就自动生成并且运行了)
4. 主线程做一些线程管理工作(比如调用join函数阻塞等待某个线程,也可以调用detach函数 跟某个线程脱离关系,让init进程接管然后去后台运行)
线程代码执行入口的常见方式
-
普通的函数
//普通函数作为线程执行入口 void ordinaryFunc(){ cout<<"线程id:"<<std::this_thread::get_id()<<" is running"<<endl; sleep(1);//休眠一秒钟 cout<<"线程id:"<<std::this_thread::get_id()<<" is ready to exit "<<endl; } int main(){ cout<<" 主线程id:"<<std::this_thread::get_id()<<" is running"<<endl; thread t1(ordinaryFunc); t1.join();//main函数阻塞 等待子线程退出 cout<<" 主线程id:"<<std::this_thread::get_id()<<" is ready to return"<<endl; } -----输出 主线程id:0x11a916dc0 is running 线程id:0x700001438000 is running 线程id:0x700001438000 is ready to exit 主线程id:0x11a916dc0 is ready to exit -
函数对象(重载了()运算符的对象)
//函数对象作为线程执行入口 class FuncObj{ public: void operator()(){ cout<<"线程id:"<<std::this_thread::get_id()<<" is running"<<endl; sleep(1);//休眠一秒钟 cout<<"线程id:"<<std::this_thread::get_id()<<" is ready to exit "<<endl; } }; int main(){ cout<<" 主线程id:"<<std::this_thread::get_id()<<" is running"<<endl; thread t1( ( FuncObj() )); t1.join(); cout<<" 主线程id:"<<std::this_thread::get_id()<<" is ready to exit"<<endl; } -
类成员函数
//类成员函数作为线程执行入口 class ObjTest{ public: void run(){ cout<<"线程id:"<<std::this_thread::get_id()<<" is running"<<endl; sleep(1);//休眠一秒钟 cout<<"线程id:"<<std::this_thread::get_id()<<" is ready to exit "<<endl; } }; int main(){ cout<<" 主线程id:"<<std::this_thread::get_id()<<" is running"<<endl; ObjTest runtest; thread t1(&ObjTest::run,&runtest);//类成员函数作为线程执行入口要多传入一个对象的this指针 t1.join(); cout<<" 主线程id:"<<std::this_thread::get_id()<<" is ready to exit"<<endl; } -
lambda表达式
int main(){ cout<<" 主线程id:"<<std::this_thread::get_id()<<" is running"<<endl; auto lambdaThread=[]{ cout<<"线程id:"<<std::this_thread::get_id()<<" is running"<<endl; sleep(1);//休眠一秒钟 cout<<"线程id:"<<std::this_thread::get_id()<<" is ready to exit "<<endl; }; thread t1(lambdaThread); t1.join(); cout<<" 主线程id:"<<std::this_thread::get_id()<<" is ready to exit"<<endl; }
线程执行入口传递参数
- 创建线程会复制新的堆栈 参数统一都会复制,如果要传递引用 可以使用std::ref(),否则即使函数参数写的是引用,最后也不是真的引用。
- 线程之间如果使用的是同一个变量,要注意作用域问题,特别是detach后,很可能一个线程已经挂了,另外一个线程还在使用某个挂了的线程中的变量,就会差生奇怪的后果。
线程管理函数
-
join
主线程 执行了t1.join()后,主线程就会阻塞的等待子线程结束
-
detach
主线程执行了t1.detach()后,t1线程就跑到后台执行了 跟当前主线程就没有关系了,但如果主线程退出,那么进程也会退出,所有的线程也都会退出,并不是说detach后线程就真的常驻了,只是跟主线程脱离控制关系了。
锁(资源竞争)
-
互斥量
#include<mutex> std::mutex s1; s1.lock(); //加锁 doSomething();//处理 s1.unlock();//解锁 最简单的可以通过互斥量来解决问题。只有锁成功的线程 才能对共享资源做处理 否则就要等待 //如果不想显示的unlock的 或者担心忘记写unlock也可以用std::lock_guard代为管理 { std::mutex s1; std::lock_guard<std::mutex> lg(s1); //加锁 会在构造函数内部 调用s1的lock函数 //doSomething();//处理 }//退出这个大括号 lg对象会析构,析构的时候会调用s1的unlock函数 -
死锁问题
//死锁测试 class DeadLock{ public: void func1(){ for (int i=0;i<10000;++i){ m1.lock();// m2.lock(); cout<<"this is func1"<<endl; m2.unlock(); m1.unlock(); } } void func2(){ for (int i=0;i<10000;++i){ m2.lock(); m1.lock(); cout<<"this is func2"<<endl; m1.unlock(); m2.unlock(); } } private: std::mutex m1,m2; }; int main(){ cout<<" 主线程id:"<<std::this_thread::get_id()<<" is running"<<endl; DeadLock deadLockTest; thread t1(&DeadLock::func1,&deadLockTest); thread t2(&DeadLock::func2,&deadLockTest); t1.join(); t2.join(); cout<<" 主线程id:"<<std::this_thread::get_id()<<" is ready to exit"<<endl; } //----------大致死锁过程---------- //t1线程 执行func1函数 先锁了m1 准备去锁m2 //然后cpu切换到t2线程 //t2线程 先锁了m2 准备去锁m1 发现m1被锁了 等待 //cpu切换到t1线程 去锁m2 发现m2被锁了,等待 //2个线程一直等待下去 //不同线程之间加锁解锁顺序应该一致 避免死锁 -
std::lock() 一次锁多个互斥量 要么全部成功 要么全部失败 有原子性
std::mutex m1,m2; std::lock(m1,m2);//这里m1 m2要么同时锁成功 要么都不加锁 doSomething();// m1.lock(); m2.lock(); -
std::lock_guardstd::mutex l1(m1,std::adopt_lock)
加上adopt_lock标记,必须m1在之前已经被锁了 就不再锁了,但析构l1的时候还是会尝试unlock m1
-
std::unique_lock<>模版类
-
std::unique_lock<std::mutex> ul1(m2,std::try_to_lock);//尝试去拿锁 不会阻塞 if( ul1.owns_lock){ //加锁处理 }else{ //做其它事情 } -
std::unique_lock<std::mutex> ul1(m2,std::defer_lock);//没有加锁 ul1.lock(); //共享资源处理 ul1.unlock();//暂时解锁 //处理非共享资源 ul1.lock(); //处理共享资源 //ul1析构的时候 还是会unlock unique_lock相对更加灵活 但性能上也会有所损失 -
std::unique_lock<std::mutex> ul1(m2,std::defer_lock);//没有加锁 只是跟m2这个互斥量关联 if (ul1.try_lock()==true){//不会阻塞 //处理共享资源或者共享代码段 }else{ //没有加锁成功 做些别的事情 } std::unique_lock<std::mutex> ul2(std::move(ul1)); //转移所有权 相当于un1.release ul2根m2互斥量绑定 //ul1.release()//会放弃跟关联的互斥量之间的关系 那么就需要自己unlock了
-
-
加锁的粒度要控制得当,因为加锁会影响效率,锁的东西必须是涉及资源竞争的东西,不要在lock()和unlock()之间加太多不涉及共享的代码,会影响效率
-
std::recursive_mutex 递归的独占互斥量 可以lock多次 效率低
-
std::timed_mutex 抢锁 只不过有超时时间
std::timed_mutex timedMutex; std::chrono::milliseconds timeout(100); if( timedMutex.try_lock_for(timeout)){//等待100毫秒 如果抢到了锁就执行 //共享资源处理 timedMutex.unlock(); }else{ std::this_thread::sleep_for(timeout);//抢不到就超时 然后做些别的事情 } timedMutex.try_lock_until(futureTime);/到未来的时间如果还没抢到锁 则超时 否则继续处理
条件变量
是c++11的一个新的类,如果线程之间需要按照预定的先后顺序来执行,就可以使用条件变量这个类了。
假设一个线程生产数据,一个线程消费数据,如果没有数据,消费线程一直加锁解锁 非常消耗cpu资源,所以希望加锁后发现没有数据就等着,然后希望生产线程生产了数据就唤醒消费线程起来干活。比较常见的代码如下:
-
消费线程
std::mutex myMutex; std::condition_variable cv; vector<int> myVec; ///--------------以下为消费线程代码逻辑 while(true){ std::unique_lock<std::mutex> uniquelock1(myMutex); cv.wait(uniquelock1,[](){ return myVec.size()>0;} ); //加锁后如果没有数据 wait就释放锁 同时消费线程则阻塞在这里等待 //如果生产线程 唤醒了它,wait这里还要加锁 同时判断队列是否有数据,有数据并且加锁成功了 就会执行下面的消费逻辑 //------------消费数据--------------- } -
生产线程
std::mutex myMutex; std::condition_variable cv; vector<int> myVec; ///--------------以下为生产线程代码逻辑 while(true){ std::unique_lock<std::mutex> uniquelock1(myMutex); //--------生产数据-------------- myVec.push_back("xxx"); //-------生产完毕 先解锁 uniquelock1.unlock(); //-----然后唤醒消费线程干活 cv.notify_all();//cv.notify_one();//唤醒因为cv条件不满足等待的所有线程或者某一个线程 }
Std::async与std::future
-
std::async创建一个后台线程执行传递的任务,这个任务只要是callable object均可,然后返回一个std::future。future储存一个多线程共享的状态,当调用future.get时会阻塞直到绑定的task执行完毕
-
创建async的时候指定一个launch policy
- std::launch::async当返回的future失效前会强制执行task,即不调用future.get也会保证task的执行 创建新线程
- std::launch::deferred仅当调用future.get时才会执行task 不创建新线程 只是延迟执行
- 不指定策略,系统随机。
- Wait_for可以指定时间 然后获取状态(ready 成功执行完毕、timeout超时、deferred延期的尚未执行的)
- 只能get一次 如果想get多次 可以std::shared_future resultShare(result.share());//
-
这种方式可以很方便的获取线程的计算结果。
bool printThead(){
cout<<"线程id:"<<std::this_thread::get_id()<<" is running"<<endl;
sleep(5);//休眠一秒钟
cout<<"线程id:"<<std::this_thread::get_id()<<" is ready to exit "<<endl;
return true;
}
int main(){
cout<<" 主线程id:"<<std::this_thread::get_id()<<" is running"<<endl;
std::future<bool> result=std::async(printThead);
//std::future<bool> result=std::async(std::launch::deferred,printThead);//如果换成这行 主线程不等子线程 直接退出,子线程根本没有被执行 必须调用future的wait或者get才会被执行
cout<<" 主线程id:"<<std::this_thread::get_id()<<" is ready to exit"<<endl;//执行到这里主线程不会退出 printThead线程会被强制执行完成 默认策略是std::launch::async
}
-----输出-----
主线程id:0x113812dc0 is running
主线程id:0x113812dc0 is ready to exit
线程id:0x700006f48000 is running
...sleeping
线程id:0x700006f48000 is ready to exit
////main函数可以改为如下的:
int main(){
cout<<" 主线程id:"<<std::this_thread::get_id()<<" is running"<<endl;
std::future<bool> result=std::async(std::launch::deferred,printThead);
cout<<"调用future的get方法 开始启动printThread线程执行 同时主线程阻塞等待"<<endl;
cout<<"printThread线程执行结果为:"<<result.get()<<endl;//调用get方法 或者wait方法 主线程会阻塞等待 可以控制主线程执行时机
cout<<" 主线程id:"<<std::this_thread::get_id()<<" is ready to exit"<<endl;
}
std::packaged_task
bool printThead(){
cout<<"线程id:"<<std::this_thread::get_id()<<" is running"<<endl;
sleep(5);//休眠一秒钟
cout<<"线程id:"<<std::this_thread::get_id()<<" is ready to exit "<<endl;
return true;
}
int main(){
cout<<" 主线程id:"<<std::this_thread::get_id()<<" is running"<<endl;
std::packaged_task<bool()> myThreadPackage(printThead);//打包一个线程执行入口函数
thread t1(std::ref(myThreadPackage));//用打包好的入口函数 启动一个线程
t1.join();
// t1.detach();//detach也没有 调用了get就会阻塞等待的
std::future<bool> result=myThreadPackage.get_future();//得到返回结果
cout<<"printThread线程执行结果为:"<<result.get()<<endl;
cout<<" 主线程id:"<<std::this_thread::get_id()<<" is ready to exit"<<endl;
}
也可以包装任何可执行对象 下面是lambda表达式
std::packaged_task<bool()> myThreadPackage( [](){
.......
return true;
} );
std::packaged_task也可以直接调用 相当于函数调用 而不是启动线程
Std::promise 类模版 保存线程计算结果
void promiseTest(std::promise<int> &result,int num){
cout<<"线程promiseTest id:"<<std::this_thread::get_id()<<" is running"<<endl;
num+=5;
sleep(3);
result.set_value(num);
cout<<"线程promiseTest id:"<<std::this_thread::get_id()<<" is ready to exit "<<endl;
}
int main(){
cout<<" 主线程id:"<<std::this_thread::get_id()<<" is running"<<endl;
std::promise<int> myResult;
thread t1(promiseTest,std::ref(myResult),999);
t1.join();
std::future<int> result=myResult.get_future();
cout<<"线程运算结果为:"<<result.get()<<endl;
cout<<" 主线程id:"<<std::this_thread::get_id()<<" is ready to exit"<<endl;
}
-----输出结果-------
主线程id:0x107f2bdc0 is running
线程promiseTest id:0x70000a5e8000 is running
线程promiseTest id:0x70000a5e8000 is ready to exit
线程运算结果为:1004
主线程id:0x107f2bdc0 is ready to exit
原子操作std::atomic
int count=0;
void myTest(){
for (int i=0;i<100000;++i){
count++;
}
}
int main(){
thread t1(myTest);
thread t2(myTest);
t1.join();
t2.join();
}
//count++执行的时候是有多条执行的,又因为cpu缓存的不可见性,多核cpu可能出现最后不是200000的情况,也就是count++变成了不是原子操作,所谓原子操作就是这个操作要么因此全部执行完毕,要么一个也别执行。
//c++11增加了auomic模版 支持变量的原子操作,解决上述问题可以加互斥锁,但效率不高,可以使用原子操作类模版。
std::atomic<int> count=0;就不会出现问题了
但不是所有的操作都支持原子操作,比如count++没问题 但是 count=count+1就不支持了,使用时候要查看api说明
原子操作的赋值需要使用API特定的方法
Std::thread和std::async区别
- thread创建线程 如果资源紧张,可能创建失败,可能系统崩溃
- Std::async 可能还是在主线程进行的,更方便的
thread_local
thread_local定义的变量会在每个线程保存一份副本,而且互不干扰,在线程退出的时候自动摧毁
#include <iostream>
#include <thread>
#include <chrono>
thread_local int g_k = 0;
void func1(){
while (true){
++g_k;
}
}
void func2(){
while (true){
std::cout << "func2 thread ID is : " << std::this_thread::get_id() << std::endl;
std::cout << "func2 g_k = " << g_k << std::endl;
std::this_thread::sleep_for(std::chrono::milliseconds(1000));
}
}
int main(){
std::thread t1(func1);
std::thread t2(func2);
t1.join();
t2.join();
return 0;
}
----在func1()对g_k循环加1操作,在func2()每个1000毫秒输出一次g_k的值-----
func2 thread ID is : 15312
func2 g_k = 0
func2 thread ID is : 15312
func2 g_k = 0
func2 thread ID is : 15312
.....可以看出func2()中的g_k始终保持不变
经典IO模型实现
PPC、TPC
- Process Per Connection、Process Per Connection
整体思路总结及网搜图解
连接来时创建线程
-
主进程/主线程负责创建监听socket、启动监听
-
对每一个新的client 创建对应的处理进程/线程(完成read—>business process—>send)
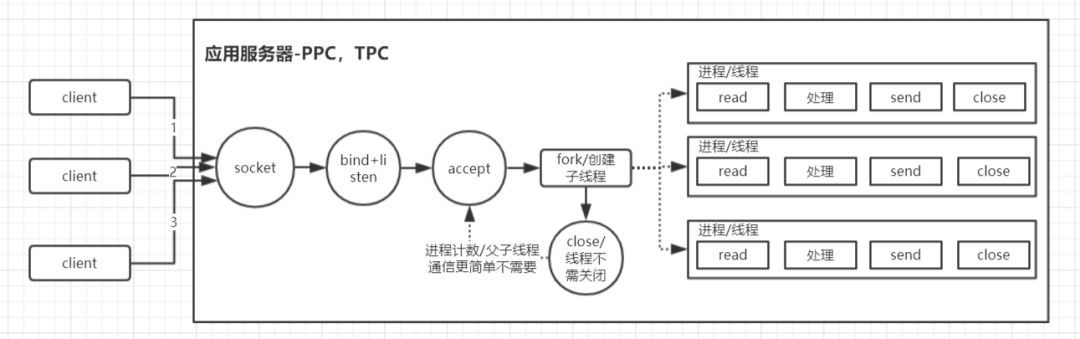
- 多进程需要close掉connfd,多线程不需要
预先创建号处理进程或者线程
-
提前创建好多个处理进程/线程
-
连接进来分配到预先创建好的处理进程/线程
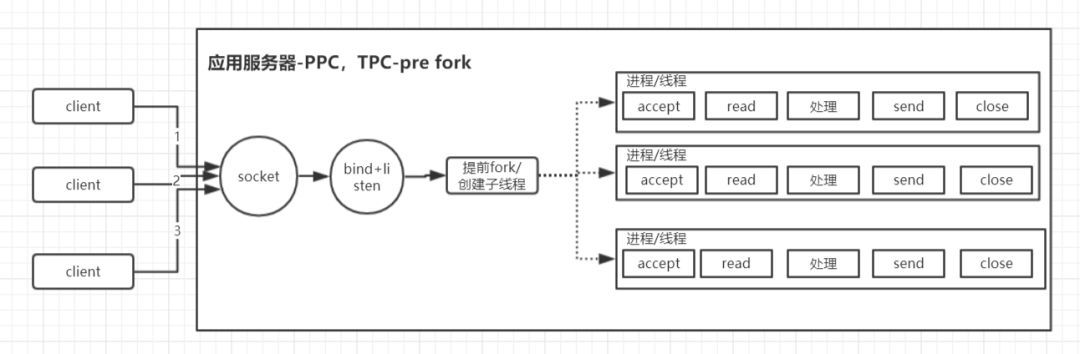
- 注意accept惊群(TCP_IP文章有讲解),解决方案(自己加accept_mutex锁、新一点的内核直接设置SO_REUSEPORT选项也是可以的内核会随机分配、….)
总结
- 优点:开发简单
- 缺点: 能给管理的连接数太少了,因为1个进程/线程 管理一个client套接字,而单机硬件条件限制(cpu、内存),所以同时管理的任务进程和线程是有限了(进程上下文切换太重,线程上千级别往往调度也是非常消耗时间了),所以想要高并发,ppc和tpc往往直接可以pass了。
Reactor思想
- 每个进程/线程通过IO多路复用技术,实现一个进程管理多个连接(共用一个阻塞对象 比如epollfd),应用只阻塞在epollfd上。当连接有数据可以处理的时候,通过系统调用让内核通知应用,然后进程/线程就从阻塞状态返回,进行业务处理。
- reactor处理思想大多也会有一个分发的思想存在(Dispatch),或则叫做拆分,也就将listen、accept、(send read)、business process分开,连接有数据可以处理,就分发给对应的handler处理,当然handler可以再拆出worker线程池等等。
- 往设计模式的Observe模式上理解,觉得也可以,当消息来了,就通知对应的进程/线程来处理(当然处理可以再次拆分)
- 讨论一些具体reactor模式实现的时候 里面的reactor一般是指负责监听和分发任务的角色
单Reactor+单线程处理(整体就一个线程)—redis
- redis就是一个典型的代表 下面是redis这个io模型的简单理解
整体思路:
- 线程创建socket启动监听 注册epoll
- epoll_wait等待客户端连接或者请求数据,拿到所有可以处理的fd,然后顺序遍历处理即可
- 如果是accept事件 就也注册到epoll
- 如果是connfd的请求 就读取请求—>处理—>回包
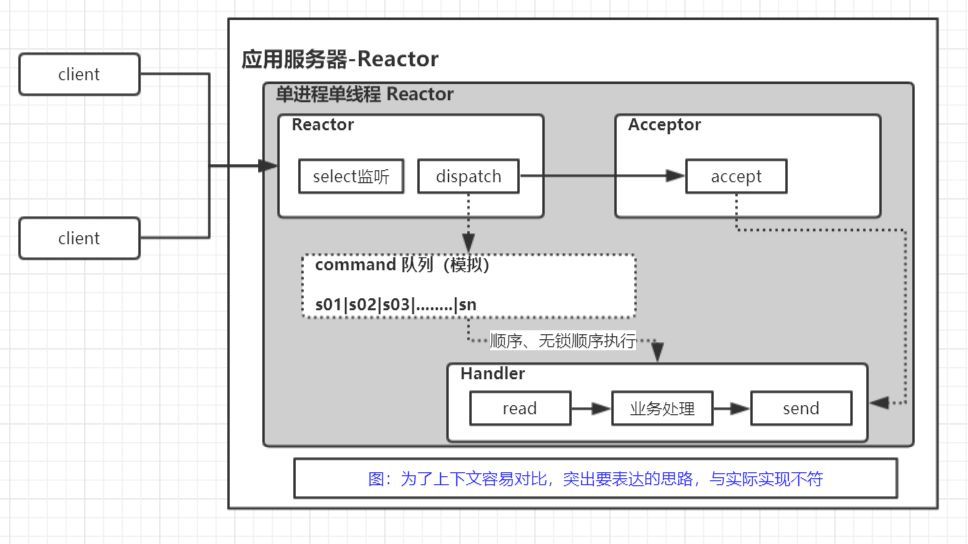
总结
-
优点:
- 模型简单,因为就一个线程 不用考虑并发 易开发,前面IO复用里面也有epoll的例子就是这个套路
- 适合短耗时业务(主业务处理逻辑不能太耗时,否则必然影响新连接的建议或者其他客户端的处理等待)
-
缺点:
- 性能会有瓶颈的 只有一个线程,无法利用多核cpu优势
- 因为是顺序处理请求,遇到长耗时的客户端请求,会延迟所有业务,这也是redis禁用耗时命令的原因
-
redis因为处理全在内存,单个请求处理非常快,所以适合这么处理,redis据说可以有10W的QPS吞吐量
单Reactor+单队列+业务进程/线程池—thrift0.10.0 nonblocking server
整体思路
-
主线程启动套接字监听 注册epoll ,有新的客户端连接就也注册到epoll
-
主线程epoll_wait 监控请求数据到达
-
主线程从connfd客户端套接字read请求数据 入请求队列
-
子线程从队列取出请求,进行business process,处理完成应答报文还是交由主线程send给client(clientfd在主线程hold)
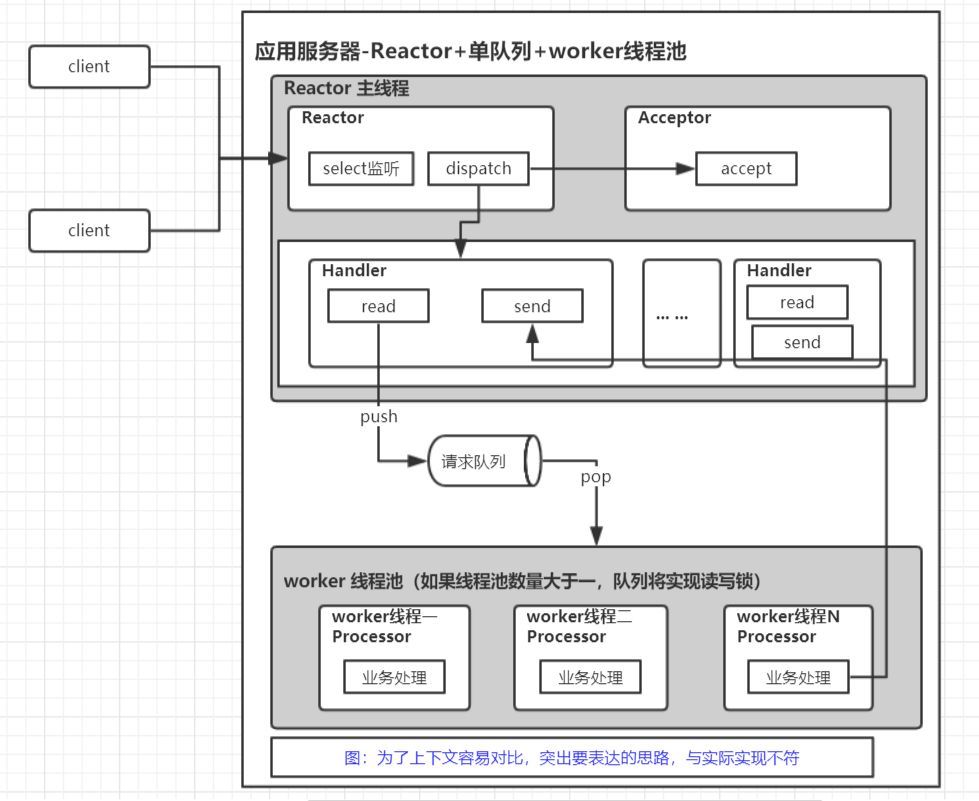
- 客户端套接字可以想象成一个队列 reactor将这个队列通过IO多路复用转换成了真正的业务请求数据队列。
- 业务线程池线程池,从队列中拿到数据进行真正的业务处理,将结果返回Handler。Handler收到响应结果后,send结果给客户端
- thrift0.10.0版本中 nonblocking server 使用这种模型
总结
- 优点:
- 多线程加快了真正业务数据处理的速度,这个是很有必要的,因为业务处理大都是比较耗时的(跟数据库打交道,远程RPC等等)
- 可能出现的缺点:
- 性能瓶颈很大可能出现在请求队列,因为主线程写和worker线程读是线程并发的,所以需要锁(多进程一样),要采用高性能的读写锁
单 Reactor+N队列+N线程—memcached
整体思路
- 主线程创建socket监听,同时accept,将accept的connfd采用Robin轮询的方式,扔给worker线程的队列
- 每个worker线程 采用IO多路复用技术从自己的队列中取出connfd,然后read—>business process–>send
- 每个worker线程的队列存放的是connfd,我理解这种其实也算是主从Reactor模式(master Reactor只accept,然后扔给多个subReactor)
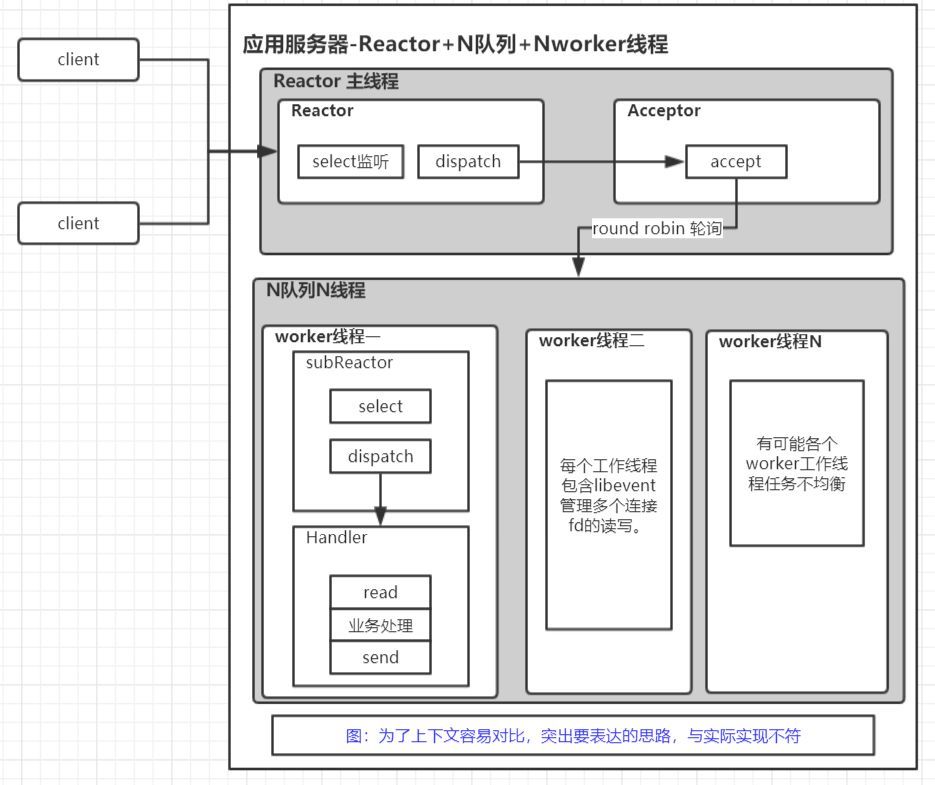
总结
- 优点:解决单队列的性能瓶颈,而且这里的多队列里面放的connfd,不存在上面多个线程同时读一个队列的锁竞争性能消耗
- 缺点:负载均衡可能导致有些队列很忙,有些队列很闲。比如队列1里面放的客户端,发送请求比较频繁,队列2里面放的客户端发送请求比较空闲。
主进程管理+多进程(accept+epoll_wait+处理)–nginx
整体思路
- 主进程先创建socket 启动监听,然后fork出一堆worker进程( 主进程不accept 只是管理多个worker进程 比如动态增加worker之类的)
- 每个worker进程 同时accept客户端连接(accept_mutex锁解决惊群问题),也就是每个worker自己抢客户,同时处理自己抢到的多个客户(epoll_wait)
- worker进程根据自身负载情况,选择性地不去accept新fd,从而实现负载均衡
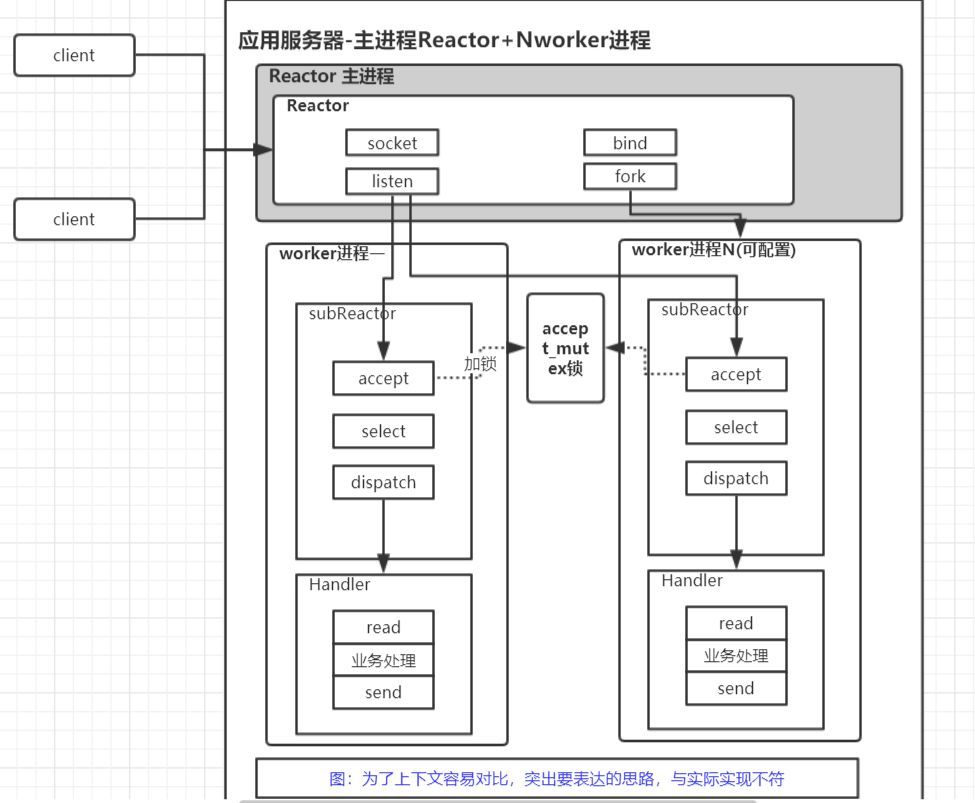
总结
- 优点:
- 某个worker进程挂掉不会影响整个服务
- 是由worker主动实现负载均衡的,这种负载均衡方式比由master来处理更简单
- 缺点:
- 多进程模型编程相对复杂,开发有一定难度
- 进程的开销是比线程更多的
主从多reactor多线程处理
整体思路:
- 主线程创建socket 启动监听,启动accept线程池(可以是1个或者多个) 这个线程池只负责accept客户端连接
- 每个accept线程 接收客户端连接之后 将connfd传给subReactor线程池中的某个线程
- subReactor线程池处理思路:
- 每个subReactor线程都会处理用epoll的方式监控多个connfd 负责处理read 和write事件 业务处理转发给worker线程池
- worker线程池处理:
- 接受请求处理事件 进行业务处理(计算、数据库处理之类的) 处理完成交给subReactor线程回报给client
总结:
这种模式理论上是性能最完美的模型,相对就是开发难度相对较大,可以使用一些现成的框架降低开发难度(Java.Netty、c++改造libevent等等)
unix编程API 转载
1.字节序函数
#include <netinet.h> uint16_t htons(uint16_t host16bitvalue); uint32_t htonl(uint32_t host32bitvalue); 返回:网络字节序值
uint16_t ntohs(uint16_t net16bitvalue); uint32_t ntohl(uint32_t net32bitvalue); 返回:主机字节序值
一个测试本机字节序的程序,可参见见unpv12e:intro/byteorder.c。
2.字节操作函数
#include <strings.h> void bzero(void *dest, size_t nbytes); void bcopy(const void *src, void *dest, size_t nbytes); int bcmp(const void *ptr1, const void *ptr2, size_t nbytes); 返回:0—相等,非0—不相等
#include <string.h> void *memset(void *dest, int c, size_t len); void *memcpy(void *dest, void *src, size_t nbytes); int memcmp(const void *ptr1, const void *ptr2, size_t nbytes); 返回:0—相同,>0或<0—不相同;进行比较操作时,假定两个不相等的字节均为无符号字符(unsigned char)。
3.地址转换函数
#include <arpa/inet.h> int inet_aton(const char *strptr, struct in_addr *addrptr); 返回:1—串有效,0—串有错。
in_addr_t inet_addr(const char *strptr); 返回:若成功,返回32为二进制的网络字节序地址;若有错,则返回INADDR_NONE。
char *inet_ntoa(struct in_addr inaddr); 返回:指向点分十进制数串的指针。
int inet_pton(int family, const char *strptr, void *addrptr); 返回:1—成功;0—输入不是有效的表达格式,-1—出错。
const char *inet_ntop(int family, const void *addrptr, char *strptr, size_t len); 返回:指向结果的指针—成功,NULL—失败。
说明:
- inet_aton函数的指针若为空,则函数仍然执行输入串的有效性检查,但不存储任何结果。
- inet_addr的缺陷:出错返回值INADDR_NONE等于255.255.255.255(IPv4的有限广播地址),所以该函数不能处理此地址。 尽量使用inet_aton,不使用inet_addr。
- inet_ntoa函数的执行结果放在静态内存中,是不可重入的。
- 参数family可以是AF_INET,也可以是AF_INET6,若参数family不被支持,则出错,errno置为EAFNOSUPPORT。
- 指针addrptr是结构指针。
- len指定目标的大小,避免缓冲区溢出。如果len太小,则返回一个空指针,errno置为ENOSPC。为有助于规定该大小,有如下定义: #include <netinet.h> #define INET_ADDRSTRLEN 16 /*fro IPv4 dotted-decimal */ #define INET6_ADDRSTRLEN 46 /*for IPv6 hex string */
- inet_ntop函数的参数strptr不能为空指针,成功时,此指针即是函数的返回值。
实现IPv4版本的inet_pton和inet_ntop的程序,参见:unpv12e:libfree/inet_pton_ipv4.c和libfree/inet_ntop_ipv4.c。
4.readn、writen和readline
函数原型如下: ssize_t readn(int filedes, void *buff, size_t nbytes); ssize-t writen(int filedes, void *buff, size_t nbytes); ssize_t readline(int filedes, void *buff, size_t maxlen); 返回:读写字节数,-1—出错。
实现程序见:unpv12e:lib/readn.c、lib/writen.c、lib/readline1.c和lib/readline.c。
5.测试描述符类型
#include <sys/stat.h> int isfdtype( int fd, int fdtype); 返回:1—是指定类型,0—不是指定类型,-1—出错。
要测试是否为套接口描述子,fdtype应设为S_IFSOCK。
该函数的一个实现程序,参见unpv12e:lib/isfdtype.c
6.socket函数
#include <sys/socket.h> int socket(int family, int type, int protocol); 返回:非负描述字—成功,-1—出错。
family指定协议族,有如下取值:
- AF_INET IPv4协议
- AF_INET6 IPv6协议
- AF_LOCAL Unix域协议
- AF_ROUTE 路由套接口
- AF_KEY 密钥套接口
type指定套接口类型:
- SOCK_STREAM 字节流套接口
- SOCK_DGRAM 数据报套接口
- SOCK_RAW 原始套接口
protocol一般设为0,除非用在原始套接口上。
并非所有family和type的组合都是有效的。
AF_LOCAL等于早期的AF_UNIX。
7.connect函数
#include <sys/socket.h> int connect(int sockfd, const struct sockaddr *servaddr, socklen_t addrlen); 返回:0—成功,-1—出错。
sockfd是socket函数返回的套接口描述字,servaddr和addrlen是指向服务器的套接口地址结构指针和结构大小。
在调用connect之前不必非得调用bind函数。
如果是TCP,则connect激发TCP的三路握手过程,在阻塞情况下,只有在连接建立成功或出错时该函数才返回, 出错情况:
- 没有收到SYN分节的响应,在规定时间内经过重发仍无效,则返回ETIMEDOUT;
- 如果对SYN分节的响应是RST,表示服务器在指定端口上没有相应的服务,返回ECONNREFUSED;
- 如果发出 SYN在中间路由器上引发一个目的地不可达ICMP错误,在规定时间内经过重发仍无效,则返回EHOSTUNREACH或ENETUNREACH错误。
注意:如果connect失败,则套接口将不能再使用,必须关闭,不能对此套接口再调用函数connect。
8.bind函数
#include <sys/socket.h> int bind(int sockfd, const struct sockaddr *maddr, socklen_t addrlen); 返回:0—成功,-1—出错。
进程可以把一个特定的IP地址捆绑到他的套接口上,但此IP地址必须是主机的一个接口。
对于IPv4,通配地址是INADDR_ANY,其值一般为0;使用方法如下: struct sockaddr_in servaddr; servaddr.sin_addr.s_addr = htonl(INADDR_ANY);
对于IPv6,方法如下: struct sockaddr_in6 serv; serv.sin6_addr = in6addr_any; (系统分配变量in6addr_any并将其初始化为常值IN6ADDR_ANY_INIT。)
如果让内核选择临时端口,注意的是bind并不返回所选的断口值,要得到一个端口,必须使用getsockname函数。
bind失败的常见错误是EADDRINUSE(地址已使用)。
9.listen函数
#include <sys/socket.h> int listen(int sockfd, int backlog); 返回:0—成功,-1—出错。
listen把未连接的套接口转化为被动套接口,指示内核应接受指向此套接口的连接请求。第二个参数规定了内核为此套接口排队的最大连接数。
参数backlog曾经规定为监听套接口上的未完成连接队列和已完成连接队列总和的最大值,但各个系统的定义方法都不尽相同;历史上常把backlog置为5,但对于繁忙的服务器是不够的;backlog的设置没有一个通用的方法,依情况而定,但不要设为0。
10.accept函数
#include <sys/socket.h> int accept(int sockfd, struct sockaddr *cliaddr, socklen_t *addrlen); 返回:非负描述字—OK,-1—出错。
accept从已完成连接队列头返回下一个连接,若已完成连接队列为空,则进程睡眠(套接口为阻塞方式时)。
参数cliaddr和addrlen返回连接对方的协议地址,其中addrlen是值-结果参数,调用前addrlen所指的整数值要置为cliaddr所指的套接口结构的长度,返回时由内核修改。
accept成功执行后,返回一个连接套接口描述字。
如果对客户的协议地址没有兴趣,可以把cliaddr和addrlen置为空指针。
11.close函数
#include <unistd.h> int close(int sockfd); 返回:0—OK,-1—出错。
TCP套接口的close缺省功能是将套接口做上“已关闭”标记,并立即返回到进程。这个套接口描述字不能再为进程使用,但TCP将试着发送已排队待发的任何数据,然后按正常的TCP连接终止序列进行操作。
close把描述字的访问计数减1,当访问计数仍大于0时,close并不会引发TCP的四分组连接终止序列。若确实要发一个FIN,可以用函数shutdown。
12.getsockname和getpeername
#include <sys/socket.h> int getsockname(int sockfd, struct sockaddr *localaddr, socklen_t *addrlen); int getpeername(int sockfd, struct sockaddr *peeraddr, socklen_t *addrlen); 返回:0—OK,-1—出错。
getsockname函数返回与套接口关联的本地协议地址。
getpeername函数返回与套接口关联的远程协议地址。
addrlen是值-结果参数。
使用场合:
- 在不调用bind的TCP客户,当connect成功返回后,getsockname返回分配给此连接的本地IP地址和本地端口号;
- 在以端口号为0调用bind后,使用getsockname返回内核分配的本地端口号;
- getsockname可用来获取某套接口的地址族;
- 在捆绑了通配IP地址的TCP服务器上,当连接建立后,可以使用getsockname获得分配给此连接的本地IP地址;
- 当一个服务器调用exec启动后,他获得客户身份的唯一途径是调用getpeername函数。
13.select函数
#include <sys/select.h> #include <sys/time.h> int select(int maxfdp1, fd_set *readset, fd_set *writeset, fd_set *exceptset, const struct timeval *timeout); 返回:准备好描述字的正数目,0—超时,-1—出错。
结构timeval的定义: struct timeval { long tv_sec; /* seconds / long tv_usec; / microseconds */ };
timeout取值的三种情况:
- 永远等下去:仅在有一个描述字准备好I/O时才返回,设置timeout为空指针;
- 等待固定时间:在有一个描述字准备好I/O时返回,但不超过由timeout参数所指定的秒数和微秒数;
- 根本不等待:检查描述字后立即返回,将timeout中的秒数和微秒数都设置为0。
在等待过程中,若进程捕获了信号并从信号处理程序返回,等待一般被中断,为了可移植性,必须准备好select返回EINTR错误。
timeout的值在返回时并不会被select修改(const标志)。
readset、writeset、exceptset指定我们要让内核测试读、写和异常条件所需的描述字。
当前支持的异常条件有两个:
- 套接口带外数据的到达;
- 控制状态信息的存在,可从一个已置为分组方式的伪终端主端读到。
描述字集的使用: 数据类型:fd_set; void FD_ZERO(fd_set *fdset); void FD_SET(int fd, fd_set *fdset); void FD_CLR(int fd, fd_set *fdset); void FD_ISSET(int fd, fd_set *fdset);
参数maxfdp1指定被测试的描述字个数,它的值是要被测试的最大描述字加1。描述字0,1,2,…,maxfdp1-1都被测试。
readset、writeset、exceptset是值-结果参数,select修改三者所指的描述字集。所以,每次调用select时,我们都要将所有描述字集中关心的位置为1。
套接口准备好读的条件:
- 套接口接收缓冲区中的数据字节数大于等于套接口接收缓冲区低潮限度的当前值。对这样的套接口的读操作将不阻塞并返回一个大于0的值(即准备好读入的数据量)。可以用套接口选项SO_RCVLOWAT来设置低潮限度,对于TCP和UDP,缺省值为1;
- 连接的读这一半关闭(接收了FIN的TCP连接)。对这样的套接口读操作将不阻塞并且返回0(即文件结束符);
- 套接口是一个监听套接口且已完成的连接数为非0;
- 有一个套接口错误待处理。对这样的套接口读操作将不阻塞且返回一个错误,errno设置成明确的错误条件。这些待处理错误也可以通过指定套接口选项SO_ERROR调用getsockopt来取得并清除。
套接口准备好写的条件:
- 套接口发送缓冲区中的可用字节数大于等于套接口发送缓冲区低潮限度的当前值,且或者(1)套接口已连接,或者(2)套接口不要求连接(如UDP套接口)。可以用套接口选项SO_SNDLOWAT来设置此低潮限度,对于TCP和UDP,缺省值为2048;
- 连接的写这一半关闭。对这样的套接口写将产生信号SIGPIPE;
- 有一个套接口错误待处理。对这样的套接口写操作将不阻塞且返回一个错误,errno设置成明确的错误条件。这些待处理错误也可以通过指定套接口选项SO_ERROR调用getsockopt来取得并清除。
如果一个套接口存在带外数据或者仍处于带外标记,那它有异常条件待处理。
一个套接口出错时,它被select标记为既可读又可写。
14.shutdown函数
#include <sys/socket.h> int shutdown(int sockfd, int howto); 返回:0—成功,-1—失败。
函数的行为依赖于参数howto的值:
- SHUT_RD:关闭连接的读这一半,不再接收套接口中的数据且留在套接口缓冲区中的数据都作废。进程不能再对套接口任何读函数。调用此函数后,由TCP套接口接收的任何数据都被确认,但数据本身被扔掉。
- SHUT_WR:关闭连接的写这一半,在TCP场合下,这称为半关闭。当前留在套接口发送缓冲区中的数据都被发送,后跟正常的TCP连接终止序列。此半关闭不管套接口描述字的访问计数是否大于0。进程不能再执行对套接口的任何写函数。
SHUT_RDWR:连接的读这一半和写这一半都关闭。这等效于调用shutdown两次:第一次调用时用SHUT_RD,第二次调用时用SHUT_WR。
15.pselect函数
#include <sys/select.h> #include <signal.h> #include <time.h> int pselect(int maxfdp1, fd_set *readset, fd_set *writeset, fd_set *exceptset, const struct timespec *timeout, const sigset_t *sigmask); 返回:准备好描述字的个数,0—超时,-1—出错。
pselect是Posix.1g发明的。相对select的变化:
- pselect使用结构timespec: struct timespec { time_t tv_sec; /* seconds / long tv_nsec; / nanoseconds */ }; 新结构中的tv_nsec规定纳秒数。
- pselect增加了第六个参数:指向信号掩码的指针。允许程序禁止递交某些信号。
16.poll函数
#include <poll.h> int poll(struct pollfd *fdarray, unsigned long nfds, int timeout); 返回:准备好描述字的个数,0—超时,-1—出错。
第一个参数是指向一个结构数组的第一个元素的指针,每个数组元素都是一个pollfd结构: struct pollfd { int fd; /* descriptor to check / short events; / events of interest on fd / short revents; / events that occurred on fd */ };
要测试的条件由成员events规定,函数在相应的revents成员中返回描述字的状态(一个描述字有两个变量:一个为调用值,一个为结果)。
第二个参数指定数组中元素的个数。
第三个参数timeout指定函数返回前等待多长时间,单位是毫秒。可能值如下:
- INFTIM,永远等待;
- 0,立即返回,不阻塞;
- >0,等待指定数目的毫秒数。
标志的范围:
| 常量 | 能作为events的输入吗? | 能作为revents的结果吗? | 解释 |
|---|---|---|---|
| POLLIN | yes | yes | 普通或优先级带数据可读 |
| POLLRDNORM | yes | yes | 普通数据可读 |
| POLLRDBAND | yes | yes | 优先级带数据可读 |
| POLLPRI | yes | yes | 高优先级数据可读 |
| POLLOUT | yes | yes | 普通或优先级带数据可写 |
| POLLWRNORM | yes | yes | 普通数据可写 |
| POLLWRBAND | yes | yes | 优先级带数据可写 |
| POLLERR | yes | 发生错误 | |
| POLLHUP | yes | 发生挂起 | |
| POLLNVAL | yes | 描述字不是一个打开的文件 |
图可分为三部分:处理输入的四个常值;处理输出的三个常值;处理错误的三个常值。
poll识别三个类别的数据:普通(normal)、优先级带(priority band)、高优先级(high priority)。术语来自流的概念。
返回条件:
- 所有正规TCP数据和UDP数据都被认为是普通数据;
- TCP的带外数据被认为是优先级带数据;
- 当TCP连接的读这一半关闭时(如接收了一个FIN),这也认为是普通数据,且后续的读操作将返回0;
- TCP连接存在错误既可以认为是普通数据,也可以认为是错误(POLLERR)。无论哪种情况,后续的读操作将返回-1,并将errno置为适当的值,这就处理了诸如接收到RST或超时等条件;
- 在监听套接口上新连接的可用性既可认为是普通数据,也可以认为是优先级带数据,大多数实现都将其作为普通数据考虑。
- 如果不关心某个特定的描述字,可将其pollfd结构的fd成员置为一个负值,这样就可以忽略成员events,且返回时将成员revents的值置为0。
poll没有select存在的最大描述字数目问题。但可移植性select要好于poll。
17.getsockopt和setsockopt
#include <sys/socket.h> int getsockopt(int sockfd, int level, int optname, void *optval, socklen_t *optlen); int setsockopt(int sockfd, int level, int optname, void *optval, socklen_t *optlen); 返回:0—OK,-1—出错。
sockfd必须是一个打开的套接口描述字;level(级别)指定系统中解释选项的代码:普通套接口代码或特定于协议的代码);optval是一个指向变量的指针;此变量的大小由最后一个参数决定。
对于某些套接口选项,什么时候进行设置或获取是有差别的。下面的套接口选项是由TCP已连接套接口从监听套接口继承来的:
- SO_DEBUG;
- SO_DONTROUTE;
- SO_KEEPALIVE;
- SO_LINGER;
- SO_OOBINLINE;
- SO_RCVBUF;
- SO_SNDBUF。
如果想在三路握手完成时确保这些套接口选项中的某一个是给已连接套接口设置的,我们必须先给监听套接口设置此选项。
18.套接口选项列表
| level | Optname | get | set | 说明 | 标志 | 数据类型 |
|---|---|---|---|---|---|---|
| SOL_SOCKET | SO_BROADCAST | y | y | 允许发送广播数据报 | y | int |
| SO_DEBUG | y | y | 使能调试跟踪 | y | int | |
| SO_DONTROUTE | y | y | 旁路路由表查询 | y | int | |
| SO_ERROR | y | 获取待处理错误并消除 | int | |||
| SO_KEEPALIVE | y | y | 周期性测试连接是否存活 | y | int | |
| SO_LINGER | y | y | 若有数据待发送则延迟关闭 | linger{} | ||
| SO_OOBINLINE | y | y | 让接收到的带外数据继续在线存放 | y | int | |
| SO_RCVBUF | y | y | 接收缓冲区大小 | int | ||
| SO_SNDBUF | y | y | 发送缓冲区大小 | int | ||
| SO_RCVLOWAT | y | y | 接收缓冲区低潮限度 | int | ||
| SO_SNDLOWAT | y | y | 发送缓冲区低潮限度 | int | ||
| SO_RCVTIMEO | y | y | 接收超时 | timeval{} | ||
| SO_SNDTIMEO | y | y | 发送超时 | timeval{} | ||
| SO_REUSEADDR | y | y | 允许重用本地地址 | y | int | |
| SO_REUSEPORT | y | y | 允许重用本地地址 | y | int | |
| SO_TYPE | y | 取得套接口类型 | int | |||
| SO_USELOOPBACK | y | y | 路由套接口取得所发送数据的拷贝 | y | int | |
| IPPROTO_IP | IP_HDRINCL | y | y | IP头部包括数据 | y | int |
| IP_OPTIONS | y | y | IP头部选项 | 见后面说明 | ||
| IP_RECVDSTADDR | y | y | 返回目的IP地址 | y | int | |
| IP_RECVIF | y | y | 返回接收到的接口索引 | y | int | |
| IP_TOS | y | y | 服务类型和优先权 | int | ||
| IP_TTL | y | y | 存活时间 | int | ||
| IP_MULTICAST_IF | y | y | 指定外出接口 | in_addr{} | ||
| IP_MULTICAST_TTL | y | y | 指定外出TTL | u_char | ||
| IP_MULTICAST_LOOP | y | y | 指定是否回馈 | u_char | ||
| IP_ADD_MEMBERSHIP | y | 加入多播组 | ip_mreq{} | |||
| IP_DROP_MEMBERSHIP | y | 离开多播组 | ip_mreq{} | |||
| IPPROTO_ICMPV6 | ICMP6_FILTER | y | y | 指定传递的ICMPv6消息类型 | icmp6_filter{} | |
| IPPROTO_IPV6 | IPV6_ADDRFORM | y | y | 改变套接口的地址结构 | int | |
| IPV6_CHECKSUM | y | y | 原始套接口的校验和字段偏移 | int | ||
| IPV6_DSTOPTS | y | y | 接收目标选项 | y | int | |
| IPV6_HOPLIMIT | y | y | 接收单播跳限 | y | int | |
| IPV6_HOPOPTS | y | y | 接收步跳选项 | y | int | |
| IPV6_NEXTHOP | y | y | 指定下一跳地址 | y | sockaddr{} | |
| IPV6_PKTINFO | y | y | 接收分组信息 | y | int | |
| IPV6_PKTOPTIONS | y | y | 指定分组选项 | 见后面说明 | ||
| IPV6_RTHDR | y | y | 接收原路径 | y | int | |
| IPV6_UNICAST_HOPS | y | y | 缺省单播跳限 | int | ||
| IPV6_MULTICAST_IF | y | y | 指定外出接口 | in6_addr{} | ||
| IPV6_MULTICAST_HOPS | y | y | 指定外出跳限 | u_int | ||
| IPV6_MULTICAST_LOOP | y | y | 指定是否回馈 | y | u_int | |
| IPV6_ADD_MEMBERSHIP | y | 加入多播组 | ipv6_mreq{} | |||
| IPV6_DROP_MEMBERSHIP | y | 离开多播组 | ipv6_mreq{} | |||
| IPPROTO_TCP | TCP_KEEPALIVE | y | y | 控测对方是否存活前连接闲置秒数 | int | |
| TCP_MAXRT | y | y | TCP最大重传时间 | int | ||
| TCP_MAXSEG | y | y | TCP最大分节大小 | int | ||
| TCP_NODELAY | y | y | 禁止Nagle算法 | y | int | |
| TCP_STDURG | y | y | 紧急指针的解释 | y | int |
详细说明:
SO_BROADCAST
使能或禁止进程发送广播消息的能力。只有数据报套接口支持广播,并且还必须在支持广播消息的网络上(如以太网、令牌环网等)。
如果目的地址是广播地址但此选项未设,则返回EACCES错误。
SO_DEBUG
仅仅TCP支持。当打开此选项时,内核对TCP在此套接口所发送和接收的所有分组跟踪详细信息。这些信息保存在内核的环形缓冲区内,可由程序trpt进行检查。
SO_DONTROUTE
此选项规定发出的分组将旁路底层协议的正常路由机制。
该选项经常由路由守护进程(routed和gated)用来旁路路由表(路由表不正确的情况下),强制一个分组从某个特定接口发出。
SO_ERROR
当套接口上发生错误时,源自Berkeley的内核中的协议模块将此套接口的名为so_error的变量设为标准的UNIX Exxx值中的一个,它称为此套接口的待处理错误(pending error)。内核可立即以以下两种方式通知进程:
- 如果进程阻塞于次套接口的select调用,则无论是检查可读条件还是可写条件,select都返回并设置其中一个或所有两个条件。
- 如果进程使用信号驱动I/O模型,则给进程或进程组生成信号SIGIO。
进程然后可以通过获取SO_ERROR套接口选项来得到so_error的值。由getsockopt返回的整数值就是此套接口的待处理错误。so_error随后由内核复位为0。
当进程调用read且没有数据返回时,如果so_error为非0值,则read返回-1且errno设为so_error的值,接着so_error的值被复位为0。如果此套接口上有数据在排队,则read返回那些数据而不是返回错误条件。
如果进程调用write时so_error为非0值,则write返回-1且errno设为so_error的值,随后so_error也被复位。
SO_KEEPALIVE
打开此选项后,如果2小时内在此套接口上没有任何数据交换,TCP就会自动给对方发一个保持存活探测分节,结果如下:
- 对方以期望的ACK响应,则一切正常,应用程序得不到通知;
- 对方以RST响应,套接口的待处理错误被置为ECONNRESET,套接口本身则被关闭;
- 对方对探测分节无任何响应,经过重试都没有任何响应,套接口的待处理错误被置为ETIMEOUT,套接口本身被关闭;若接收到一个ICMP错误作为某个探测分节的响应,则返回相应错误。
此选项一般由服务器使用。服务器使用它是为了检测出半开连接并终止他们。
SO_LINGER
此选项指定函数close对面向连接的协议如何操作(如TCP)。缺省close操作是立即返回,如果有数据残留在套接口缓冲区中则系统将试着将这些数据发送给对方。
SO_LINGER选项用来改变此缺省设置。使用如下结构: struct linger { int l_onoff; /* 0 = off, nozero = on / int l_linger; / linger time */ };
有下列三种情况:
- l_onoff为0,则该选项关闭,l_linger的值被忽略,等于缺省情况,close立即返回;
- l_onoff为非0,l_linger为0,则套接口关闭时TCP夭折连接,TCP将丢弃保留在套接口发送缓冲区中的任何数据并发送一个RST给对方,而不是通常的四分组终止序列,这避免了TIME_WAIT状态;
- l_onoff 为非0,l_linger为非0,当套接口关闭时内核将拖延一段时间(由l_linger决定)。如果套接口缓冲区中仍残留数据,进程将处于睡眠状态,直到(a)所有数据发送完且被对方确认,之后进行正常的终止序列(描述字访问计数为0)或(b)延迟时间到。此种情况下,应用程序检查close的返回值是非常重要的,如果在数据发送完并被确认前时间到,close将返回EWOULDBLOCK错误且套接口发送缓冲区中的任何数据都丢失。close的成功返回仅告诉我们发送的数据(和FIN)已由对方TCP确认,它并不能告诉我们对方应用进程是否已读了数据。如果套接口设为非阻塞的,它将不等待close完成。
l_linger的单位依赖于实现,4.4BSD假设其单位是时钟滴答(百分之一秒),但Posix.1g规定单位为秒。
让客户知道服务器已经读其数据的一个方法时:调用shutdown(SHUT_WR)而不是调用close,并等待对方close连接的本地(服务器)端。
SO_OOBINLINE
此选项打开时,带外数据将被保留在正常的输入队列中(即在线存放)。当发生这种情况时,接收函数的MSG_OOB标志不能用来读带外数据。
SO_RCVBUF和SO_SNDBUF
每个套接口都有一个发送缓冲区和一个接收缓冲区,使用这两个套接口选项可以改变缺省缓冲区大小。
当设置TCP套接口接收缓冲区的大小时,函数调用顺序是很重要的,因为TCP的窗口规模选项是在建立连接时用SYN与对方互换得到的。对于客户,SO_RCVBUF选项必须在connect之前设置;对于服务器,SO_RCVBUF选项必须在listen前设置。
TCP套接口缓冲区的大小至少是连接的MSS的三倍,而必须是连接的MSS的偶数倍。
SO_RCVLOWAT和SO_SNDLOWAT
每个套接口有一个接收低潮限度和一个发送低潮限度,他们由函数select使用。这两个选项可以修改他们。
接收低潮限度是让select返回“可读”而在套接口接收缓冲区中必须有的数据量,对于一个TCP或UDP套接口,此值缺省为1。发送低潮限度是让select返回“可写”而在套接口发送缓冲区中必须有的可用空间,对于TCP套接口,此值常为2048。
SO_RCVTIMEO和SO_SNDTIMEO
使用这两个选项可以给套接口设置一个接收和发送超时。通过设置参数的值为0秒和0微秒来禁止超时。缺省时两个超时都是禁止的。
接收超时影响5个输入函数:read、readv、recv、recvfrom和recvmsg;发送超时影响5个输出函数:write、writev、send、sendto和sendmsg。
SO_REUSEADDR和SO_REUSEPORT
SO_REUSEADDR提供如下四个功能:
- SO_REUSEADDR允许启动一个监听服务器并捆绑其众所周知端口,即使以前建立的将此端口用做他们的本地端口的连接仍存在。这通常是重启监听服务器时出现,若不设置此选项,则bind时将出错。
- SO_REUSEADDR允许在同一端口上启动同一服务器的多个实例,只要每个实例捆绑一个不同的本地IP地址即可。对于TCP,我们根本不可能启动捆绑相同IP地址和相同端口号的多个服务器。
- SO_REUSEADDR允许单个进程捆绑同一端口到多个套接口上,只要每个捆绑指定不同的本地IP地址即可。这一般不用于TCP服务器。
- SO_REUSEADDR允许完全重复的捆绑:当一个IP地址和端口绑定到某个套接口上时,还允许此IP地址和端口捆绑到另一个套接口上。一般来说,这个特性仅在支持多播的系统上才有,而且只对UDP套接口而言(TCP不支持多播)。
SO_REUSEPORT选项有如下语义:
- 此选项允许完全重复捆绑,但仅在想捆绑相同IP地址和端口的套接口都指定了此套接口选项才性。
- 如果被捆绑的IP地址是一个多播地址,则SO_REUSEADDR和SO_REUSEPORT等效。
使用这两个套接口选项的建议:
- 在所有TCP服务器中,在调用bind之前设置SO_REUSEADDR套接口选项;
- 当编写一个同一时刻在同一主机上可运行多次的多播应用程序时,设置SO_REUSEADDR选项,并将本组的多播地址作为本地IP地址捆绑。
SO_TYPE
该选项返回套接口的类型,返回的整数值是一个诸如SOCK_STREAM或SOCK_DGRAM这样的值。
SO_USELOOPBACK
该选项仅用于路由域(AF_ROUTE)的套接口,它对这些套接口的缺省设置为打开(这是唯一一个缺省为打开而不是关闭的SO_xxx套接口选项)。当此套接口打开时,套接口接收在其上发送的任何数据的一个拷贝。
禁止这些回馈拷贝的另一个方法是shutdown,第二个参数应设为SHUT_RD。
IP_HDRINCL
如果一个原始套接口设置该选项,则我们必须为所有发送到此原始套接口上的数据报构造自己的IP头部。
IP_OPTIONS
设置此选项允许我们在IPv4头部中设置IP选项。这要求掌握IP头部中IP选项的格式信息。
IP_RECVDSTADDR
该选项导致所接收到的UDP数据报的目的IP地址由函数recvmsg作为辅助数据返回。
IP_RECVIF
该选项导致所接收到的UDP数据报的接口索引由函数recvmsg作为辅助数据返回。
IP_TOS
该选项使我们可以给TCP或UDP套接口在IP头部中设置服务类型字段。如果我们给此选项调用getsockopt,则放到外出IP数据报头部的TOS字段中的当前值将返回(缺省为0)。还没有办法从接收到的IP数据报中取此值。
可以将TOS设置为如下的值:
- IPTOS_LOWDELAY:最小化延迟
- IPTOS_THROUGHPUT:最大化吞吐量
- IPTOS_RELIABILITY:最大化可靠性
- IPTOS_LOWCOST:最小化成本
IP_TTL
用次选项,可以设置和获取系统用于某个给定套接口的缺省TTL值(存活时间字段)。与TOS一样,没有办法从接收到的数据报中得到此值。
ICMP6_FILTER
可获取和设置一个icmp6_filter结构,他指明256个可能的ICMPv6消息类型中哪一个传递给在原始套接口上的进程。
IPV6_ADDRFORM
允许套接口从IPv4转换到IPv6,反之亦可。
IPV6_CHECKSUM
指定用户数据中校验和所处位置的字节偏移。如果此值为非负,则内核将(1)给所有外出分组计算并存储校验和;(2)输入时检查所收到的分组的校验和,丢弃带有无效校验和的分组。此选项影响出ICMPv6原始套接口外的所有IPv6套接口。如果指定的值为-1(缺省值),内核在此原始套接口上将不给外出的分组计算并存储校验和,也不检查所收到的分组的校验和。
IPV6_DSTOPTS
设置此选项指明:任何接收到的IPv6目标选项都将由recvmsg作为辅助数据返回。此选项缺省为关闭。
IPV6_HOPLIMIT
设置此选项指明:接收到的跳限字段将由recvmsg作为辅助数据返回。
IPV6_HOPOPTS
设置此选项指明:任何接收到的步跳选项都将由recvmsg作为辅助数据返回。
IPV6_NEXTHOP
这不是一个套接口选项,而是一个可指定个sendmsg的辅助数据对象的类型。此对象以一个套接口地址结构指定某个数据报的下一跳地址。
IPV6_PKTINFO
设置此选项指明:下面关于接收到的IPv6数据报的两条信息将由recvmsg作为辅助数据返回:目的IPv6地址和到达接口索引。
IPV6_PKTOPTIONS
大多数IPv6套接口选项假设UDP套接口使用recvmsg和sendmsg所用的辅助数据在内核与应用进程间传递信息。TCP套接口使用IPV6_PKTOPTIONS来获取和存储这些值。
IPV6_RTHDR
设置此选项指明:接收到的IPv6路由头部将由recvmsg作为辅助数据返回。
IPV6_UNICAST_HOPS
类似于IPv4的IP_TTL,它的设置指定发送到套接口上的外出数据报的缺省跳限,而它的获取则返回内核将用于套接口的跳限值。为了从接收到的IPv6数据报中得到真实的跳限字段,要求使用IPV6_HOPLIMIT套接口选项。
TCP_KEEPALIVE
它指定TCP开始发送保持存活探测分节前以秒为单位的连接空闲时间。缺省值至少为7200秒,即2小时。该选项仅在SO_KEEPALIVE套接口选项打开时才有效。
TCP_MAXRT
它指定一旦TCP开始重传数据,在连接断开之前需经历的以秒为单位的时间总量。值0意味着使用系统缺省值,值-1意味着永远重传数据。
TCP_MAXSEG
允许获取或设置TCP连接的最大分节大小(MSS)。返回值是我们的TCP发送给另一端的最大数据量,他常常就是由另一端用SYN分节通告的MSS,除非我们的TCP选择使用一个比对方通告的MSS小的值。如果此选项在套接口连接之前取得,则返回值为未从另一端收到的MSS选项的情况下所用的缺省值。
TCP_NODELAY
如果设置,此选项禁止TCP的Nagle算法。缺省时,该算法是使能的。
Nagle算法的目的是减少WAN上小分组的数目。
Nagle算法常常与另一个TCP算法联合使用:延迟ACK(delayed ACK)算法。
解决多次写导致Nagle算法和延迟ACK算法负面影响的方法:
- 使用writev而不是多次write;
- 合并缓冲区,对此缓冲区使用一次write;
- 设置TCP_NODELAY选项,继续调用write多次,这是最不可取的解决方法。
TCP_STDURG
它影响对TCP紧急指针的解释。
19.处理套接口的fcntl函数
#include <fcntl.h> int fcntl(int fd, int cmd, … /* arg */); 返回:依赖于参数cmd—成功,-1—失败。
函数fcntl提供了如下关于网络编程的特性:
- 非阻塞I/O:通过用F_SETFL命令设置O_NONBLOCK文件状态标志来设置套接口为非阻塞型。
- 信号驱动I/O:用F_SETFL命令来设置O_ASYNC文件状态标志,这导致在套接口状态发生变化时内核生成信号SIGIO。
- F_SETOWN命令设置套接口属主(进程ID或进程组ID),由它来接收信号SIGIO和SIGURG。SIGIO在设置套接口为信号驱动I/O型时生成,SIGURG在新的带外数据到达套接口时生成。
- F_GETOWN命令返回套接口的当前属主。
注意事项:
- 设置某个文件状态标志时,先取得当前标志,与新标志路逻辑或后再设置标志。
- 信号SIGIO和SIGURG与其他信号不同之处在于,这两个信号只有在已使用命令F_SETOWN给套接口指派了属主后才会生成。F_SETOWN命令的整参数arg既可以是一个正整数,指明接收信号的进程ID,也可以是一个负整数,它的绝对值是接收信号的进程组ID。
- 当一个新的套接口由函数socket创建时,他没有属主,但是当一个新的套接口从一个监听套接口创建时,套接口属主便由已连接套接口从监听套接口继承而来。
20.gethostbyname函数
#include <netdb.h> struct hostent *gethostbyname(const char *hostname); 返回:非空指针—成功,空指针—出错,同时设置h_errno。
函数返回的非空指针指向的结构如下: struct hostent { char *h_name; /*规范主机名 */ char *h_aliases; / 别名列表 / int h_addrtype; / AF_INET or AF_INET6 / int h_length; / 地址长度 */ char *h_addr_list; / IPv4或IPv6地址结构列表 */ }; #define h_addr h_addr_list[0];
按照DNS的说法,gethostbyname执行一个对A记录的查询或对AAAA记录的查询,返回IPv4或IPv6地址。
h_addr的定义是为了兼容,在新代码中不应使用。
返回的h_name称为主机的规范(canonical)名字。当返回IPv6地址时,h_addrtype被设置为AF_INET6,成员h_length被设置为16。
gethostbyname的特殊之处在于:当发生错误时,他不设置errno,而是将全局整数h_errno设置为定义在头文件<netdb.h>中的下列常值中的一个:
- HOST_NOT_FOUND;
- TRY_AGAIN;
- NO_RECOVERY;
- NO_DATA(等同于NO_ADDRESS)。
有函数hstrerror(),它将h_errno的值作为唯一的参数,返回一个指向相应错误说明的const char *型指针。
DNS小常识:
DNS中的条目称为资源记录RR(resource record),仅有少数几类RR会影响我们的名字与地址转换:
- A:A记录将主机名映射为32位的IPv4地址;
- AAAA:“四A”记录将主机名映射为128位的IPv6地址;
- PTR:PTR记录(称为“指针记录”)将IP地址映射为主机名;
- MX:MX记录指定一主机作为某主机的“邮件交换器”。
- CNAME:CNAME代表“canonical name(规范名字)”,其常见的用法是为常用服务如ftp和www指派一个CNAME记录。
21.gethostbyname2函数
#include <netdb.h> struct hostent *gethostbyname2(const char *hostname, int family); 返回:非空指针—成功,空指针—出错,同时设置h_errno。
该函数允许指定地址族,其他与gethostbyname相似。
22.gethostbyaddr函数
#include <netdb.h> struct hostent *gethostbyaddr(const char *addr, size_t len, int family); 返回:非空指针—成功,空指针—出错,同时设置h_error。
函数根据一个二进制的IP地址并试图找出相应于此地址的主机名,我们关心的是规范主机名h_name。
参数addr不是char *类型,而是一个真正指向含有IPv4或IPv6地址的结构in_addr或in6_addr的指针;len是该结构的大小,对于IPv4是4,对于IPv6是16;family或为AF_INET或为AF_INET6。
按照DNS的说法,该函数查询PTR记录。
23.uname函数
#include <sys/utsname.h> int uname(struct utsname *name); 返回:非负值—成功,-1—失败。
返回当前主机的名字,存放在如下的结构里: #define UTS_NAMESIZE 16 #define UTS_NODESIZE 256 struct utsname { char sysname[UTS_NAMESIZE]; char nodename[UTS_NODESIZE]; char release[UTS_NAMESIZE]; char version[UTS_NAMESIZE]; char machine[UTS_NAMESIZE]; };
该函数经常与gethostbyname一起用来确定本机的IP地址:先调用uname获得主机名字,然后调用gethostbyname得到所有的IP地址。
获得本机IP地址的另一个方法是ioctl的命令SIOCGIFCONF。
24.gethostname函数
#include <unistd.h> int gethostname(char *name, size_t namelen); 返回:0—成功,-1—失败。
返回当前主机的名字。name是指向主机名存储位置的指针,namelen是此数组的大小,如果有空间,主机名以空字符结束。
主机名的最大大小通常是头文件<sys/param.h>定义的常值MAXHOSTNAMELEN。
25.getservbyname函数
#include <netdb.h> struct servent *getservbyname(const char *servname, const char *protoname); 返回:非空指针—成功,空指针—失败。
函数返回如下结构的指针: struct servent { char *s_name; char **s_aliases; int s_port; char *s_proto; };
服务名servname必须指定,如果还指定了协议(protoname为非空指针),则结果表项必须有匹配的记录。如果没有指定协议名而服务支持多个协议,则返回哪个端口是依赖于实现的。
结构中的端口号是以网络字节序返回的,所以在将它存储在套接口地址结构时,绝对不能调用htons。
26.getservbyport函数
#include <netdb.h> struct servent *getservbyport(int port, const char *protname); 返回:非空指针—成功,空指针—出错。
port必须为网络字节序。例如: sptr = getservbyport(htons(53), “udp”);
27.recv和send
#include <sys/socket.h> ssize_t recv(int sockfd, void *buf, size_t nbytes, int flags); ssize_t send(int sockfd, void *buf, size_t nbytes, int flags); 返回:成功返回读入或写出的字节数,出错返回-1。
前三个参数与read和write相同,参数flags的值或为0,或由以下的一个或多个常值逻辑或构成:
| flags | 描述 | recv | send |
|---|---|---|---|
| MSG_DONTROUTE | 不查路由表 | y | |
| MSG_DONTWAIT | 本操作不阻塞 | y | y |
| MSG_OOB | 发送或接收带外数据 | y | y |
| MSG_PEEK | 查看外来的消息 | y | |
| MSG_WAITALL | 等待所有数据 | y |
下面说明每个标志的作用:
- MSG_DONTROUTE:这个标志告诉内核目的主机在直接连接的本地网络上,不要查路由表。这是对提供这种特性的SO_DONTROUTE套接口选项的补充。该标志可以对单个输出操作提供这种特性,而套接口选项则针对某个套接口上的所有输出操作。
- MSG_DONTWAIT:这个标志将单个I/O操作设为非阻塞方式,而不需要在套接口上打开非阻塞标志,执行I/O操作,然后关闭阻塞标志。
- MSG_OOB:用send时,这个标志指明发送的是带外数据,用recv时,该标志指明要读的是带外数据而不是一般数据。
- MSG_PEEK:这个标志可以让我们查看可读的数据,在recv或recvfrom后系统不会将这些数据丢弃。
- MSG_WAITALL:由4.3BSD Reno引入,他告诉内核在没有读到请求的字节数之前不使读操作返回。如果系统支持这个标志,则可以去掉readn函数。即使设定了该标志,如果发生如下情况:(1)捕获了一个信号;(2)连接被终止;(3)在套接口上发生错误,这个函数返回的字节数仍会比请求的少。
28.readv和writev
#include <sys/uio.h> ssize_t readv(int filedes, const struct iovec *iov, int iovcnt); ssize_t writev(int filedes, const struct iovec *iov, int iovcnt); 返回:读到或写出的字节数,出错返回-1。
readv和writev可以让我们在一个函数调用中读或写多个缓冲区,这些操作被称为分散读和集中写。
iovec结构定义如下: struct iovec { void iov_base; / starting address of buffer / size_t iov_len; / size of buffer */ };
在具体的实现中对iovec结构数组的元素个数有限制,4.3BSD最多允许1024个,而Solaris2.5上限是16。Posix.1g要求定义一个常值IOV_MAX,而且它的值不小于16。
readv和writev可用于任何描述字。writev是一个原子操作,可以避免多次写引发的Nagle算法。
29.readmsg和writemsg
#include <sys/socket.h> ssize_t recvmsg(int sockfd, struct msghdr *msg, int flags); ssize_t sendmsg(int sockfd, struct msghdr *msg, int flags); 返回:成功时为读入或写出的字节数,出错时为-1。
这两个函数是最通用的套接口I/O函数,可以用recvmsg代替read、readv、recv和recvfrom,同样,各种输出函数都可以用sendmsg代替。
参数msghdr结构的定义如下: struct msghdr { void msg_name; / protocol address / socklen_t msg_namelen; / size of protocol address */ struct iovec msg_iov; / scatter/gather array / size_t msg_iovlen; / elements in msg_iov */ void msg_control; / ancillary data; must be aligned for a cmsghdr structure / socklen_t msg_controllen; / length of ancillary data / int msg_flags; / flags returned by recvmsg() */ };
该结构源自4.3BSD Reno,也是Posix.1g中所说明的,有些系统仍使用一种老的msghdr结构,此种结构中没有msg_flags成员,而且 msg_control和msg_controllen成员分别被叫做msg_accrights和msg_accrightslen。老系统中支持的唯一一种辅助数据形式是文件描述字(称为访问权限)的传递。
msg_name和msg_namelen成员用于未经连接的套接口,他们与 recvfrom和sendto的第五和第六个参数类似:msg_name指向一个套接口地址结构,如果不需要指明协议地址,msg_name应被设置为空指针,msg_namelen对sendmsg是一个值,而对recvmsg是一个值-结果参数。
msg_iov和msg_iovlen成员指明输入或输出的缓冲区数组。
msg_control和msg_controllen指明可选的辅助数据的位置和大小,msg_controllen对recvmsg是一个值-结果参数。
msg_flags只用于revmsg,调用recvmsg时,flags参数被拷贝到msg_flags成员,而且内核用这个值进行接收处理,接着它的值会根据recvmsg的结果而更新,sendmsg会忽略msg_flags成员,因为它在进行输出处理时使用flags参数。
内核检查的flags和返回的msg_flags如下表所示:
| 标志 | 在send flags、 sendto flags、 sendmsg flags中检查 | 在recv flags、 recvfrom flags、 recvmsg flags中检查 | 在recvmsg msg_flags 中返回 |
|---|---|---|---|
| MSG_DONTROUTE | y | ||
| MSG_DONTWAIT | y | y | |
| MSG_PEEK | y | ||
| MSG_WAITALL | y | ||
| MSG_EOR | y | y | |
| MSG_OOB | y | y | y |
| MSG_BCAST | y | ||
| MSG_MCAST | y | ||
| MSG_TRUNC | y | ||
| MSG_CTRUNC | y |
前四个标志只检查不返回,下两个标志既检查又返回,最后四个只返回。返回的六个标志含义如下:
- MSG_BCAST:当收到的数据报是一个链路层的广播或其目的IP地址为广播地址时,将返回此标志。
- MSG_MCAST:当收到的数据报是链路层的多播时,将返回该标志。
- MSG_TRUNC:这个标志在数据报被截断时返回。
- MSG_CTRUNC:这个标志在辅助数据被截断时返回。
- MSG_EOR:如果返回的数据不是一个逻辑记录的结尾,该标志被清位,反之则置位。TCP不使用这个标志,因为它是一种字节流协议。
- MSG_OOB:这个标志不是为TCP的带外数据返回的,它用于其他协议族(譬如OSI协议等)。
具体的实现可能会在msg_flags中返回一些输入的flags的标志,所以我们应该只检查那些感兴趣的标志的值。
30.socketpair函数
#include <sys/socket.h> int socketpair(int family, int type, int protocol, int sockfd[2]); 返回:成功返回0,出错返回-1。
family必须为AF_LOCAL,protocol必须为0,type可以是SOCK_STREAM或SOCK_DGRAM。新创建的两个套接口描述字作为sockfd[0]和sockfd[1]返回。
这两个描述字相互连接,没有名字,即没有涉及隐式bind。
以SOCK_STREAM作为type调用所得到的结果称为流管道(stream pipe)。这与一般的UNIX管道类似,但流管道是全双工的,两个描述字都是可读写的。
31.套接口ioctl函数
#include <unistd.h> int ioctl(int fd, int request, … /* void *arg */ ); 返回:成功返回0,出错返回-1。
第三个参数总是一个指针,但指针的类型依赖于request。
ioctl和网络有关的请求可分为如下6类:
| 类别 | request | 描述 | 数据类型 |
|---|---|---|---|
| 套接口 | SIOCATMARK | 在带外标志上吗 | int |
| SIOCSPGRP | 设置套接口的进程ID或进程组ID | int | |
| SIOCGPGRP | 获取套接口的进程ID或进程组ID | int | |
| 文件 | FIONBIO | 设置/清除非阻塞标志 | int |
| FIOASYNC | 设置/清除异步I/O标志 | int | |
| FIONREAD | 获取接收缓冲区中的字节数 | int | |
| FIOSETOWN | 设置文件的进程ID或进程组ID | int | |
| FIOGETOWN | 获取文件的进程ID或进程组ID | int | |
| 接口 | SIOCGIFCONF | 获取所有接口的列表 | struct ifconf |
| SIOCSIFADDR | 设置接口地址 | struct ifreq | |
| SIOCGIFADDR | 获取接口地址 | struct ifreq | |
| SIOCSIFFLAGS | 设置接口标志 | struct ifreq | |
| SIOCGIFFLAGS | 获取接口标志 | struct ifreq | |
| SIOCSIFDSTADDR | 设置点到点地址 | struct ifreq | |
| SIOCGIFDSTADDR | 获取点到点地址 | struct ifreq | |
| SIOCGIFBRDADDR | 获取广播地址 | struct ifreq | |
| SIOCSIFBRDADDR | 设置广播地址 | struct ifreq | |
| SIOCGIFNETMASK | 获取子网掩码 | struct ifreq | |
| SIOCSIFNETMASK | 设置子网掩码 | struct ifreq | |
| SIOCGIFMETRIC | 获取接口的测度(metric) | struct ifreq | |
| SIOCSIFMETRIC | 设置接口的测度(metric) | struct ifreq | |
| SIOCxxx | (有很多,依赖于实现) | ||
| ARP | SIOCSARP | 创建/修改ARP项 | struct arpreq |
| SIOCGARP | 获取ARP项 | struct arpreq | |
| SIOCDARP | 删除ARP项 | struct arpreq | |
| 路由 | SIOCADDRT | 增加路径 | struct rtentry |
| SIOCDELRT | 删除路径 | struct rtentry | |
| 流 | I_xxx |
(1)套接口操作
- SIOCATMARK:如果套接口的读指针当前在带外标志上,则通过第三个参数指向的整数返回一个非零值,否则返回零。Posix.1g用sockatmark代替了这种请求。
- SIOCGPGRP:通过第三个参数指向的整数返回为接收来自这个套接口的SIGIO或SIGURG信号而设置的进程ID或进程组ID。这和fcntl的F_GETOWN相同。
- SIOCSPGRP:用第三个参数指向的整数设置进程ID或进程组ID以接收这个套接口的SIGIO或SIGURG信号。这和fcntl的F_SETOWN相同。
(2)文件操作
- FIONBIO:套接口的非阻塞标志会根据第三个参数指向的值是否为零而清除或设置。等价于fcntl的F_SETFL设置/清除O_NONBLOCK标志。
- FIOASYNC:根据第三个参数指向的值是否为零决定清除或接收套接口上的异步I/O信号。等价于fcntl的F_SETFL设置和清除O_AYNC标志。
- FIONREAD:在第三个参数指向的整数中返回套接口接收缓冲区中当前的字节数。
- FIOSETOWN:在套接口上等价于SIOCSPGRP。
- FIOGETOWN:在套接口上等价于SIOCGPGRP。
(3)接口配置
SIOCGIFCONF:从内核中获取系统中配置的所有接口。它使用了结构ifconf,ifconf又使用了ifreq结构。
结构定义如下: struct ifconf { int ifc_len; /* size of buffer, value-result / union { caddr_t ifcu_buf; / input from user->kernel */ struct ifreq ifcu_req; / return from kernel->user */ }ifc_ifcu; }; #define ifc_buf ifc_ifcu.ifcu_buf #define ifc_req ifc_ifcu.ifcu_req #define IFNAMSIZ 16
struct ifreq { char ifr_name[IFNAMSIZ]; union { struct sockaddr ifru_addr; struct sockaddr ifru_dstaddr; struct sockaddr ifru_broadaddr; short ifru_flags; int ifru_metric; caddr_t ifru_data; }ifr_ifru; }; #define ifr_addr ifr_ifru.ifru_addr #define ifr_dstaddr ifr_ifru.ifru_dstaddr #define ifr_broadaddr ifr_ifru.broadaddr #define ifr_flags ifr_ifru.ifru_flags #define ifr_metric ifr_ifru.ifru_metric #define ifr_data ifr_ifru.ifru_data
在调用ioctl之前分配一个缓冲区和一个ifconf结构,然后初始化后者,iotctl的第三个参数指向ifconf结构。
一个实现获取所有接口的程序,可参见unpv12e:lib/get_ifi_info.c
(4)接口操作
- SIOCGIFCONF:从内核中获取系统中配置的所有接口。
(5)ARP高速缓存操作
(6)路由表操作
http://www.cnblogs.com/riky/archive/2006/11/24/570713.aspx
转自:http://blog.chinaunix.net/space.php?uid=20564848&do=blog&id=73226
进程间通信IPC Inter-Process Communication
信号Signal
什么是信号
- 信号在现实世界就是用来传递的某种信息的一种手段,比如一个眼神,一个声音、一个约定的手势等等
- 计算机世界信号是软件层次上对中断机制的一种模拟。
- 信号是异步的,进程不用做什么操作来等待信号到达,也不清楚信号什么时候能够到达,用来异步通知一个进程某种事情发生了,进程通过实现注册某些函数,来异步等待相应信号发生的时候做相应的处理。
信号的来源
- 硬件来源
- (比如我们按下了键盘上的某些键【Control+C之类的】 或者某些硬件出现了故障等等)
- 软件来源
- 通过kill, raise,alarm,setitimer,sigqueue,abort系统函数 向特定进程发送信号
- 一些非常运算操作 比如除以0等等
收到信号如何处理
- 忽略信号
- 也就是不做任何处理 SIGKILL、SIGSTOP不能忽略
- 捕捉信号,定义自己的信号处理函数,当信号来了,执行相应处理
- 执行缺省操作,不走上面2个步骤,默认就是这个,linux对每个信号都有默认操作
相关系统函数说明
-
kill函数
#include <sys/types.h> #include <signal.h> int kill(pid_t pid,int signo) 对指定的进程发送什么信息。 pid>0 进程 ID 为 pid 的进程; pid=0 同一个进程组的进程; pid<0 pid!=-1进程组 ID 为 -pid 的所有进程; pid=-1 除发送进程自身外,所有进程 ID 大于1的进程。 -
raise函数
#include <signal.h> int raise(int signo) 向进程本身发送信号,参数为即将发送的信号值。 调用成功返回 0;否则,返回 -1 -
sigqueue函数
#include <sys/types.h> #include <signal.h> int sigqueue(pid_t pid, int sig, const union sigval val) 调用成功返回 0;否则,返回 -1。 第一个参数是指定接收信号的进程 ID,第二个参数确定即将发送的信号,第三个参数是一个联合数据结构 union sigval,指定了信号传递的参数,sigqueue() 比 kill() 传递了更多的附加信息,但 sigqueue() 只能向一个进程发送信号,而不能发送信号给一个进程组 -
alarm函数
#include <unistd.h> unsigned int alarm(unsigned int seconds) 为 SIGALRM 信号而设,在指定的时间 seconds 秒后,将向进程本身发送 SIGALRM 信号,又称为闹钟时间。 进程调用 alarm 后,任何以前的 alarm() 调用都将无效。 如果参数 seconds 为零,那么进程内将不再包含任何闹钟时间。 返回值,如果调用 alarm 前,进程中已经设置了闹钟时间,则返回上一个闹钟时间的剩余时间,否则返回 0。 -
setitimer函数
#include <sys/time.h> int setitimer(int which, const struct itimerval *value, struct itimerval *ovalue)); 比 alarm功能强大,支持3种类型的定时器: ITIMER_REAL: 设定绝对时间;经过指定的时间后,内核将发送SIGALRM信号给本进程; ITIMER_VIRTUAL 设定程序执行时间;经过指定的时间后,内核将发送SIGVTALRM信号给本进程; ITIMER_PROF 设定进程执行以及内核因本进程而消耗的时间和,经过指定的时间后,内核将发送ITIMER_VIRTUAL信号给本进程; -
abort函数
#include <stdlib.h> void abort(void); 向进程发送 SIGABORT 信号,默认情况下进程会异常退出,当然可定义自己的信号处理函数。 即使 SIGABORT 被进程设置为阻塞信号,调用 abort() 后,SIGABORT 仍然能被进程接收。该函数无返回值。
如何注册信号处理
-
确定信号值及进程针对该信号值的动作之间的映射关系,即进程将要处理哪个信号;该信号被传递给进程时,将执行何种操作
-
signal函数
#include <signal.h> void (signal(int signum, void (handler))(int)))(int); -------或者-------- #include <signal.h> typedef void (*sighandler_t)(int); sighandler_t signal(int signum, sighandler_t handler)); 第一个参数指定信号的值,第二个参数指定针对前面信号值的处理,可以忽略该信号(参数设为 SIG_IGN); 可以采用系统默认方式处理信号(参数设为 SIG_DFL); 也可以自己实现处理方式(参数指定一个函数地址)。 如果 signal() 调用成功,返回最后一次为安装信号 signum 而调用signal() 时的 handler值;失败则返回 SIG_ERR。 -
sigaction函数
#include <signal.h> int sigaction(int signum,const struct sigaction *act,struct sigaction *oldact)); sigaction函数 用于改变进程接收到特定信号后的行为。 该函数的第一个参数为信号的值,可以为除SIGKILL及SIGSTOP外的任何一个特定有效的信号(为这两个信号定义自己的处理函数,将导致信号安装错误)。 第二个参数是指向结构 sigaction 的一个实例的指针,在结构sigaction 的实例中,指定了对特定信号的处理,可以为空,进程会以缺省方式对信号处理; 第三个参数 oldact 指向的对象用来保存原来对相应信号的处理,可指定 oldact 为 NULL。如果把第二、第三个参数都设为NULL,那么该函数可用于检查信号的有效性。 第二个参数最为重要,其中包含了对指定信号的处理、信号所传递的信息、信号处理函数执行过程中应屏蔽掉哪些函数等等。
缺点
- 能够传递的信息是有限的,不能传递更为复杂的信息。
文件 file
- 这种应该是最简单 最容易理解的一种通信方式 一个进程往文件写信息,另外一个进程读信息,也就完成了通信过程。
- 通信本身没有任何顺序控制,可能没有写完,另外一个进程就读到了,另外一个进程本身可能也能够写
- 可以通过信号来控制有序
- 文件通信没有访问规则
- 文件访问的速度是很慢的,所以一般不常用
管道 pipe/named pipe
-
pipe
- 半双工 数据流向是单一的,如果双方通信时 需要建立2个pipe
- 使用范围只能是父子进程/兄弟进程
- 在内存中的文件系统
- 一个进程写入输入到管道 可以被另外一端的进程读出,写入的内容每次都添加到管道缓冲区的尾部,相应的另外一端进程每次都从缓冲区的头部读取。
#include <unistd.h> int pipe(int fd[2]) 一端只能用于读,由描述字 fd[0] 表示,称其为管道读端 一端则只能用于写,由描述字 fd[1] 来表示,称其为管道写端 试图从管道写端读取数据,或者向管道读端写入数据都将导致错误发生 fd创建后 fd[0]/fd[1]就可以当作普通的文件描述符使用了 比如close read write等 -
Named pipe
- 可以在任意进程间使用来完成通信工作
- 会在文件系统创建一个真实存在的文件,但实际是将其映射到内存中的一个特殊区域 文件本身可以设置相应的权限控制
#include <sys/types.h> #include <sys/stat.h> int mkfifo(const char * pathname, mode_t mode) 该函数的第一个参数是一个普通的路径名,也就是创建后 FIFO 的名字。 第二个参数与打开普通文件的 open() 函数中的mode 参数相同。 如果 mkfifo 的第一个参数是一个已经存在的路径名时,会返回EEXIST 错误,所以一般典型的调用代码首先会检查是否返回该错误,如果确实返回该错误,那么只要调用打开 FIFO 的函数就可以了。一般文件的 I/O 函数都可以用于 FIFO,如 close、read、write 等等。 -
管道在进程间通信中使用的比较频繁,尤其是父子多进程间通信 用的非常多
共享内存 shm
什么是共享内存
-
顾名思义就是多个进程可以访问同一片内存空间,共享内存允许多个进程共享一个存储区,因为数据不用来回的复制,所以是是最快的IPC形式,这个共享内存是独立与 所有进程空间之外的。
-
进程对于共享内存的主要使用可能有以下几点
- 向内核提交申请 创建一个共享内存区域
- 申请使用一个已经存在的共享内存区域
- 申请释放某一个共享内存区域
-
可以通过mmap()映射普通文件(特殊情况下还可以采用匿名映射)机制实现,也可以通过系统V共享内存机制实现
-
应用接口和原理很好理解,但内部实现机制复杂,往往为了安全通信,要引入信号灯,锁等同步机制共同使用
创建及使用
-
mmap()映射一个普通文件实现共享内存
-
通过shm共享内存机制创建(每个共享内存区域对应特殊文件系统shm中的一个文件)
int shmget(key_t key, size_t size, int shmflg); //返回值是共享内存的标号shmid int shmid = shmget(key, 256, IPC_CREAT | IPC_EXCL | 0755); key_t 是一个 long 类型,是 IPC 资源外部约定的 key (关键)值,通过 key 值映射对应的唯一存在的某一个 IPC 资源 通过 key_t 的值就能够判断某一个对应的共享内存区域在哪,是否已经创建等等 一个 key 值只能映射一个共享内存区域,但同时还可以映射一个信号量,一个消息队列资源,于是就可以使用一个 key 值管理三种不同的资源 --------------------------------------------------------------------------- 共享内存的控制信息可以通过 shmctl() 方法获取,会保存在struct_shmid_ds 结构体中 int shmctl(int shmid, int cmd, struct shmid_ds *buf) cmd:看执行什么操作(1、获取共享内存信息;2、设置共享内存信息;3、删除共享内存)。 ----------------------------------------------------------------------------- void * shmat(int shmid, const void *shmaddr, int shmflg); 将这个内存区域映射到本进程的虚拟地址空间 int shmdt(const void *shmaddr); 取消共享内存映射
信号量semaphore
概念
- 不同进程间/同一进程的不同线程间的一种同步手段
- 为了解决访问共享资源时候的冲突问题
访问规则
sem:表示的是一种共享资源的个数,对共享资源的访问规则
1)用一种数量单位去标识某一种共享资源的个数。
2)当有进程需要访问对应的共享资源的时候,则需要先查看申请,根据当前资源对应的可用数量进行申请。
3)资源的管理者(也就是操作系统内核)就使用当前的资源个数减去要申请的资源的个数。如果结果 >=0 表示有可用资源,允许该进程的继续访问;否则表示资源不可用,通知进程(暂停或立即返回)。
4)资源数量的变化就表示资源的占用和释放。占用:使得可用资源减少;释放:使得可用资源增加。
相关API
//创建信号量集
int semid = semget(key_t key, int nsems, int semflg)
信号量 ID 事实上是信号量集合的ID,一个ID 对应的是一组信号量,此时就使用信号量ID 设置整个信号量集合
这个时候操作分两种:
(1)针对信号量集合中的一个信号量进行设置;信号量集合中的信号量是按照数组的方式被管理起来的,从而可以直接使用信号的数组下标来进行访问。
(2)针对整个信号量集和进行统一的设置
-----------------------------------------------------------------------------
int semctl(int semid, int semnum, int cmd, ...)
如果 cmd 是 GETALL、SETALL、GETVAL、SETVAL...的话,则需要提供第四个参数。第四个参数是一个共用体,这个共用体在程序中必须的自己定义(作用:初始化资源个数),定义格式如下:
union semun{
int val; /* Value for SETVAL */
struct semid_ds *buf; /* Buffer for IPC_STAT, IPC_SET */
unsigned short *array; /* Array for GETALL, SETALL */
struct seminfo *__buf; /* Buffer for IPC_INFO
(Linux-specific) */
};
-----------------------------------------------------------------------------
//semop()方法。(op:operator操作)
int semop(int semid, struct sembuf *sops, unsigned nsops);
第二个参数需要借助结构体 struct sembuf:
struct sembuf{
unsigned short sem_num; /* semaphore number 数组下标 */
short sem_op; /* semaphore operation */
short sem_flg; /* operation flags 默认0*/
};
通过下标直接对其信号量 sem_op 进行加减即可。
特点
-
如果有进程通过信号量申请共享资源,而且此时资源个数已经小于0,则此时对于该进程有两种可能性:等待资源,不等待。
-
如果此时进程选择等待资源,则操作系统内核会针对该信号量构建进程等待队列,将等待的进程加入到该队列之中。
-
如果此时有进程释放资源则会:
(1)、先将资源个数增加;
(2)、从等待队列中抽取第一个进程;
(3)、根据此时资源个数和第一个进程需要申请的资源个数进行比较,结果大于 0,则唤醒该进程;结果小于 0,则让该进程继续等待。
所以一般结合信号量的操作和共享内存使用来达到进程间的通信
消息队列 Message
概念
-
消息队列就是一个消息的链表。可以把消息看作一个记录,具有特定的格式以及特定的优先级
-
对消息队列有写权限的进程可以向中按照一定的规则添加新消息;对消息队列有读权限的进程则可以从消息队列中读走消息
-
消息队列是随内核持续的;克服了信号承载信息量少,管道只能承载无格式字节流以及缓冲区大小受限等缺点
-
消息队列是随内核持续的,只有在内核重起或者显示删除一个消息队列时,该消息队列才会真正被删除。因此系统中记录消息队列的数据结构(struct ipc_ids msg_ids)位于内核中,系统中的所有消息队列都可以在结构msg_ids中找到访问入口
结构
消息队列就是一个消息的链表。每个消息队列都有一个队列头,用结构struct msg_queue来描述。队列头中包含了该消息队列的大量信息,包括消息队列键值、用户ID、组ID、消息队列中消息数目等等,甚至记录了最近对消息队列读写进程的ID。读者可以访问这些信息,也可以设置其中的某些信息。
-
struct ipc_ids msg_ids是内核中记录消息队列的全局数据结构;struct msg_queue是每个消息队列的队列头
-
全局数据结构 struct ipc_ids msg_ids 可以访问到每个消息队列头的第一个成员:struct kern_ipc_perm
-
struct kern_ipc_perm 能够与具体的消息队列对应起来是因为在该结构中,有一个 key_t 类型成员 key,而 key 则唯一确定一个消息队列
struct kern_ipc_perm{ //内核中记录消息队列的全局数据结构msg_ids能够访问到该结构; key_t key; //该键值则唯一对应一个消息队列 uid_t uid; gid_t gid; uid_t cuid; gid_t cgid; mode_t mode; unsigned long seq; } -
管道中的数据没有分割为一个个独立单元 字节流上是连续的,但消息队列是数据分成了一个个独立的单元,每个独立单元称谓消息体,每一个消息体都是固定大小的存储区域,字节流上是不连续的
相关API
int msgget(key_t key, int msgflg); //创建消息队列
int msgsnd(int msqid, const void *msgp, size_t msgsz, int msgflg);//发送
在发送消息的时候,是在消息体结构体中指定,当前的消息发送到消息队列集合中的哪一个消息队列上
消息体结构体中就必须包含一个 type 值,type 值是long类型,而且还必须是结构体的第一个成员。而结构体中的其他成员都被认为是要发送的消息体数据
ssize_t msgrcv(int msqid, void *msgp, size_t msgsz, long msgtyp,int msgflg);//接收
无论是 msgsnd() 发送还是 msgrcv()接收时,只要操作系统内核发现新提供的 type 值对应的消息队列集合中的消息队列不存在,则立即为其创建该消息队列
注意事项
-
为了能够顺利的发送与接收,发送方与接收方需要约定规则
- 同样的消息体结构体;
- 发送方与接收方在发送和接收的数据块儿大小上要与消息结构体的具体数据部分保持一致, 否则将不会读出正确的数据。
-
如果结构体成员有指针 不会将指针指向空间中的数据发送 只是发送指针本身的值。
-
数组作为消息结构体成员是可以的 因为整个数组空间都在消息结构体中
Socket通信
- unix域套接字
- 其它网络套接字


...